楔子
这次我们来说一下Python中的多线程,在上篇博客中我们说了Python的线程,我们说Python中的线程是对OS线程进行了一个封装,并提供了一个线程状态(PyThreadState)对象,来记录OS线程的一些状态信息。
那什么是多线程呢?首先线程是操作系统调度cpu工作的最小单元,同理进程则是操作系统资源分配的最小单元,线程是需要依赖于进程的,并且每一个进程只少有一个线程,这个线程我们称之为主线程。而主线程则可以创建子线程,一个进程中如果有多个线程去工作,我们就称之为多线程。
开发一个多线程应用程序是很常见的事情,很多语言都支持多线程,有的是原生支持,有的是通过库的支持。而Python毫无疑问也支持多线程,并且它是通过threading这个库的方式实现的。另外提到Python的多线程,会让人想到GIL(global interpreter lock)这个万恶之源,我们后面会详细介绍。目前我们知道Python中的多线程是不能利用多核的,因为Python虚拟机使用一个全局解释器锁(GIL)来控制线程对程序的执行,这个结果就使得无论你的cpu有多少核,但是同时被线程调度的cpu只有一个。不过底层是怎么做的呢?我们下面就来分析一下。
GIL与线程调度
首先我们来分析一下为什么会有GIL这个东西存在?看两行代码:
import dis
dis.dis("del name")
"""
1 0 DELETE_NAME 0 (name)
2 LOAD_CONST 0 (None)
4 RETURN_VALUE
"""
当我们使用del删除一个变量的时候,对应的指令是DELETE_NAME,这个指令对应的源码中可以自己去查看。总之这条指令做的事情就是通过宏 Py_DECREF 减少一个对象的引用计数,并且判断减少之后其引用计数是否为0,如果为0就进行回收。伪代码如下:
--obj->ob_refcnt
if (obj -> ob_refcnt == 0){
销毁obj
}
所以总共是两步:第一步先将对象的引用计数减1;第二步判断引用计数是否为0,为0则进行销毁。那么问题来了,假设有两个线程A和B,内部都引用了全局变量obj,此时obj指向的对象的引用计数为2,然后让两个线程都执行del obj这行代码。
