楔子
前面我们说了Cython是什么,为什么我们要用它,以及如何编译和运行Cython代码。有了这些知识,那么是时候进入Cython的深度探索之路了。
在本篇博客中,我们会先介绍Cython在加速Python代码方面的工作原理,这将帮助我们理解Cython是如何工作的。了解完原理之后,会学习Cython的语法。
解释执行 VS 编译执行
为了更好地理解为什么Cython可以提高Python代码的执行性能,有必要对比一下Python虚拟机执行Python代码和操作系统执行已经编译的C代码之间的差别。
Python代码在运行之前,会先被编译成字节码(对应Python底层的PyCodeObject),字节码是能够被Python虚拟机解释或者执行的基础指令集。而虚拟机独立于平台,因此在一个平台生成的字节码可以在任意平台运行。虚拟机将一个高级字节码翻译成一个或者多个可以被操作系统执行、最终被CPU执行的低级操作(指令)。这种虚拟化很常见并且十分灵活,可以带来很多好处:其中一个好处就是不会被挑剔的编译器嫌弃(相较于编译型语言,你在一个平台编译的可执行文件在其它平台上可能就用不了了),而缺点是运行速度比本地编译好的代码慢。
而站在C的角度,由于不存在虚拟机或者解释器,因此也就不存在所谓的高级字节码。C代码会被直接翻译、或者编译成机器码,可以直接以一个可执行文件或者动态库(dll或者so)的形式存在。但是注意:它依赖于当前的操作系统,是为当前平台和架构量身打造的。因为可以直接被CPU执行,所以它与所在的操作系统是有关系的。
那么有没有一种办法可以弥补虚拟机的字节码和CPU的机器码之间的宏观呢?答案是有的,那就是C代码可以编译成一种称之为扩展模块的特定类型的动态库,并且这些模块必须是成熟的Python模块,但是里面的代码已经是经由标准C编译器编译成的机器代码。那么Python在导入扩展模块执行的时候,虚拟机不会再解释高级字节码,而是直接运行机器代码,这样就能移除解释器的性能开销。
这里我们提一下扩展模块,我们说Windows中存在dll(动态链接库)、Linux中存在so(共享文件)。如果只是C或者C++、甚至是是go等等编写的普通源文件,然后编译成dll或者so,那么这两者可以通过ctypes调用,但是无法通过import导入。如果你强行导入,那么会报错:
ImportError: dynamic module does not define module export function但是如果是遵循Python编写扩展模块的api的话,然后使用Python编译成扩展模块的话,尽管该扩展模块在Linux上也是.so、Windows上pyd
(pyd也是个dll),但是它们是可以直接被Python解释器识别被导入的。
那么Cython是怎么插上一脚的呢?正如我们在上一篇博客说的那样,我们可以使用cython编译器和标准C编译器将Cython源代码翻译成依赖特定平台的扩展模块,这样无论Python在执行扩展模块的时候,就等同于运行机器码,省去了翻译的过程。
那么将一个普通的Python代码编译成扩展模块的话(我们说Cython是Python的超集,即使是纯Python也是可以编译成扩展模块的),效率上可以有多大的提升呢?根据Python代码所做的事情,这个差异会非常广泛。但是通常将Python代码转换成等效的扩展模块的话,效率大概有10%到30%的提升。因为一般情况下,代码既有IO密集也会有CPU密集。
所以即便没有任何的Cython代码,纯Python在编译成扩展模块之后也会有性能的提升。并且如果是纯计算型,那么效率会更高。
Cython给了我们免费加速的便利,让我们在不写Cython、或者只写纯Python的情况下,还能得到优化。但这种只针对纯Python进行的优化显然只是扩展模块的冰山一角,真正的性能改进是使用Cython的静态类型来替换Python的动态解析。
因为我们说Python不会进行基于类型的优化,所以即使编译成扩展模块,但如果类型不确定,还是没有办法达到高效率的。
就拿两个变量相加举例:我们说Python不会做基于类型方面的优化,所以这一行代码对应的机器码数量显然会很多,即使编译成了扩展模块之后,其对应的机器码数量也是类似的
(内部会有优化,因此机器码数量可能会少一些,但不会少太多)。这两者区别就是:Python是有一个翻译的过程,将字节码翻译成机器码;而扩展模块是已经直接就帮你全部都翻译成机器码了。但是CPU执行的时候,由于机器码数量是差不多的,因此执行时间也是差不多的,区别就是少了一个翻译的过程。但是很明显,Python将字节码翻译成机器码花费的时间几乎是不需要考虑的,重点是在CPU执行机器码所花费的时间。因此对纯Python代码编译成扩展模块,那么速度不会提升太明显,提升的10~30%也是cython编译器内部的优化,比如:发现函数种某个对象在函数结束就不被使用了,所以将其分配的栈上等等。如果是使用Cython指定了类型,而如果类型确定的话那么机器码的数量就会大幅度减少。CPU执行10条机器码花的时间和执行1条机器码花的时间那个长,不言而喻。
动态类型 VS 静态类型
Python语言 和 C、C++之间的另一个重要的差异就是:前者是动态类型,后者是静态类型。静态类型语言要求在编译的时候就必须指定变量的类型,我们经常会通过显式的声明一个变量来完成这一点,或者在某些情况下编译器会自动推断变量的类型。另一方面,如果一旦声明某个变量,那么之后此作用域该中变量的类型就不可以再改变了。
看起来限制还蛮多的,那么静态类型可以带来什么好处呢?除了编译时的类型检测,编译器也可以根据静态类型生成适应相应平台的高性能机器码。
动态语言则对变量的类型没有严格要求,这里指的是不需要显式的声明变量,解释器会根据你给变量赋的值来推断变量的类型。因此Python中如果想创建一个变量,那么必须在创建的同时赋上值,不然Python不知道这个变量是什么类型,也不知道要提前申请多大的空间。而像C这种静态语言,可以创建一个变量的同时不赋上初始值,比如:int n;,因为已经知道n是一个int类型了,所以分配的空间大小已经确定了。
并且对于动态语言来说,变量即使在同一个作用域中也可以指向任意的对象。并且Python中的变量是一个指针,比如:a = 666,相当于创建了一个整型666,然后让a这个变量指向它;如果再来一个a = "古明地觉",那么会再创建一个字符串,然后让a指向这个字符串,或者说a不再存储整型666的地址,而是存储新创建的字符串的地址。
所以在运行Python程序时,解释器要花费很多时间来确认要执行的低阶操作,并抽取相应的数据。考虑到Python设计的灵活性,解释器总是要一种非常通用的方式来确定相应的低阶操作,因为Python中的变量在任意时刻可以有任意类型。以上便是所谓的动态解析,而Python的通用动态解析是缓慢的。
还是以a + b为例子:
