背景
一个任务既可以是一个进程,也可以是一个线程。简而言之,它指的是一系列共同达到某一目的的操作。
操作系统任务切换过程有两种,一种是基于TSS(任务状态段)的切换,这种切换需要使用一个长跳转指令,需要很多的mov,而且不能进行指令流水(分解成微指令),造成执行起来很慢。执行过程如下:使用TR(描述符表寄存器)找到GDT(全局描述符表)中的新tss描述符,之后使用描述符切换到新的tss。
另外一种是基于krlstack的切换。
通过堆栈实现任务切换可能要更快,而且采用堆栈的切换还可以使用指令流水的并行优化技术,同时又使得 CPU 的设计变得简单。所以无论是 Linux 还是 Windows,进程/线程的切换都没有使用 Intel 提供的这种 TSS 切换手段,而都是通过堆栈实现的。
本次实践项目就是将 Linux 0.11 中采用的 TSS 切换部分去掉,取而代之的是基于堆栈的切换程序。具体的说,就是将 Linux 0.11 中的 switch_to 实现去掉,写成一段基于堆栈切换的代码。
实验报告
问题1
movl tss,%ecx
addl $4096,%ebx
movl %ebx,ESP0(%ecx)
(1)为什么要加 4096?
因为页表结构是这样的:不要误会了,页表大小4KB
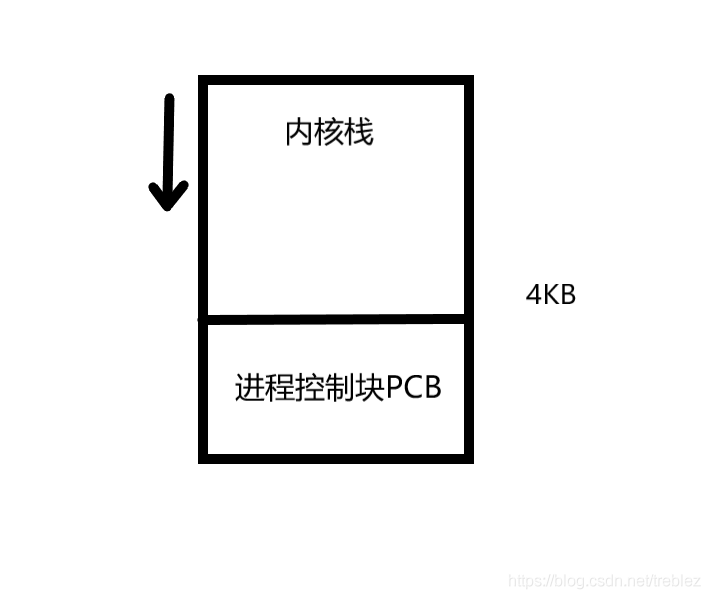
(2)为什么没有设置ss0?
SS0、SS1和SS2分别是0、1和2特权级的栈段选择子。
这里用不着特权级为0的内核段。
这个可以在《注释》或者《x86汇编语言 从实模式到保护模式》里面找到,课里面好像没讲啊。
问题2
*(--krnstack) = ebp;
*(--krnstack) = ecx;
*(--krnstack) = ebx;
*(--krnstack) = 0;
(1)子进程第一次执行时,eax=?为什么要等于这个数?哪里的工作让 eax 等于这样一个数?
这个eax,根据课程里面讲的内容是p_id,所以子进程eax=0;当使用copy_process()创建子进程的时候赋值的。
(2)这段代码中的 ebx 和 ecx 来自哪里,是什么含义,为什么要通过这些代码将其写到子进程的内核栈中?
