楔子
主从同步(主从复制)是 Redis 高可用服务的基石,也是多机运行中最基础的一个。我们把主要存储数据的节点叫做主节点 (master),把其他通过复制主节点数据的副本节点叫做从节点 (slave),如下图所示:
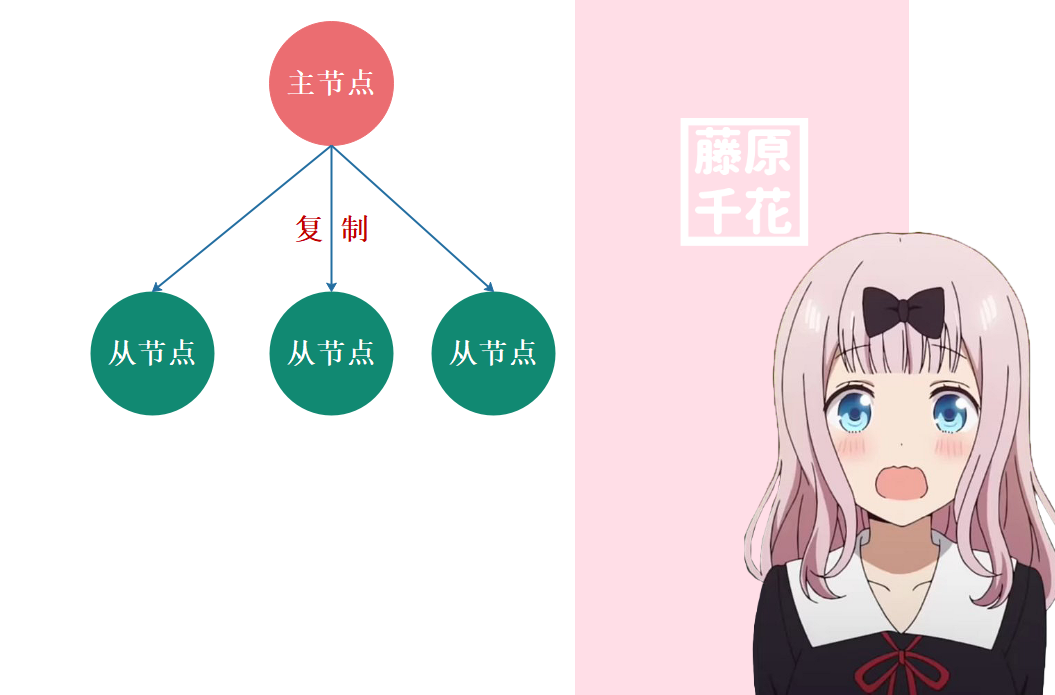
在 Redis 中一个主节点可以拥有多个从节点,一个从节点也可以是其他服务器的主节点,如下图所示:
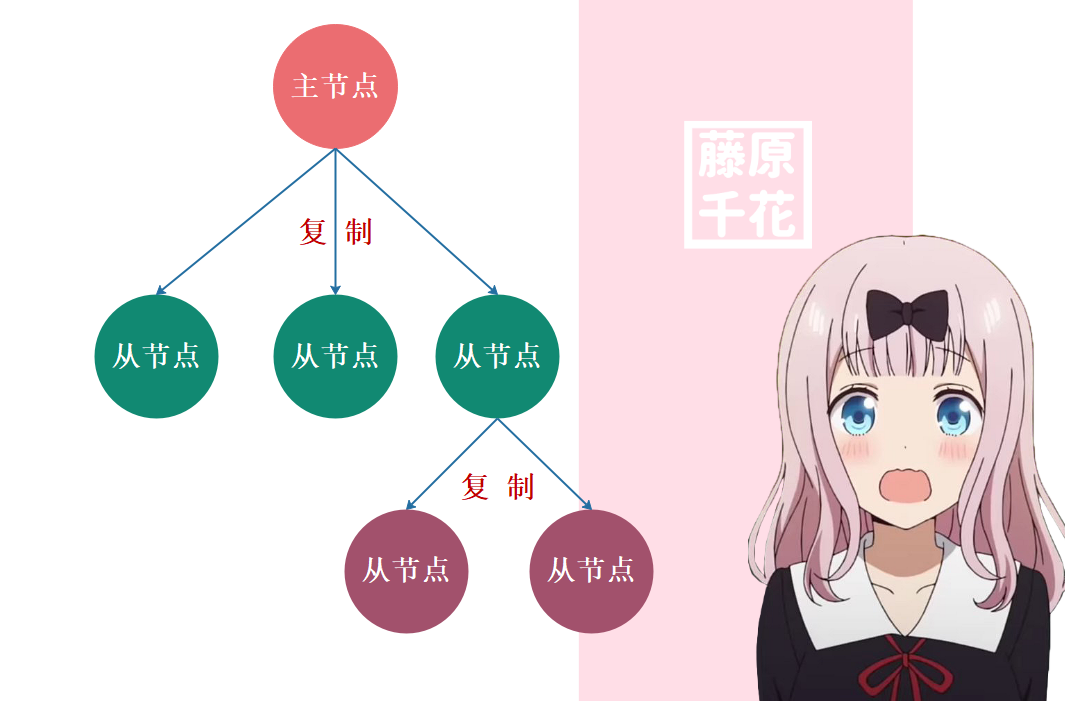
主从同步
主从同步的优点
优点有以下三个:
性能方面:有了主从同步之后,可以把查询任务分配给从服务器,用主服务器来执行写操作,这样极大的提高了程序运行的效率,把所有压力分摊到各个服务器了;高可用:当有了主从同步之后,当主服务器节点宕机之后,可以很迅速的把从节点提升为主节点,为 Redis 服务器的宕机恢复节省了宝贵的时间;防止数据丢失:当主服务器磁盘坏掉之后,其他从服务器还保留着相关的数据,不至于数据全部丢失。
既然主从同步有这么多的优点,那接下来我们来看如何开启和使用主从同步功能。
开启主从同步
由于我只有一台阿里云服务器,所以无法用实际的三台机器,不过万幸的是我们有docker,我们运行三个容器不就行啦。
这里我们启动三个容器,绑定宿主机的端口分别是6379、6380、6381,其中6379是master,6380和6381是slave,三个容器名分别叫redis_master、redis_slave1、redis_slave2。
但是注意:docker根据redis镜像启动的容器是没有配置文件的,因为docker根据redis镜像创建的容器默认是无配置文件启动Redis的。如果想指定Redis的配置,方法有以下三种:
创建容器的时候通过数据卷的方式,我们将宿主机中的redis.conf传递到容器里面,然后启动Redis的时候手动指定配置文件。创建容器的时候,在命令行中指定配置,我们知道Redis的配置文件中可配置的东西很多,但如果我们只需要修改一两个,那么也可以在命令行中中进行设置。比如:docker run -d --name redis_master -p 6379:6379 redis --slaveof 127.0.0.1 6379 --masterauth 123456Redis的一个特点是可以在配置文件中修改,重启生效;也可以在命令行中修改,会立即生效,只不过重启Redis的时候就没有了。因此我们在启动Redis进入控制台之后,在控制台中设置也是可以的。
而Redis开启主从同步非常简单,只需要在从节点的配置文件中指定slaveof <master_ip> <master_port>即可,当然如果主节点设置的密码,那么从节点还需要指定masterauth <master的密码>。
或者我们还有一种方式,我们将宿主机上的Redis配置文件拷贝一下,得到三份配置文件,分别监听6379、6380、6381,然后指定不同的配置文件分别启动也是可以的,我们就用这种方式启动吧。主要是docker启动之后,三个容器的页面上显示的都是127.0.0.1:6379>,不好区分。
# 注意要将配置文件中的daemonize设置为yes,否则不会后台启动,而是会卡主
redis-server ~/master/redis.conf
redis-server ~/slave1/redis.conf
redis-server ~/slave2/redis.conf
然后我们查看进程:

我们看到此时启动三个redis-server进程,然后通过redis-cli启动控制台显然我们此时要打开三个终端,进入控制台之后可以通过通过info replication来查看状态。
# master节点
127.0.0.1:6379> info replication
# Replication
role:master # 角色为master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379>