1. 解释器要检测a引用的对象的类型,这在C一级至少需要一次指针查找。2. 解释器从该类型中寻找加法方法的实现,这可能一个或者多个额外的指针查找和内部函数调用。3. 如果解释器找到了相应的方法,那么解释器就有了一个实际的函数调用。4. 解释器会调用这个加法函数,并将a和b作为参数传递进去。5. 我们说Python中的对象在C中都是一个结构体,比如:整型,在C中是PyLongObject,内部有引用计数、类型、ob_size、ob_digit,这些成员是什么不必关心,总之其中一个成员肯定是存放具体的值的,其他成员是存储额外的属性的。而加法函数显然要从这两个结构体中筛选出实际的数据,显然这需要指针查找以及从Python类型到C类型之间的转换。如果成功,那么会执行加法的实际操作。如果不成功,比如类型不对,发现a是整型但b是个字符串,就会报错。6. 执行完加法操作之后,必须将结果再转回Python中的对象才能够返回。
而C语言面对a + b这种情况,表现则是不同的。因为C是静态编译型语言,C编译器在编译的时候就决定了执行的低阶操作和要传递的参数数据。在运行时,一个编译好的C程序几乎跳过了Python解释器要必须执行的所有步骤。如果a + b,编译器提前就确定好的类型,比如整型,那么编译器生成的机器码指令是寥寥可数的:将数据加载至寄存器,相加,存储结果。
所以我们看到编译后的C程序几乎将所有的时间都只花在了调用快速的C函数以及执行基本操作上,没有Python的那些花里胡哨的动作。并且由于静态语言对变量类型的限制,编译器会生成更快速、更专业的指令,这些指令是为其数据量身打造的。因此某些操作,使用C语言可以比使用Python快上几百倍甚至几千倍,这简直再正常不过了。
因此Cython在性能上可以带来如此巨大的提升的原因就在于,它将静态类型引入Python中,静态类型将运行时的动态解析转化为了基于类型优化的机器码。
另外,在Cython之前我们只能通过在C中重新实现Python代码来从静态类型中获益,也就是用C来编写所谓的扩展模块。而Cython可以让我们很容易地写类似于Python代码的同时,还能使用C的静态类型系统。而我们下面将要学习的第一个、也是最重要的Cython关键字就是cdef,它是我们通往C性能的大门。
通过cdef进行静态类型声明
首先Python中声明变量的方式在Cython中也是可以使用的。
a = [x for x in range(12)]
b = a
a[3] = 42.0
assert b[3] == 42.0
a = "xxx"
assert isinstance(b, list)
在Cython中,没有类型化的动态变量的行为和Python完全相同,通过赋值语句b = a允许b和a都指向同一个列表。在a[3] = 42.0之后,b[3] = 42.0也是成立的,因此断言成立。即便后面将a修改了,也只是让a指向了新的对象,调整相应的引用计数,而对b而言则没有受到丝毫影响,因此b依旧是一个列表。这是完全合法、并且有效的Python代码。
而对于静态类型变量,我们在Cython中通过cdef关键字并指定类型、变量名的方式进行声明。比如:
cdef int i
cdef int j
cdef float k
# 我们看到就像使用Python和C的混合体一样
j = 0
i = j
k = 12.0
j = 2 * k
assert i != j
上面除了变量的声明之外,其它的使用方式和Python并无二致,当然简单的赋值的话基本上所有语言都是类似的。但是Python的一些内置的函数、类、关键字等等都是可以直接使用的,因为我们Cython中是可以直接写Python代码的,它是Python的超集。
但是有一点需要注意:我们上面创建的变量i、j、k是使用cdef关键字进行声明的,所以它们是C中的类型,其意义最终是要遵循C的标准的。
不仅如此,就连声明变量的方式也是按照C的标准来的。
cdef i, j, k
cdef float x, y
# 或者
cdef int a = 1, b = 2
cdef float c = 3.0, b = 4.1
而在函数内部,cdef也是要进行缩进的,它们声明的变量也是一个局部变量。
def foo():
# 这里的cdef是缩进在函数内部的
cdef int i
cdef int N = 2000
cdef float a, b = 2.1
并且cdef还可以使用类似于Python中上下文的方式
def foo():
# 这种声明方式也是可以的,和上面的方式是完全等价的
cdef:
int i
int N = 2000
float a, b = 2.1
# 但是注意声明的变量要注意缩进
# Python对缩进是有讲究的,它规定了Python中的作用域
# 所以我们看到Cython在语法方面还是保留了Python的风格
关于静态和常量
如果你了解C的话,那么思考一下:如果想在函数中返回一个局部变量的指针并且外部在接收这个指针之后,还能访问指针指向的值,这个时候该怎么办呢?我们知道C函数中的变量是分配在栈上的
(不使用malloc函数,而是直接创建一个变量),函数结束之后变量对应的值就被销毁了,所以这个时候即使返回一个指针也是无意义的。尽管比较低级的编译器检测不出来,你在返回指针之后还是能够访问指向的内存,但是这只是你当前使用的编辑器比较笨,它检测不出来。如果是高级一点的编译器,那么你在访问的时候会报出段错误或者打印出一个错误的值;而更高级的编译器甚至连指针都不让你返回了,因为指针指向的内存已经被回收了,你要这个指针做什么?因此指针都不让你返回了。而如果想做到这一点,那么只需要在声明变量的同时在前面加上static关键字,比如static int i,这样的话i这个变量就不会被分配到栈区,而是会被分配到文字常量区,它的声明周期就不会随着函数的结束而结束,而是伴随着整个程序。
但是static并不是一个有效的Cython关键字,因此我们无法在Cython声明一个C的静态变量。除了static,在C中还有一个const,用来声明一个不可变的变量,也就是常量,一旦使用const声明,比如const int i = 3,那么这个i在后续就不可以被修改了。而在Cython中,至少目前我们是无需关心const的,而且const在当前的Cython中也已经不再是关键字了,关于const我们后面的系列中会说。
我们可以在Cython中声明C支持的任意种类的变量,使用cdef关键字声明即可。
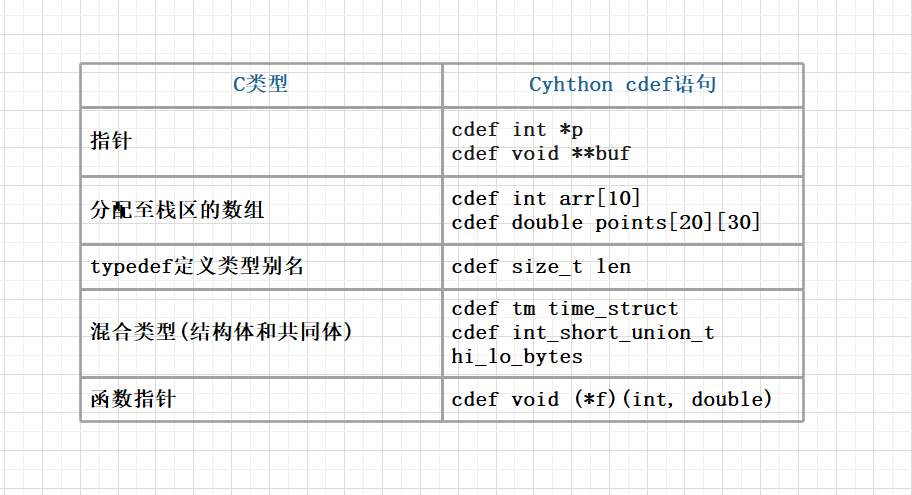
Cython也支持复杂的声明,总之你在C中声明变量的方式在Cython也可以实现。
cdef int (*signal(int (*f)(int)))(int)
显然我们声明了一个函数,但如果你不是一个C老手的话,很难一下子就看出这个函数是做什么的。我们来分析一下:
1. 我们将signal(int (*f)(int))看成一个整体,假设就用func来替代吧,那么就变成了cdef int (*func)(int)。显然这是一个函数指针,什么样的函数指针呢?接收一个整型、返回一个整型的函数指针。2. 然后再看signal(int (*f)(int)),而显然signal里面也接收一个函数指针(同样是接收一个整型、并返回一个整型的函数指针)。3. 所以signal是一个函数指针,其对应的函数"是一个接收一个函数指针并返回一个函数指针"的函数。无论是接收的函数指针,还是返回的函数指针,其指向的函数都是接收一个整型、返回一个整型的函数。