父子的内核栈在初始化的时候完全一致,用户栈指向一个地方。通过copy_process()拷贝了参数。
(3)这段代码中的 ebp 来自哪里,是什么含义,为什么要做这样的设置?可以不设置吗?为什么?
ebp是用户栈地址,不设置就不能运行了。
问题3
为什么要在切换完 LDT 之后要重新设置 fs=0x17?而且为什么重设操作要出现在切换完 LDT 之后,出现在 LDT 之前又会怎么样?
cpu的段寄存器都存在两类值,一类是显式设置段描述符,另一类是隐式设置的段属性及段限长等值,这些值必须经由movl、lldt、lgdt等操作进行设置,而在设置了ldt后,要将fs显示设置一次才能保证段属性等值正确。
TSS 切换
在现在的 Linux 0.11 中,真正完成进程切换是依靠任务状态段(Task State Segment,简称 TSS)的切换来完成的。
具体的说,在设计“Intel 架构”(即 x86 系统结构)时,每个任务(进程或线程)都对应一个独立的 TSS,TSS 就是内存中的一个结构体,里面包含了几乎所有的 CPU 寄存器的映像。有一个任务寄存器(Task Register,简称 TR)指向当前进程对应的 TSS 结构体,所谓的 TSS 切换就将 CPU 中几乎所有的寄存器都复制到 TR 指向的那个 TSS 结构体中保存起来,同时找到一个目标 TSS,即要切换到的下一个进程对应的 TSS,将其中存放的寄存器映像“扣在” CPU 上,就完成了执行现场的切换,如下图所示。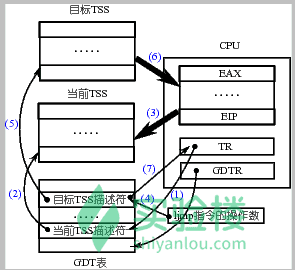
(1)首先用 TR 中存取的段选择符在 GDT 表中找到当前 TSS 的内存位置,由于 TSS 是一个段,所以需要用段表中的一个描述符来表示这个段,和在系统启动时论述的内核代码段是一样的,那个段用 GDT 中的某个表项来描述,还记得是哪项吗?是 8 对应的第 1 项。此处的 TSS 也是用 GDT 中的某个表项描述,而 TR 寄存器是用来表示这个段用 GDT 表中的哪一项来描述,所以 TR 和 CS、DS 等寄存器的功能是完全类似的。
(2)找到了当前的 TSS 段(就是一段内存区域)以后,将 CPU 中的寄存器映像存放到这段内存区域中,即拍了一个快照。
(3)存放了当前进程的执行现场以后,接下来要找到目标进程的现场,并将其扣在 CPU 上,找目标 TSS 段的方法也是一样的,因为找段都要从一个描述符表中找,描述 TSS 的描述符放在 GDT 表中,所以找目标 TSS 段也要靠 GDT 表,当然只要给出目标 TSS 段对应的描述符在 GDT 表中存放的位置——段选择子就可以了,仔细想想系统启动时那条著名的 jmpi 0, 8 指令,这个段选择子就放在 ljmp 的参数中,实际上就 jmpi 0, 8 中的 8。
(4)一旦将目标 TSS 中的全部寄存器映像扣在 CPU 上,就相当于切换到了目标进程的执行现场了,因为那里有目标进程停下时的 CS:EIP,所以此时就开始从目标进程停下时的那个 CS:EIP 处开始执行,现在目标进程就变成了当前进程,所以 TR 需要修改为目标 TSS 段在 GDT 表中的段描述符所在的位置,因为 TR 总是指向当前 TSS 段的段描述符所在的位置。
上面给出的这些工作都是一句长跳转指令 ljmp 段选择子:段内偏移,在段选择子指向的段描述符是 TSS 段时 CPU 解释执行的结果,所以基于 TSS 进行进程/线程切换的 switch_to 实际上就是一句 ljmp 指令:
#define switch_to(n) {
struct{long a,b;} tmp;
__asm__(
"movw %%dx,%1"
"ljmp %0" ::"m"(*&tmp.a), "m"(*&tmp.b), "d"(TSS(n)
)
}
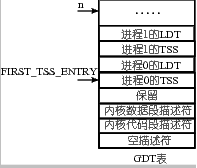
#define FIRST_TSS_ENTRY 4
#define TSS(n) (((unsigned long) n) << 4) + (FIRST_TSS_ENTRY << 3))
GDT 表的结构如下图所示,所以第一个 TSS 表项,即 0 号进程的 TSS 表项在第 4 个位置上,4<<3,即