其中A线程先执行,如果A线程在执行完--obj->ob_refcnt之后,会将对象的引用计数减一,但不幸的是这个时候调度机制将A挂起了,唤醒了B。而B也执行del obj,但是它比较幸运,将两步都一块执行完了。而由于之前A已经将引用计数减1,所以再减1之后会发现对象的引用计数为0,从而执行了对象的销毁动作,内存被释放。
然后A又被唤醒了,此时开始执行第二个步骤,但由于obj->ob_refcnt已经被减少到0,所以条件满足,那么A依旧会对obj指向的对象进行释放,但是这个对象所占内存已经被释放了,所以obj此时就成了悬空指针。如果再对obj指向的对象进行释放,最终会引发什么结果,只有天知道。
关键来了,所以Python引入了GIL,GIL是解释器层面上的一把超级大锁,它是字节码级别的互斥锁,作用就是:在同时一刻,只让一个线程执行字节码,并且保证每一条字节码在执行的时候都不会被打断。
所以由于GIL的存在,会使得线程只有把当前的某条字节码指令执行完毕之后才有可能会发生调度。因此无论是A还是B,线程调度时,要么发生在DELETE_NAME这条指令执行之前,要么发生在DELETE_NAME这条指令执行完毕之后,但是不存在指令(不仅是DELETE_NAME, 而是所有指令)执行到一半的时候发生调度。
因此GIL才被称之为是字节码级别的互斥锁,它是保护字节码指令只有在执行完毕之后才会发生线程调度。所以回到上面那个del obj这个例子中来,由于引入了GIL,所以就不存在我们之前说的:在A将引用计数减一之后,挂起A、唤醒B这一过程。因为A已经开始了DELETE_NAME这条指令的执行,所以在没执行完之前是不会发生线程调度的,至于为什么我们后面通过源码分析就知道了,总之此时就不会发生悬空指针的问题了。
事实上,GIL在单核时代,其最初的目的就是为了解决引用计数的安全性问题,只不过Python的作者龟叔没想到多核会发展的这么快。
那么,GIL是否会被移除呢?因为对于现在的多核cpu来说,Python的GIL无疑是进行了限制。
关于能否移除GIL,从个人的角度来说不太可能,这都几十年了,能移除早就移除了。
而且事实上,在Python诞生没多久,就有人发现了这一诡异之处,因为当时的程序猿发现使用多线程在计算上居然没有任何性能上的提升,反而还比单线程慢了一点。当时Python的官方人员直接回复:不要使用多线程,而是使用多进程。