可能有点绕啊,我们换一种分析方式,如果是cdef int (*signal)(int),那么显然signal就是接收一个整型、返回一个整型的函数指针;如果是cdef int (*signal(int))(int),那么此时signal函数的返回值是接收一个整型、返回一个整型的函数指针,而这个signal接收的参数是一个int;回到开始的例子,如果是cdef int (*signal(int (*f)(int)))(int),那么依旧是signal返回值是接收一个int、返回一个int的函数指针,signal接收的参数是什么呢?答案也是一个接收一个int、返回一个int的函数指针。因此终上所述:signal是一个函数指针,这个函数接收一个函数指针(函数接收一个整型、返回一个整型),并返回一个函数指针(同样是接收一个整型、返回一个整型)
显然有点绕,可以慢慢分析,不过日常也用不到这样的函数声明。
Cython中的自动类型推断
在Cython中声明一个静态类型变量,使用cdef并不是唯一的方法,Cython会对函数体中没有进行类型声明的变量自动执行类型推断。比如:for循环中全部都是整型相加,没有涉及到其它类型的变量,那么Cython在自动对变量进行推断的时候会发现这个变量可以被优化为静态类型的变量。
但是一个程序不会那么智能地对于一个动态类型的语言进行全方位的优化,默认情况下,Cython只有在确认这么做不会改变代码块的语义之后才会进行类型推断。
看一下下面这个简单的函数:
def automatic_inference():
i = 1
d = 2.0
c = 3+4j
r = i * d + c
return r
在这个例子中,Cython将字面量1、3 +4j以及变量i、c、r标记为通用的Python对象。尽管这些类型和C中的类型具有高度的相似性,但是Cython会保守地推断整型i可能无法代表C中的long,因此会将其作为符合Python代码语义的Python对象。而对于d = 2.0,则可以自动推断出符合C中的double,因为Python中的浮点数对应的值在底层就是使用一个double来存储的。所以最终对于用户来讲,变量d看似是一个Python中的对象,但是Cython在执行的时候会讲其视为C中的double以提高性能。
另外通过infer_types编译器指令,我们可以在一些可能会改变Python代码语义的情况下给Cython留有更多的余地来推断一个变量的类型。比如:当两个整型相加时可能导致的结果溢出。因为Python中的整型在底层是使用数组来存储的,所以不管多大都可以相加,只要你的内存足够。但是在C中不可以,因为C中的变量是有明确的类型的,既然是类型,那么空间在一开始就已经确定了。比如int使用4个字节,而一旦结果使用4个字节无法表示的时候,就会得到一个意向不到的错误结果。所以在Cython做类型推断的时候,我们是需要给其留有这样的余地的。
对于一个函数如果启动这样的类型推断的话,我们可以使用infer_types的装饰器形式。
cimport cython
@cython.infer_types(True)
def more_inference():
i = 1
d = 2.0
c = 3+4j
r = i * d + c
return r
这里出现了一个新的关键字叫做cimport,至于它的含义我们后面会说,目前只需要知道它和import关键字一样,是用来导入的即可。然后我们通过装饰器@cython.infer_types(True),启动了相应的类型推断,也就是给Cython留有更多的猜测空间。
当Cython支持更多的推断的时候,所以变量i被类型化为C long;d和之前一样是double,而c和r都是复数变量,复数则依旧使用Python中的复数类型。但是注意:并不代表启用infer_types时,就万事大吉了;我们知道在不指定infer_types的时候,Cython在推断类型的时候显然是采用最最保险的方法、在保证程序正确执行的情况下进行优化,不能因为为了优化而导致程序出现错误,显然正确性和效率之间正确性是第一位的。而整型由于存在溢出的问题,所以Cython是不会自动转化为C long的;但是我们通过infer_types启动了更多的类型推断,因此在不改变语义的情况下Cython是会将整型推断为C long的,但是溢出的问题它是不知道的,所以在这种情况下是需要我们来要负责确保整型不会出现溢出的。
Cython中的C指针
正如我们在上面的图表中见到的那样,可以使用C的语法在Cython中声明一个C指针。
cdef double a
cdef double *b = NULL
# 和C一样,*可以放在类型或者变量的附近
# 但是如果在一行中声明多个指针变量,那么每一个变量都要带上*
cdef double *c, *d
# 如果是这样的话,则表示声明一个指针变量和一个整型变量
cdef int *e, f
既然可以声明指针变量,那么说明能够取得某个变量的地址才对。是的,在Cython中通过&获取一个变量的地址。
cdef double a
cdef double *b = &a
问题来了,既然可以获取指针,那么能不能通过*来获取指针指向的值呢?答案是可以的,准确的说是可以获取值,但是方式不是通过*来实现的。我们知道在Python中,*是有特殊含义的,没错,就是*args和**kwargs,它们允许函数中接收任意个数的参数,并且通过*还可以对一个序列进行解包。因此对于Cython来讲,无法通过*p这种方式来获取p指向的内存。在Cython中获取指针指向的内存的方式是通过类似于p[0]这种方式,p是一个指针变量,那么p[0]就是p指向的内存。
cdef double a = 3.14
cdef double *b = &a
print(f"a = {a}")
# 修改b指向的内存
b[0] = 6.28
# 再次打印a
print(f"a = {a}")
我们编译成pyd试一下吧,名字就叫pointer.pyd,另外这里要提一下:我们编译的pyd是用来被导入的,可不要直接 python xxx.pyd,这样的话是不会成功的,因为xxx.pyd不是一个有效的文本文件。顺便说一下,我现在是在公司用摸鱼的时间写的博客,而当前Windows上的gcc是可以正常编译的;而我回到家之后由于电脑网络问题,懒得安装gcc了,所以就直接用Linux演示了。所以有的时候我编译得到的是.pyd,有时候是.so,因此这一点请不要在意,因为两个平台都是一样的。
import pointer
"""
a = 3.14
a = 6.28
"""
pyd里面有print,因此直接导入就自动执行并打印了,我们看到a确实被修改了。因此我们在Cython中可以通过&来获取指针,也可以通过 指针[0]的方式获取指针指向的内存。唯一的区别就是C里面是使用*的方式,而在Cython里面如果使用*b = 6.28这种方式在语法上则是不被允许的。
而C和Cython中关于指针的另一个区别就是该指针在指向一个结构体的时候,假设一个结构体指针叫做s,里面有两个成员a和b,都是整型。那么对于C而言,可以通过s -> a + s -> b的方式将两个成员相加,但是对于Cython来说,则是s.a + s.b。我们看到这个和golang是类似的,无论是结构体指针还是结构体本身,都是使用.的方式访问结构体内部成员。
静态类型变量和动态类型变量的混合
Cython允许静态类型变量和动态类型变量之间进行赋值,这是一个非常强大的特性。它允许我们使用动态的Python对象,并且在决定性能的地方能很轻松地将其转化为快速的静态对象。