4 * 8,相当于 TSS 在 GDT 表中开始的位置,TSS(n)找到的是进程 n 的 TSS 位置,所以还要再加上 n<<4,即n * 16,因为每个进程对应有 1 个 TSS 和 1 个 LDT,每个描述符的长度都是 8 个字节,所以是乘以 16,其中 LDT 的作用就是上面论述的那个映射表,关于这个表的详细论述要等到内存管理一章。TSS(n) = n * 16 + 4 * 8,得到就是进程 n(切换到的目标进程)的 TSS 选择子,将这个值放到 dx 寄存器中,并且又放置到结构体 tmp 中 32 位长整数 b 的前 16 位,现在 64 位 tmp 中的内容是前 32 位为空,这个 32 位数字是段内偏移,就是 jmpi 0, 8 中的 0;接下来的 16 位是n * 16 + 4 * 8,这个数字是段选择子,就是 jmpi 0, 8 中的 8,再接下来的 16 位也为空。所以 swith_to 的核心实际上就是 ljmp 空,n*16+4*8,现在和前面给出的基于 TSS 的进程切换联系在一起了。
本次实验的内容
虽然用一条指令就能完成任务切换,但这指令的执行时间却很长,这条 ljmp 指令在实现任务切换时大概需要 200 多个时钟周期。而通过堆栈实现任务切换可能要更快,而且采用堆栈的切换还可以使用指令流水的并行优化技术,同时又使得 CPU 的设计变得简单。所以无论是 Linux 还是 Windows,进程/线程的切换都没有使用 Intel 提供的这种 TSS 切换手段,而都是通过堆栈实现的。
本次实践项目就是将 Linux 0.11 中采用的 TSS 切换部分去掉,取而代之的是基于堆栈的切换程序。具体的说,就是将 Linux 0.11 中的 switch_to 实现去掉,写成一段基于堆栈切换的代码。
在现在的 Linux 0.11 中,真正完成进程切换是依靠任务状态段(Task State Segment,简称 TSS)的切换来完成的。具体的说,在设计“Intel 架构”(即 x86 系统结构)时,每个任务(进程或线程)都对应一个独立的 TSS,TSS 就是内存中的一个结构体,里面包含了几乎所有的 CPU 寄存器的映像。有一个任务寄存器(Task Register,简称 TR)指向当前进程对应的 TSS 结构体,所谓的 TSS 切换就将 CPU 中几乎所有的寄存器都复制到 TR 指向的那个 TSS 结构体中保存起来,同时找到一个目标 TSS,即要切换到的下一个进程对应的 TSS,将其中存放的寄存器映像“扣在”CPU 上,就完成了执行现场的切换。
要实现基于内核栈的任务切换,主要完成如下三件工作:
(1)重写 switch_to;
(2)将重写的 switch_to 和 schedule() 函数接在一起;
(3)修改现在的 fork()。
schedule 与 switch_to
目前 Linux 0.11 中工作的 schedule() 函数是首先找到下一个进程的数组位置 next,而这个 next 就是 GDT 中的 n,所以这个 next 是用来找到切换后目标 TSS 段的段描述符的,一旦获得了这个 next 值,直接调用上面剖析的那个宏展开 switch_to(next);就能完成如图 TSS 切换所示的切换了。
现在,我们不用 TSS 进行切换,而是采用切换内核栈的方式来完成进程切换,所以在新的 switch_to 中将用到当前进程的 PCB、目标进程的 PCB、当前进程的内核栈、目标进程的内核栈等信息。由于 Linux 0.11 进程的内核栈和该进程的 PCB 在同一页内存上(一块 4KB 大小的内存),其中 PCB 位于这页内存的低地址,栈位于这页内存的高地址;另外,由于当前进程的 PCB 是用一个全局变量 current 指向的,所以只要告诉新 switch_to()函数一个指向目标进程 PCB 的指针就可以了。同时还要将 next 也传递进去,虽然 TSS(next)不再需要了,但是 LDT(next)仍然是需要的,也就是说,现在每个进程不用有自己的 TSS 了,因为已经不采用 TSS 进程切换了,但是每个进程需要有自己的 LDT,地址分离地址还是必须要有的,而进程切换必然要涉及到 LDT 的切换。
综上所述,需要将目前的 schedule() 函数(在 kernal/sched.c 中)做稍许修改,即将下面的代码:
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i;
//......