# slave1节点
127.0.0.1:6380> info replication
# Replication
role:master # 角色为master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380>
# slave2节点
127.0.0.1:6381> info replication
# Replication
role:master # 角色为master
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6381>
我们看到此时的三个redis-server都是master,原因就在于我们没有在配置文件中指定slaveof,所以它们都是独立的,之间没有任何关系。下面我们来设置集群:
# 我们先以6380、也就是slave1为例
127.0.0.1:6380> set name nana # 设置一个key
OK
127.0.0.1:6380> get name # 获取key
"nana"
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 将自身作为127.0.0.1 6379的子节点
OK
127.0.0.1:6380> info replication # 查看状态
# Replication
role:slave # 发现角色从master变成了slave
master_host:127.0.0.1 # master的ip
master_port:6379 # master的host
master_link_status:up # master的状态,如果master在线,那么为up,否则是down
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:1
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380>
127.0.0.1:6380> get name # 此时再次获取name,发现为nil?为什么,我们之前不是设置name了吗?原因下面分析
(nil)
127.0.0.1:6380>
一旦执行了slaveof(由于slave这个单词存在歧视,所以Redis中也可以使用replicaof,是等价的),那么这台Redis主节点就变成了其它主节点的从节点,然后从节点上的数据会被清空,主节点将自身的数据副本同步给从节点。尽管6381这个节点设置了name这个key,但是当它执行了slaveof之后就变成了从节点,所以自身的数据就没清空了,而主节点又没有name这个key,所以最后get name的结果为nil。
然后将6381、也就是slave2也设置成从节点。
127.0.0.1:6381> role # 除了info replication之外,还可以使用role来查看,得到结果更精简一些。
1) "master" # 此时是master
2) (integer) 1161
3) (empty list or set)
127.0.0.1:6381> slaveof 127.0.0.1 6379 # 设置为从节点
OK
127.0.0.1:6381> role
1) "slave" # 显示变成了slave
2) "127.0.0.1" # 主节点的ip
3) (integer) 6379 # 主节点的端口
4) "connected" # 连接状态,此时表示连接
5) (integer) 1189
127.0.0.1:6381>
最后再来看看主节点master的状态:
127.0.0.1:6379> role # 查看角色
1) "master" # 显示为master
2) (integer) 1329
3) 1) 1) "127.0.0.1" # 下面是两位从节点的信息