假设我们有几个静态的C int要组合成一个Python中的元组,Python/C api创建和初始化的话很简单,但是却很乏味,需要几十行代码以及大量的错误检查;而在Cython中,只需要像Python一样做即可:
cdef int a, b, c
t = (a, b, c)
编译导入一下,pyd的名称就叫mix吧
import mix
# 我们看到在Cython中没有指定初始值,所以默认为0
# 比如我们直接a = int(), 那么a也是0
print(mix.t) # (0, 0, 0)
print(type(mix.t)) # <class 'tuple'>
print(type(mix.t[0])) # <class 'int'>
# 虽然t是可以访问的,但是a、b、c是无法访问的,因为它们是C中的变量
# 使用cdef定义的变量都会被屏蔽掉,在Python中是无法使用的
try:
print(mix.a)
except Exception as e:
print(e) # module 'mix' has no attribute 'a'
我们看到执行的过程很顺畅,这里要说的是:a、b、c都是静态的整型,Cython允许使用它们创建动态类型的Python元组,然后将该元组分配给t。所以这个小栗子便体现了Cython的美丽和强大之处,可以以显而易见的方式创建一个元组,而无需考虑其它情况。Cython的目的就在于此,希望概念上简单的事情在实际操作上也很简单。
想象一下使用Python/C api的场景,如果要创建一个元组该怎么办?首先要使用PyTuple_New申请指定元素个数的空间,还要考虑申请失败的情况,然后调用PyTuple_SetItem将元素一个一个的设置进去,这显然是非常麻烦的,肯定没有
t = (a, b, c)来的直接。
虽说如此,但并不是所有东西都可以这么做的。上面的例子之所以有效,是因为Python int和C int有明显的对应关系。如果是指针呢?首先我们知道Python中没有指针这个概念,或者说指针被Python隐藏了,只有解释器才能操作指针。因此在Cython中,我们不可以在函数中返回一个指针,以及打印一个指针、指针作为Python的动态数据结构(如:元组、列表、字典等等)中的某个元素,这些都是不可以的。回到我们元组的那个例子,如果a、b、c是一个指针,那么必须要在放入元组之前取消它们的引用,或者说放入元组中的只能是它们指向的值。
因此如果想访问相应的变量,那么必须是指向Python数据类型的变量;同理对于容器,里面放入的也必须是指向Python中数据类型的变量才行。而Python中没有指针的概念,所以不能将指针放在元组里面。同理:假设cdef int a = 3,可以是cdef int *b = &a,但绝不能是b = &a。因为直接b = xxx的话,那么b是Python中的变量,其类型则需要根据值来推断,然而值是一个指针,所以这是不允许的。
但是cdef int b = a和b = a则都是合法的,因为a是一个整型,C中的整型是可以转化成Python中的整型的,因此编译的时候会自动转化。只不过如果是前者那么相当于创建了一个C的变量b,Python导入的时候无法访问;如果是后者,那么相当于创建一个Python变量b,Python导入的时候可以访问。
举个例子:
cdef int a
b = &a
"""
cdef int a
b = &a
^
------------------------------------------------------------
1.pyx:5:4: Cannot convert 'int *' to Python object
Traceback (most recent call last):
"""
# 我们看到编译失败了,因为b是Python中的类型,而&a是一个int*,所以无法将int *转化成Python对象
再举个栗子:
cdef int a = 3
cdef int b = a
c = a
import mix
try:
print(mix.a)
except Exception as e:
print(e) # module 'mix' has no attribute 'a'
try:
print(mix.b)
except Exception as e:
print(e) # module 'mix' has no attribute 'b'
print(mix.c) # 3
我们看到a和b是C中的类型,无法访问,但变量c是可以访问的。不过问题又来了,看一下下面的几种情况:
先定义一个C的变量,然后给这个变量重新赋值
cdef int a = 3
a = 4
# Python中能否访问到a呢?
# 答案是访问不到的,虽说是a = 4,像是创建Python的变量,但是不好意思,上面已经创建了C的变量a
# 因此下面再操作a,都是操作C的变量a,如果你来一个a = "xxx",那么是不合法的。
# a已经是整型了,你再将一个字符串赋值给a显然不是合法的
先定义一个Python变量,再定义一个同名的C变量
b = 3
cdef int b = 4
"""
b = 3
^
------------------------------------------------------------
1.pyx:4:0: Previous declaration is here
warning: 1.pyx:5:9: cdef variable 'b' declared after it is used
"""
# 即使一个是Python的变量,一个是C的变量,也依旧不可以重名。不然访问b的话,究竟访问哪一个变量呢?
# 所以b = 3的时候,变量就已经被定义了。而cdef int b = 4又定义了一遍,显然是不合法的。
# 不光如此,cdef int c = 4之后再写上cdef int c = 5仍然是重复定义,不合法的。
# 但cdef int c = 4之后,写上c = 5是合法的,因为这相当于改变c的值,而没有重复定义。
先定义一个Python变量,再定义一个同名的Python变量
cdef int a = 4
v = a
print(v)
cdef double b = 3.14
v = b
print(v)
# 这么做是合法的,其实从Cython是Python的超集这一点就能理解。
# 主要是:Python中的变量的创建方式和C中变量的创建方式是不一样的,Python中的变量在C中是一个指针,而C中的变量就是值本身
# v = a相当于创建了一个指针v,指向a对应的值、或者说存储了a对应值的地址。在不涉及到Cython的时候,Python中变量可以指向任意的值
# 而一旦涉及到Cython,那么就不行了。
# 一个变量可以在Cython中出现(任意次)、也可以在Python中出现(任意次),只要符合相应的语法规范即可,但不可以既出现在Cython中又出现在Python中。
我们说Python int和C/C++ int之间是对应的,所以Python会自动转化,那么其它类型呢?Python类型和C/C++类型之间的对应关系都有哪些呢?