switch_to(next);
copy
修改为:
if ((*p)->state == TASK_RUNNING && (*p)->counter > c)
c = (*p)->counter, next = i, pnext = *p;
//.......
switch_to(pnext, LDT(next));
实现 switch_to
删除头文件sched.h中的长跳转指令:"ljmp *%0
"
在system_call.s中添加系统调用函数switch_to():
.align 2
switch_to:
pushl %ebp
movl %esp,%ebp
pushl %ecx
pushl %ebc
pushl %eax
movl 8(%ebp),%ebx
cmpl %ebx,current
je 1f
// PCB的切换
movl %ebx,%eax
xchgl %eax,current
// TSS中内核栈指针的重写
movl tss,%ecx
addl $4096,%ebx
movl %ebx,ESP0(%ecx)
//切换内核栈
movl %esp,KERNEL_STACK(%eax)
movl 8(%ebp),%ebx
movl KERNEL_STACK(%ebx),%esp
//LDT的切换
movl 12(%ebp),%ecx
lldt %cx
movl $0x17,%ecx
mov %cx,%fs
movl $0x17,%ecx
mov %cx,%fs
cmpl %eax,last_task_used_math
jne 1f
clts
1: popl %eax
popl %ebx
popl %ecx
popl %ebp
ret
fs 是一个选择子,即 fs 是一个指向描述符表项的指针,这个描述符才是指向实际的用户态内存的指针,所以上一个进程和下一个进程的 fs 实际上都是 0x17,真正找到不同的用户态内存是因为两个进程查的 LDT 表不一样,所以这样重置一下 fs=0x17 有用吗,有什么用?要回答这个问题就需要对段寄存器有更深刻的认识,实际上段寄存器包含两个部分:显式部分和隐式部分,如下图给出实例所示,就是那个著名的 jmpi 0, 8,虽然我们的指令是让 cs=8,但在执行这条指令时,会在段表(GDT)中找到 8 对应的那个描述符表项,取出基地址和段限长,除了完成和 eip 的累加算出 PC 以外,还会将取出的基地址和段限长放在 cs 的隐藏部分,即图中的基地址 0 和段限长 7FF。为什么要这样做?下次执行 jmp 100 时,由于 cs 没有改过,仍然是 8,所以可以不再去查 GDT 表,而是直接用其隐藏部分中的基地址 0 和 100 累加直接得到 PC,增加了执行指令的效率。
更改fork.c
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p;
p->tss.ss0 = 0x10;
*(--krnstack) = ss & 0xffff;
*(--krnstack) = esp;
*(--krnstack) = eflags;
*(--krnstack) = cs & 0xffff;
*(--krnstack) = eip;
*(--krnstack) = (long) first_return_kernel;//处理switch_to返回的位置
*(--krnstack) = ebp;
*(--krnstack) = ecx;
*(--krnstack) = ebx;
*(--krnstack) = 0;
//把switch_to中要的东西存进去
p->kernelstack = krnstack;
...
写first_return_kernel在system_call.s中:
首先需要将first_return_kernel设置在全局可见:
.globl switch_to,first_return_kernel
然后需要在fork.c中添加该函数的声明:
extern void first_return_from_kernel(void);
最后就是将具体的函数实现放在system_call.s头文件里面:
first_return_kernel:
popl %edx
popl %edi
popl %esi
pop %gs
pop %fs
pop %es
pop %ds
iret