此时站在上帝视角的我们知道,因为GIL的存在使得同一时刻只有一个核被使用,所以对于纯计算的代码来说,理论上多线程和单线程是没有区别的。但是由于多线程涉及上下文的切换,会额外有一些开销,所以反而还慢一些。
因此在得知GIL的存在之后,有两位勇士站了出来表示要移除GIL,当时Python处于1.5的版本,非常的古老了。当它们在去掉GIL的时候,发现多线程的效率相比之前确实提升了,但是单线程的效率只有原来的一半,这显然是不能接受的。因为把GIL去掉了,就意味着需要更细粒度的锁,这就会导致大量的加锁、解锁,而加锁、解锁对于操作系统来说是一个比较重量级的操作,所以GIL的移除是极其困难的。
另外还有一个关键,就是当GIL被移除之后,会使得扩展模块的编写难度大大增加。像很多现有的C扩展,在很大程度上依赖GIL提供的解决方案,如果要移除GIL,就需要重新解决这些库的线程安全性问题。比如:我们熟知的numpy,numpy的速度之所以这么快,就是因为底层是C写的,外面套上了一层Python的接口。而其它的库,像pandas、scipy、sklearn都是基于numpy之上的,如果把GIL移除了,那么这些库就都不能用了。还有深度学习,深度学习对应的库:tensorflow、pytorch等框架所使用的底层算法也都不是Python编写的,而是C和C++,Python只是起到了一个包装器的作用。Python在深度学习领域很火,主要是它可以和C无缝结合,如果GIL被移除,那么这些框架也没法用了。
还有Cython,Cython代码本质上也是翻译成C的代码,再编译成扩展模块给Python调用,本质上也是写扩展模块。所以我们可以看到,如果GIL被移除了,那么很多Python第三方库(包括上面提到的)可能就要重新洗牌了。
因此在2020年的今天,生态如此成熟的Python,几乎是不可能摆脱GIL了。
小插曲:我们说去GIL的老铁有两位,分别是Greg Stein和Mark Hammond,这个Mark Hammond估计很多人都见过,如果没见过,说明你Windows安装Python的时候不怎么关注。
特别感谢 Mark Hammond,没有它这些年无偿分享的Windows专业技术,那么Python如今仍会运行在DOS上。
图解GIL