注意:这些是C的类型,但是Cython有更丰富的类型来表示。
bint类型
bint在C中是一个布尔类型,但其实本质上是一个整型,然后会自动转化为Python的布尔类型,当然Python中布尔类型也是继承自整型。bint类型有着标准C的实现:0为假,非0为真。
cdef bint flag1 = 123 # 非0是True
cdef bint flag2 = 0 # 0是False
a = flag1
b = flag2
>>> import mix # 这里编译的扩展模块还叫mix
>>> mix.a
True
>>> mix.b
False
>>>
整数类型转换与溢出
在Python2中,有int和long两种类型来表示整数。Python2中的int使用C中的long来存储,是有范围的,而Python2中的long是没有范围的;但在Python3中,只有int,没有long,而所有的int对象都是没有范围的。
将Python中的整型转化成C中的整型时,Cython生成代码会检测是否存在溢出。如果C中的long无法表示Python中的整型,那么运行时会抛出OverflowError。
i = 2 << 81 # 显然C中的int是存不下的
cdef int j = i
>>> import mix
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "fib.pyx", line 3, in init wrapper_fib
cdef int j = i
OverflowError: Python int too large to convert to C long
>>> # 我们看到int存不下会自动尝试使用long,如果还是越界则报错
float类型转换
Python中的float对应的值在C中也是用double来存储的,不过将Python的浮点转成C的浮点可能会出现0.0、正无穷、负无穷,根据IEEE 754规则进行转换。不过对于浮点来说,可以放心使用。
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
// Python中的对象在底层都是一个结构体,float对象则是一个PyFloatObject
// 而PyObject_HEAD是一些额外信息:引用计数、指向对应类型的指针
// 而是ob_fval则是真正存放具体的值的,显然这是一个double
复数类型
Python中的复数在C中是使用两个double来存储的,一个存储实部、一个存储虚部。
typedef struct {
double real;
double imag;
} Py_complex;
typedef struct {
PyObject_HEAD
Py_complex cval;
} PyComplexObject;
复数不常用,了解一下即可。
bytes类型、str类型
在Cython中我们如果想创建一个字节串可以使用bytes,而创建一个字符串则是str或者unicode。
# 创建一个字节串使用bytes
cdef bytes name = "古明地觉".encode("utf-8")
# 创建一个字符串可以使用str,和Python一样
cdef str where1 = "东方地灵殿"
# 也可以使用unicode,但是字符串要有前缀u,两种方式在Python3是等价的,因此建议使用str
# 之所以会有unicode是为了兼容Python2
cdef unicode where2 = u"东方地灵殿"
NAME = name
WHERE1 = where1
WHERE2 = where2
>>> from mix import NAME, WHERE1, WHERE2
>>> NAME, WHERE1, WHERE2
(b'xe5x8fxa4xe6x98x8exe5x9cxb0xe8xa7x89', '东方地灵殿', '东方地灵殿')
>>> # NAME自动是一个字节串,因为使用char *定义的,中文的话使用utf-8解码即可
>>> NAME.decode("utf-8")
'古明地觉'
>>> NAME.decode("utf-8")[2]
'地'
>>> WHERE1[: 2] + WHERE2[2:] # WHERE1和WHERE2同理
'东方地灵殿'
>>>
当然还有很多很多类型,别着急,我们在后续会慢慢介绍。
使用Python类型进行静态声明
我们之前使用cdef的时候用的都是C中的类型,比如cdef int、cdef float,当然Python中也有这两个,不过我们使用的确实是C中的类型,再或者cdef unsigned long long也是可以的。那么可不可以使用Python中的类型进行静态声明呢,其实细心的话会发现是可以的,因为我们上面使用了cdef str声明变量了。
不光是str,只要是在CPython中实现了,并且Cython有权限访问的话,都可以用来进行静态声明,而Python中内建的类型都是满足要求的。换句话说,只要在Python中可以直接拿来用的,都可以直接当成C的类型来进行声明。
# 我们看到可以使用str和bytes表示字节。但其实表示字节的话,除了可以使用Python中的bytes,也可以使用char *
# 比如cdef char *a = "古明地觉"
# 但是使用cdef char *的话,后面跟上字符串即可,不过不推荐这么做,因为理论上这是不合法的,如果你的编译器比较低级的话,那么或许会通过;
# 可面对高阶编译器的话,那么这是不允许的,会出现如下编译错误
# Unicode literals do not support coercion to C types other than Py_UNICODE/Py_UCS4 (for characters) or Py_UNICODE* (for strings)
# 除非给char *赋的字符串是ascii字符,比如:cdef char * = "hello"; 但如果里面出现了非ascii字符,在高阶编译器面前是不会通过的
# 因此如果要给char *赋上包含非ascii的字符串的话,一定要先转换成Python中的bytes,再赋值给char *
# 但是在后面我为了偷懒,将字符串赋值给char *了,这是错误的做法。你一定不要这么做
# 另外我们说Python代码可以直接写在Cython里面,那么它除了可以用于声明类型之外,也可以用来进行初始化
cdef tuple b = tuple("123")
cdef list c = list("123")
cdef dict d = {"name": "古明地觉"}
cdef set e = {"古明地觉", "古明地恋"}
cdef frozenset f = frozenset(["古明地觉", "古明地恋"])
A = a
B = b
C = c
D = d
E = e
F = f
>>> from mix import *
>>> A
'古明地觉'
>>> B
('1', '2', '3')
>>> C
['1', '2', '3']
>>> D
{'name': '古明地觉'}
>>> E
{'古明地觉', '古明地恋'}
>>> F
frozenset({'古明地觉', '古明地恋'})
>>>
我们看到得到的结果是正确的,完全可以当成Python中的类型来使用。这里在使用Python中的类型进行静态声明的时候,我们都赋上了一个初始值。但如果只是声明没有赋上初始值,那么得到的结果是一个None,注意:只要是用Python中的类型进行静态声明且不赋初始值,那么结果都是None。比如:cdef tuple b; B = b,那么Python在打印B的时候得到的就是None,而不是一个空元组。不过整型是个例外,因为int我们实际上用的是C里面int,会得到一个0,当然还有float。
为什么可以做到这一点呢?实际上这些结构在CPython中都是已经实现好了的,Cython将它们设置为指向底层中某个数据结构的C指针,比如:cdef tuple a,那么a就是一个PyTupleObject *,它们可以像普通变量一样使用,当然Python中的变量也是一样的,a = tuple(),那么a同样是一个PyTupleObject *。
同理我们想一下C扩展,我们使用Python/C api编写扩展模块的时候,也是一样的道理,只不过还是那句话,使用C来编写扩展非常的麻烦,因为用C来开发本身就是麻烦的事情。所以Cython帮我们很好的解决的这一点,让我们可以将写Python一样写扩展,会自动地将我们的代码翻译成C级的代码,因此从这个角度上讲,Cython可以做的,使用纯C来编写扩展也是完全可以做的。区别就是一个简单方便,一个麻烦。更何况使用C编写扩展,需要掌握Python/C api,而且还需要有Python解释器方面的知识,门槛还是比较高的,可能一开始掌握套路了还不觉得有什么,但是到后面当你使用C来实现一个Python中的类的时候,你就知道这是一件相当恐怖的事情了。而在Cython中,定义一个类仍然非常简单,像Python一样,我们后面会说,可能要等到之后的博客中才会说了。
另外使用Python中的类型声明变量的时候不可以使用指针的形式,比如:cdef tuple *t,这么做是不合法的,会报错:Pointer base type cannot be a Python object。此外,我们使用cdef的时候指定了类型,那么赋值的时候就不可以那么无拘无束了,比如:cdef tuple a = list("123")就是不合法的,因为声明了a是一个tuple,但是我们给了一个list,那么编译扩展模块的时候就会报错:TypeError: Expected tuple, got list。
这里再思考一个问题,我们说Cython创建的变量无法被直接访问,需要将其赋值给Python中的变量才可以使用。那么,在赋完值的时候,这两个变量指向的是同一个对象吗?