2) "6380"
3) "1329"
2) 1) "127.0.0.1"
2) "6381"
3) "1329"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> info replication # 使用更详细的命令查看
# Replication
role:master # 角色是master
connected_slaves:2 # 连接的从节点有两个
slave0:ip=127.0.0.1,port=6380,state=online,offset=1329,lag=1 # 从节点的信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=1343,lag=0
master_repl_offset:1343
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:1342
127.0.0.1:6379>
主从同步是如何工作的
主从同步分为两种:全量同步和增量同步。
全量同步
"从服务器"会自动发送一个SYNC命令
(也可以手动执行SYNC),不管它是第一次连接还是再次连接都无所谓,然后"主服务器"会执行bgsave进行后台存储生成RDB文件,并且开始缓存新连接进来的修改数据的命令。当主服务器完成后台存储后,主服务器会把RDB文件发送给从服务器,从服务器将其保存在磁盘上,然后加载到内存中。然后主服务器会再把刚才缓存的命令发送到从服务器,这是作为命令流来完成的,并且和Redis协议本身格式相同。
增量同步
在 Redis 2.8 之前每次从服务器离线再重新上线之前,主服务器会进行一次完整的数据同步,然后这种情况如果发生在离线时间比较短的情况下,只有少量的数据不同步却要同步所有的数据是非常笨拙和不划算的,在 Redis 2.8 这个功能得到了优化。
Redis 2.8 的优化方法是当从服务器离线之后,主服务器会把离线之后的写入命令,存储在一个特定大小的队列中,队列是可以保证先进先出的执行顺序的,当从服务器重写恢复上线之后,主服务会判断离线这段时间内的命令是否还在队列中,如果在就直接把队列中的数据发送给从服务器,这样就避免了完整同步的资源浪费。存储离线命令的队列大小默认是 1MB,使用者可以自行修改队列大小的配置项 repl-backlog-size。
无盘数据同步
从前面的内容我们可以得知,在第一次主从连接的时候,会先产生一个 RDB 文件,再把 RDB 文件发送给从服务器,如果主服务器是非固态硬盘的时候,系统的 I/O 操作是非常高的,为了缓解这个问题,Redis 2.8.18 新增了无盘复制功能,无盘复制功能不会在本地创建 RDB 文件,而是会派生出一个子进程,然后由子进程通过 Socket 的方式,直接将 RDB 文件写入到从服务器,这样主服务器就可以在不创建RDB文件的情况下,完成与从服务器的数据同步。要使用该功能,只需把配置项 repl-diskless-sync 的值设置为 yes 即可,它默认配置值为 no。
测试同步功能
我们在主机设置key,然后看看在从机上能不能获取得到。
127.0.0.1:6380> get name
(nil) # 显然此时从机是没有name这个key的
127.0.0.1:6380>
127.0.0.1:6379> set name nana
OK # 在主机中设置name
127.0.0.1:6379>
127.0.0.1:6380> get name # 在从机中进行获取
"nana"
127.0.0.1:6380> # 同理我们在6381上获取也是获取的到的
我们知道一旦成为从机之后,自身的数据就会被情况,然后同步主机的数据,因为此时已经和指定的master建立联系了。
127.0.0.1:6380> slaveof 127.0.0.1 6379 # 如果继续连接,会提示我们已经连接到指定的master了
OK Already connected to specified master