我们说Python启动一个线程,底层会启动一个C线程,最终启动一个操作系统的线程。所以还是那句话,Python中的线程实际上是封装了C的线程,进而封装了OS线程,一个Python线程对应一个OS线程。实际执行的肯定是OS线程,而OS线程Python解释器是没有权限控制的,它能控制的只是Python的线程。假设有4个Python线程,那么肯定对应4个OS线程,但是Python解释器每次只让一个Python线程去调用OS线程的执行,其它的线程只能干等着,只有当前的Python线程将GIL释放了,其它的某个线程在拿到GIL时,才可以调用相应的OS线程去执行。
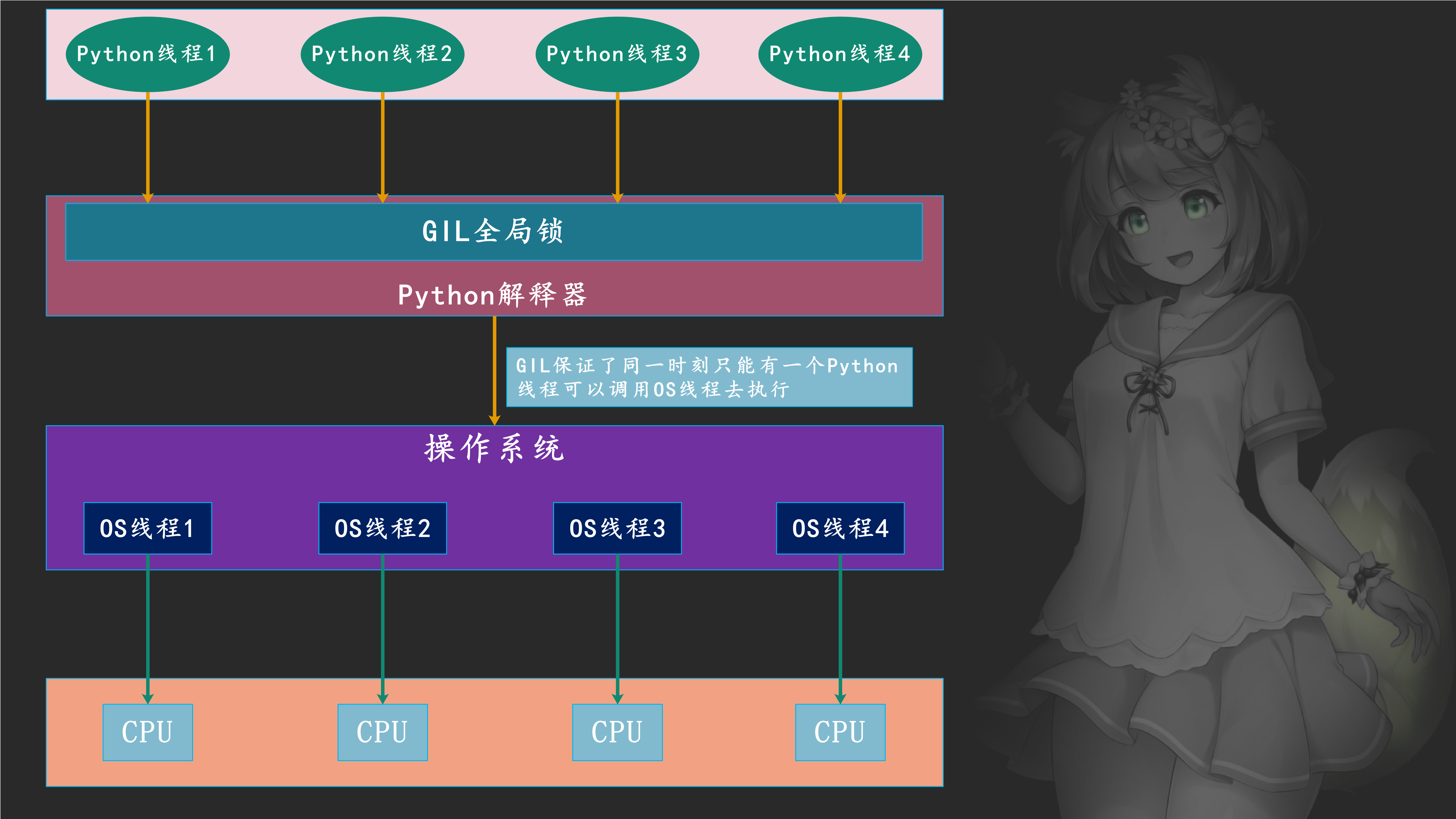
所以Python线程是调用C的线程、进而调用操作系统的OS线程,而每个线程在执行过程中Python解释器是控制不了的,因为Python的控制范围只有在解释器这一层,Python无权干预C的线程、更无权干预OS线程。
但是注意:GIL并不是Python语言的特性,它是CPython解释器开发人员为了方便才加上去的,只不过我们大部分用的都是CPython解释器,所以很多人认为CPython和Python是等价的,但其实不是的。Python是一门语言,而CPython是对使用Python语言编写的源代码进行解释执行的一个解释器。而解释器不止CPython一种,还有JPython,JPython解释器就没有GIL。因此Python语言本身是和GIL无关的,只不过我们平时在说Python的GIL的时候,指的都是CPython解释器里面的GIL,这一点要注意。
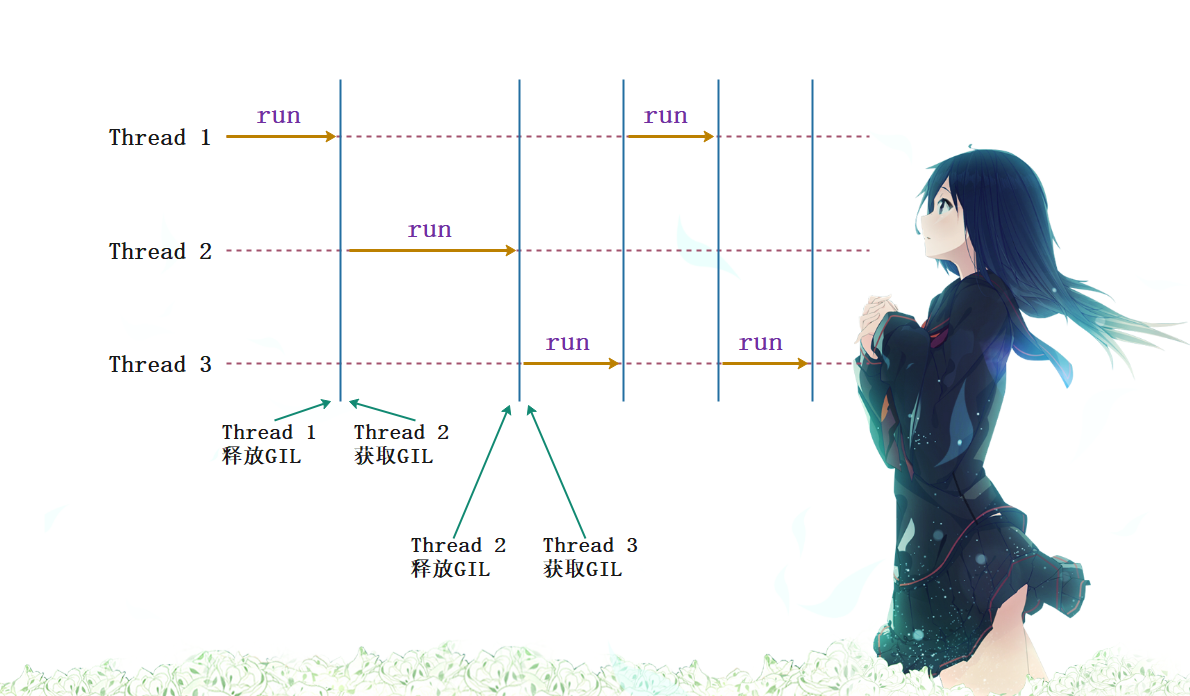
所以就类似于上图的结果,一个线程执行一会儿,另一个线程执行一会儿,至于线程怎么切换、什么时候切换,我们后面会说。
因此我们知道,对于Python而言,解释执行字节码是Python的核心所在,所以Python通过GIL来互斥不同线程调用解释器执行字节码。如果一个线程想要执行,就必须拿到GIL,而一旦拿到GIL,其他线程就无法执行了,如果想执行,那么只能等GIL释放、被自己获取之后才可以执行。然而实际上,GIL保护的不仅仅是Python的解释器,同样还有python的C API,在C/C++和Python混合开发时,在涉及到原生线程和python线程相互合作时,也需要通过GIL进行互斥。
有了GIL,在编写多线程代码的时候是不是就意味着不需要加锁了呢?