cdef list a = list("123")
# a是一个PyListObject *,然后b也是一个PyListObject *
# 但是这两位老铁是不是指向同一个PyListObject对象呢?
b = a
# 打印一下a is b
print(a is b)
# 修改a的第一个元素之后,再次打印b
a[0] = "xxx"
print(b)
>>> from mix import *
True
['xxx', '2', '3']
>>> # 我们看到a和b确实是同一个对象,并且a在本地修改了之后,会影响到b
>>> # 毕竟两个变量指向的是同一个列表、或者PyListObject结构体实例
>>> # 当然我们使用del删除一个元素也是同理。
我们说Cython中的变量和Python中的变量是等价的,那么Python中变量可以使用的api,Cython中的变量都可以使用,比如a.insert、a.append等等。只不过对于int和float来说,C中也存在同名的类型,那么会优先使用C的类型,这也是我们期望的结果。
而且一旦使用的C里面的类型,比如
cdef int = 1;cdef float b = 22.33,那么a和b就不再是PyLongObject *和PyFloatObject *了,因为它们用的不是Python中的类型,而是C中的类型,所以a和b的类型就是C中实打实的int和float。因此a和b也不再是一个指针,它们代表的就是具体的整数和浮点数。为什么要在使用int和float的时候,要默认选择C中int和float呢?答案很好理解,因为Cython本身就是用来加速计算的,而提到计算,显然避不开int和float,因此这两位老铁默认使用的C里面类型。事实上单就Python中的整型和浮点来说,在运算时底层也是先转化成C的类型,然后再操作,最后将操作完的结果再转回Python中的类型。而如果默认就使用C的类型,就少了转换这一步了,可以极大提高效率。
然而即便是C中的整型和浮点型,在操作的时候和C还是有一些不同的,主要就在于除法和取模。什么意思呢,我们往下看。
当我们操作的是Python的int时,那么结果是不会溢出的;如果操作的是静态的C对象,那么整型可能存在溢出。这些我们是知道的,但是除此之外,还有一个最重要的区别就是除法和取模,在除法和取模上,C的类型使用的却不是C的标准。举个栗子:
当使用有符号整数计算模的时候,C和Python有着明显不同的行为:比如-7 % 5,如果是Python的话那么结果为3,C的话结果为-2。显然C的结果是符合我们正常人思维的,但是为什么Python得到的结果这么怪异呢?
事实上不光是C,golang、js也是如此,计算
-7 % 5的结果都是-2,但Python得到3主要是因为其内部的机制不同。我们知道a % b,等于a - (a / b) * b,其中a / b表示两者的商。比如 7 % 2,等于7 - (7 / 2) * 2 = 7 - 3 * 2 = 1,对于正数,显然以上所有语言计算的结果都是一样的。而负数出现差异的原因就在于:C在计算a / b的时候是截断小数点,而Python是向下取整。比如上面的-7 % 5,等于 -7 - (-7 / 5) * 5。-7 / 5得到的结果是负的一点多,C的话直接截断得到-1,因此结果是 -7 - (-1) * 5 = -2,;但是Python是向下取整,负的一点多变成-2,因此结果变成了-7 - (-2) * 5 = 3
# Python中/默认是得到浮点,整除的话使用//
# 我们看到得到的是-2
print(-7 // 5) # -2
因此在除法和取模方面,尤其需要注意。另外即使在Cython中,也是一样的。
cdef int a = -7
cdef int b = 5
cdef int c1 = a / b
cdef int c2 = a // b
print(c1)
print(c2)
print(-7 // 5)
import mix
"""
-2
-2
-2
"""
我们看到得到的结果全部是-2,说明Cython默认使用Python的语义进行除法,当然还有取模,即使操作的对象是静态类型的C标量。这么做原因就在于为了最大程度的和Python保持一致,如果想要启动C语义都需要显式的进行开启。然后我们看到a和b是静态类型的C变量,它们也是可以使用//的,因为Cython的目的就像写Python一样。但是我们看到无论是a / b还是a // b得到的都是-2,这很好理解。因为在Cython中a和b都是静态的int,而在C中对两个int使用加减乘除得到的依旧是一个int。因此会将中间得到的浮点数变成整型,至于是直接截断还是向下取整则是和Python保持一致的,是按照Python的标准来的。至于a // b对于整型来说就更不用说了,a // b本身就表示整除,因此在Cython中两个int之间使用/和使用//是一样的。然后我们再来举个浮点数的例子。
cdef float a = -7
cdef float b = 5
cdef float c1 = a / b
cdef float c2 = a // b
print(c1)
print(c2)
import mix
"""
-1.399999976158142
-2.0
"""
此时的a和b都是浮点数,那么a / b也是个浮点,所以没有必要截断了,小数位会保留;而a // b虽然得到的也是浮点(只要a和b中有一个是浮点,那么a / b和a // b得到的也是浮点。),但它依旧具备整除的意义,所以a // b得到结果是-2.0,然后赋值给一个float变量,还是-2.0。不过为什么a // b得到的是-2.0,可能有人不是很明白,因此关于Python中/和//在不同操作数之间的差异,我们再举个栗子看一下:
7 / 2 == 3.5 # 3.5,很好理解
7 // 2 == 3 # //表示整除,因此3.5会向下取整,得到3
-7 / 2 == -3.5 # -3.5,很好理解
-7 // -2 = -4 # //表示取整,因此-3.5会向下取整,得到-4
7.0 / 2 == 3.5 # 3.5,依旧没问题
7.0 // 2 == 3.0 # //两边出现了浮点,结果也是浮点。但//又是整除,所以你可以简单认为是先取整(得到3),然后变成浮点(得到3.0)
-7.0 / 2 == -3.5 # -3.5,依旧很简单
-7.0 // 2 == -7.8 // 2 == -4.0 # -3.5和-3.9都会向下取整,然后得到-4,但结果是浮点,所以是-4.0
-7.0 / -2 == 3.5 # 3.5,没问题
-7.0 // -2 == 3 # 3.5向下取整,得到3