127.0.0.1:6380>
但是问题来了, 如果我们在从机上写数据,会不会同步到主机上面呢?
127.0.0.1:6380> set name mea
(error) READONLY You can't write against a read only slave.
127.0.0.1:6380> # 答案是根本不允许在从机上进行写操作
一旦成为从机,那么它就不能写入数据了,只能老老实实地从主机备份数据。所以在默认情况下,处于复制模式的主服务器(或者主机)既可以执行写操作也可以执行读操作,而从服务器(或者从机)则只能执行读操作。如果想让从机也支持写操作,那么设置config set replica-read-only no即可,或者在配置文件中修改,便可以使从服务器也开启写操作,但是需要注意以下几点:
在从服务器上写的数据不会同步到主服务器;当键值相同时主服务器上的数据可以覆盖从服务器;在进行完整数据同步时,从服务器数据会被清空。
关闭主从同步
我们看到实现主从同步还是很简单的,就是指定一个slaveof,可以在配置文件中指定,可以在启动时通过命令行的方式指定,还可以在进入控制台的时候设置。当然如果主机设置了密码,那么从机也要指定masterauth,整体没什么难度。
那么如何关闭主从同步呢?关闭主从同步有两种方式:第一种是通过slave <other_master_ip> <other_master_port>,将该从节点指向其它的主节点,但是该机器依旧是master;另一种方式是通过slaveof no one,这种方式就是关闭主从同步,然后该机器也会有slave变成master。
127.0.0.1:6380> slaveof 127.0.0.1 6666 # 随便指向一个节点
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 依旧是slave
master_host:127.0.0.1
master_port:6666
master_link_status:down # 但是master不是up,而是down,因为6666是我们随便指定的
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1
master_link_down_since_seconds:1595144745
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6380>
127.0.0.1:6381> slaveof no one # 取消主从同步
OK
127.0.0.1:6381> role
1) "master" # 此时变成了master
2) (integer) 4101
3) (empty list or set)
127.0.0.1:6381>
127.0.0.1:6379> role # 6379依旧是master,但是它的下面已经没有slave了。
1) "master"
2) (integer) 4143
3) (empty list or set)
127.0.0.1:6379>
小结
这一节我们介绍了主从同步,使用了集群的方式,当然我们这里只有一台机器,算是伪集群吧。不过它的操作方式和真正的集群是一样的,只需要设置好master的ip和port即可。
另外,由于我在演示集群的时候使用的不是docker,而是宿主机的Redis,原因就是容器对应的控制台显示的全部是6379,而宿主机显示的是6379、6380、6381,会更直观一些,可以直接就知道模拟的是哪一个节点。而我当前机器的Redis版本不高,所以使用的命令是slaveof,但是在 Redis 5.0 之后复制命令被改为了 replicaof,所以在高版本(Redis 5+)中我们应该尽量使用 replicaof,因为 slaveof 命令可能会被随时废弃掉
(目前的话slaveof还是支持的)。