答案显然不是的,因为GIL保护的是每条字节码不会被打断,而一行代码一般是对应多条字节码的,所以每行代码是可以被打断的。比如:a = a + 1这样一条语句,它是对应4条字节码:LOAD_NAME、LOAD_CONST、BINARY_ADD、STORE_NAME。
假设此时a = 8,两个线程同时执行 a = a + 1,线程A执行的时候已经将a和1压入运行时栈,栈里面的a 显然是 8。但是还没有执行BINARY_ADD的时候,就被线程B执行了,此时B得到a显然还是8,因为线程A还没有对变量a做加法操作,然后B将这4条字节码全部执行完了,所以a应该是9。但是当线程A在执行的时候,会执行BINARY_ADD,不过注意:此时栈里面的a还是8,所以加完之后还是9。
所以本来a应该是10,但是却是9,就是因为在执行的时候发生的线程调度。所以我们在编写多线程代码的时候还是需要加锁的,GIL只是保证每条字节码执行的时候不会被打断,但是一行代码往往对应多条字节码,所以我们会通过threading.Lock()再加上一把锁。这样即便发生了线程调度,但由于我们在Python的层面上又加了一把锁,所以别的线程依旧无法执行。
Python会在什么情况下释放锁?
关于GIL的释放Python有一个自己的调度机制:
- 1. 当遇见io阻塞的时候会把锁释放,因为io阻塞是不耗费cpu的,所以此时虚拟机会把该线程的锁释放。
- 2. 即便是耗费cpu的运算等等,也不会一直执行,会在执行一小段时间之后释放锁,为了保证其他线程都有机会执行,就类似于cpu的时间片轮转的方式。
调度机制虽然简单,但是这背后还隐藏这两个问题:
在何时挂起线程,选择处于等待状态的下一个线程?在众多的处于等待状态的候选线程中,选择激活哪一个线程?
在Python的多线程机制中,这两个问题是分别由不同的层次解决的。对于何时进行线程调度问题,是由Python自身决定的。考虑一下操作系统是如何进行进程切换的,当一个进程运行了一段时间之后,发生了时钟中断,操作系统响应时钟,并开始进行进程的调度。同样,Python中也是模拟了这样的时钟中断,来激活线程的调度。我们知道Python解释字节码的原理就是按照指令的顺序一条一条执行,而Python内部维护着一个数值,这个数值就是Python内部的时钟。在Python2中如果一个线程执行的字节码指令数达到了这个值,那么会进行线程切换,并且这个值在Python3中仍然存在。
import sys
# 我们看到默认是执行100条字节码启动线程调度机制,进行切换
# 这个方法python2、3中都存在
print(sys.getcheckinterval()) # 100
# 但是在python3中,我们更应该使用这个函数,表示线程切换的时间间隔。
# 表示一个线程在执行0.005s之后进行切换
print(sys.getswitchinterval()) # 0.005
# 上面的方法我们都可以手动设置
# 通过sys.setcheckinterval(N)和sys.setswitchinterval(N)设置即可
但是在Python3.8的时候,使用sys.getcheckinterval和sys.setcheckinterval会被警告,表示这两个方法已经废弃了。
除了执行时间之外,还有就是我们之前说的遇见IO阻塞的时候会进行切换,所以多线程在IO密集型还是很有用处的,说实话如果IO都不会自动切换的话,那么我觉得Python的多线程才是真的没有用,至于为什么IO会切换我们后面说,总是现在我们知道Python会在什么时候进行线程切换了。那么下面的问题就是,Python在切换的时候会从等待的线程中选择哪一个呢?对于这个问题,Python则是借用了底层操作系统所提供的调度机制来决定下一个进入Python解释器的线程究竟是谁。
小结
这一次我们说了一下Python中的GIL和线程调度,我们后面会介绍线程的创建以及GIL的源码分析。