所以Python的整除或者说地板除还是比较奇葩的,主要原因就在于其它语言是截断(小数点后面直接不要了),而Python是向下取整。如果是结果为正数的话,截断和向下取整是等价的,所以此时基本所有语言都是一样的;而结果为负数的话,那么截断和向下取整就不同了,因为-3.14截断得到的是-3、但向下取整得到的不是-3,而是-4。因此这一点务必要记住,算是Python的一个坑吧。话说如果没记错的话,好像只有Python采用了向下取整这种方式,别的语言(至少C、js、golang)都是截断的方式。
还有一个问题,那就是整型和浮点型之间可不可以相互赋值呢?先说结论:
整型赋值给浮点型是可以的但是浮点型赋值给整型不可以
# 7是一个纯数字,那么它既可以在赋值int类型变量时表示整型数字7
# 也可以在赋值给float类型变量时表示7.0
cdef int a = 7
cdef float b = 7
# 但如果是下面这种形式,虽然也是可以的,但是会弹出警告
cdef float c = a
# 提示: '=': conversion from 'int' to 'float', possible loss of data
# 因为a的值虽然也是7,但它已经具有相应的类型了,就是一个int,将int赋值给float会警告
# 而将浮点型赋值给整型则会报错
# 这行代码在编译的时候是会报错的: Cannot assign type 'double' to 'int'
cdef int d = 7.0
而且我们说,使用cdef int、cdef float声明的变量类型不再是Python中的int、float或者CPython中的PyLongObject *、PyFloatObject *,而就是C中的int、float。尽管整型没有考虑溢出,但是它在做运算的时候遵循Python的规则(主要是除法),那么可不可以让其强制遵循C的规则呢?
cimport cython
# 通过@cython.cdivision(True)进行装饰即可完成这一点
@cython.cdivision(True)
def divides(int a, int b):
return a / b
import mix
print(-7 // 2) # -4
# 函数参数a和b都是整型,相除得到还是整型
# 如果是Python语义,那么在转化的时候会向下取整得到-4,但这里是C语义,所以是截断得到-3
print(mix.divides(-7, 2)) # -3
这里提一句:我们这里以及上面的import mix,mix是pyx编译之后的名字,好像之前就用了,只不过到现在一直没有改,所以理解就行,扩展模块的名字什么的无所谓的,只要遵循Python中变量的语法规范即可。
除了这种方式,还可以下面下面两种方式来指定。
1. 通过上下文管理器的方式
cimport cython
def divides(int a, int b):
with cython.cdivision(True):
return a / b
2. 通过注释的方式进行全局声明
# cython: cdivision=True
def divides(int a, int b):
return a / b
如果什么都不指定的话,执行一下看看。
def divides(int a, int b):
return a / b
import mix
print(-7 // 2) # -4
print(mix.divides(-7, 2)) # -4
此时就和Python语义是一样的了。
总结:
使用cdef int、cdef float声明的变量不再是Python中的int、float,也不再对应CPython中的PyLongObject *和PyFloatObject *,而就是C中的int和float。虽然是C中的int和float,并且也没有像Python一样考虑整型溢出的问题(实际上溢出的情况非常少,如果可能溢出的话,就不要使用C中的int),但是在进行运算的时候是遵循Python的语义的。因为Cython就是为了优化Python而生的,因此在各个方面都要和Python保持一致。但是也提供了一些方式,禁用掉Python的语义,而是采用C的语义。方式就是上面说的那三种,它们专门针对于整除和取模,因为加减乘都是一样的,只有除和取模会有歧义。
不过这里还有一个隐患,因为我们在除法的时候使其遵循C的语义,而C不会对分母为0的情况进行考虑,而Python则会进行检测。如果分母为0,在Python中会抛出:ZeroDivisionError,在C中会可能导致未定义的行为(从硬件损坏和数据损害都有可能,好吓人,妈妈我怕)。
Cython中还有一个cdivision_warnings,使用方式和cdivision完全一样,表示:当取模的时候如果两个操作数中有一个是负数,那么会抛出警告。
cimport cython
@cython.cdivision_warnings(True)
def mod(int a, int b):
return a % b
import mix
# -7 - (2 * -4) == 1
print(mix.mod(-7, 2))
# 提示我们取整操作在C和Python有着不同的语义, 同理mix.mod(7, -2)也会警告
"""
RuntimeWarning: division with oppositely signed operands, C and Python semantics differ
return a % b
1
"""
# -7 - (-2 * 3) = -1
print(mix.mod(-7, -2)) # -1
# 但是这里的mix.mod(-7, -2)却没有弹出警告,这是为什么呢?
# 很好理解,我们说只有商是负数的时候才会存在歧义,但是-7 除以 -2得到的商是3.5,是个正数
# 而正数的表现形式在截断和向下取整中都是一致的,所以不会警告
# 同理mix.mod(7, 2)一样不会警告
另外这里的警告是同时针对Python和C的,即使我们再使用一层装饰器@cython.cdivision(True)装饰、将其改变为C的语义的话,也一样会弹出警告的。个人觉得cdivision_warnings意义不是很大,了解一下即可。
用于加速的静态类型
我们上面介绍了在Cython中使用Python的类型进行声明,这咋一看有点古怪,为什么不直接使用Python的方式创建变量呢?a = (1, 2, 3)不香么?为什么非要使用cdef tuple a = (1, 2, 3)这种形式呢?答案是"为了遵循一个通用的Cython原则":我们提供的静态信息越多,Cython就越能优化结果。所以a = (1, 2, 3),这个a可以指向任意的对象。但是cdef tuple a = (1, 2, 3)的话,这个a只能指向元组,在明确了类型的时候,执行的速度会更快。
看一个列表的例子:
lst = []
lst.append(1)
我们只看lst.append(1)这一行,显然它再简单不过了,但是你知道Python解释器是怎么操作的吗?
1. 检测类型,我们说Python中变量是一个PyObject *,因为任何对象在底层都嵌套了PyObject这个结构体,但具体是什么类型则需要一步检索才知道。PyTypeObject *type = lst -> ob_type,拿到其类型。
2. 转化类型, PyListObject *lst = (PyListObject *)lst
3. 查找属性,我们调用的是append方法,因此调用PyObject_GetAttr,参数就是字符串"append",找到指向该方法的指针。如果不是list,但是内部如果有append方法也是可以的,然后通过PyObject_Call来进行调用。
因此我们看到一个简单的append,Python内部是需要执行以上几个步骤的,但如果我们实现规定好了类型呢?
cdef list lst = []
lst.append(1)
那么此时会有什么差别呢?我们对list对象进行append的时候底层调用的C一级的函数是PyList_Append,通过索引赋值的时候调用的是PyList_SetItem,索引取值的时候调用的是PyList_GetItem,等等等等。每一个操作在C一级都指向了一个具体的函数,如果我们提前知道了类型,那么Cython生成的代码可以将上面的三步变成一步,没错,直接通过C api让lst.append指向PyList_Append这个C一级的函数,这样省去了类型检测、转换、属性查找等步骤,直接调用调用即可。
那么Cython都允许我们使用哪些类型呢?几乎内置的类型都可以
比如:type、object、bool(这个之前忘记说了,我们除了使用bint,使用bool也是可以的)、complex、str、bytes(也可以使用char *)、bytesarray、list、tuple、dict、set、frozenset、slice。这些类型都是可以直接接在cdef关键字后面,用来进行变量声明的。
但是上面没有包含int和float,原因我们解释过了,并不是不能用,只不过用的时候它们不是Python的类型而是C的类型。而且事实上在Cython中静态声明和使用PyLongObject和PyFloatObject并不简单,但幸运的是我们不需要这么做,而是使用C中的int、long、float、double,然后让Cython自动帮我们转化即可。
但是实际上,基本是不建议使用cdef int和cdef float的,而是使用cdef long和cdef double,因为int能存储的值太小了
(存不下会自动像long扩展),而PyFloatObject中存储实际的值使用的是double(使用cdef float会面临丢失精度问题)。虽然int和long、float和double是一定程度上等价的,但是为了保证和Python的最大兼容还是建议只使用cdef long和cdef double。此外,Cython实际上是一种与语言无关的方式在C整型和Python整型之间进行转换,并且在无法转换的时候引发溢出错误。
此外,当我们在Cython中处理Python对象的时候,无论是静态声明的,还是静态声明的,Cython都负责帮我们进行内存方面的管理。
但是除了上面那些内置的之外,还支持:array、date、time、datetime、timedelta、tzinfo,它们可不能直接跟在cdef后面进行变量声明哦,至于怎么用,我们后面会慢慢说。
下面我们来深入一下Python解释器相关的内容,有兴趣的可以看看,没有兴趣的话可以跳到下一个主题
我们上面在介绍Python中的列表进行append的时候发生了3步,在第3步 查找属性的时候我们说会调用PyObject_GetAttr,找到指向该方法的指针。那么这个指针指向的是什么呢?我们下面来深入分析一下。
事实上该指针指向的是一个结构体,结构体内部存放了指向了"真正用来执行添加元素逻辑的函数"的指针,不过这里的函数指的不是C中的函数,而是Python中的函数、即PyFunctionObject,当然PyFunctionObject也是一个结构体,内部存储了指向C中函数的指针(禁止套娃)。
可为什么调用PyObject_GetAttr得到的指针指向的是一个结构体,而不是直接指向相应的PyFunctionObject的指针呢?带着这个问题,我再抛出一个问题,都说实例在调用方法的时候会自动传递self,为什么会自动传递呢?所以两个问题一块思考是不是有答案了呢?没错,指针指向的结构体内部,除了有指向执行具体的逻辑的函数的指针之外,还有一个参数叫做im_self。
这里说一句Python中的函数和方法,我们定义一个函数的时候就是一个普通的函数,在Python中是
<class 'function'>、底层是PyFunctionObject,当然我们获取函数的时候拿到的是其指针;如果是在类里面定义一个函数的话,那么当类访问的时候得到的依旧是指向PyFunctionObject的指针、也就是类去访问得到是函数;但是当实例访问的时候就不是函数了,而是方法。本来实例访问的时候,其实得到的也是一个PyFunctionObject *,但是Python会对其进行一步封装,将这个PyFunctionObject *封装成PyMethodObject,然后返回其指针。
我们看一下方法、或者说PyMethodObject在底层中的定义是什么吧。
//classobject.h
typedef struct {
PyObject_HEAD
//可调用的PyFunctionObject对象
PyObject *im_func; /* The callable object implementing the method */
//用于成员函数调用的self参数,instance对象
PyObject *im_self; /* The instance it is bound to */
//弱引用列表
PyObject *im_weakreflist; /* List of weak references */
} PyMethodObject;
PyObject_HEAD:一个宏,等价于定义了一个PyObject。因为Python中一切皆对象,都有引用计数和类型。方法的类型是什么,显然是<class 'type'>、即PyType_Type。im_func:指向PyFunctionObject结构体的指针,我们说这个PyFunctionObject内部又存储了一个函数指针,这个函数指针指向真正执行append操作的C一级的函数。既然PyFunctionObject对应Python中函数,那么这个PyFunctionObject中除了指向指向某个函数的指针之外还有什么呢?想都不用想,肯定还有PyObject。im_self:咦,self,你想到了啥?不用说,各位都是Python老千层饼了,肯定都懂的。im_weakreflist:弱引用列表,这个不用管,不是我们所关心的。
我们看到,当访问函数的时候,如果是类访问,那么调用的就是一个PyFunctionObject *,如果是实例访问,那么会进行封装、因此得到的是一个PyMethodObject *。然后在调用的时候会将内部的im_self作为第一个参数传递给指向的PyFunctionObject。
那么这是怎么实现的呢?答案是通过描述符来实现的,是的你没有看错,是通过描述符。
//funcobject.c
static PyObject *
func_descr_get(PyObject *func, PyObject *obj, PyObject *type)
{
if (obj == Py_None || obj == NULL) {
Py_INCREF(func);
return func;
}
// 调用了PyMethod_New
return PyMethod_New(func, obj);
}
//classobjet.c
PyObject *
PyMethod_New(PyObject *func, PyObject *self)
{
//接收两个指针,一个指向函数,一个指向实例对象
//我们看到在解释器的实现中,实例对象使用的变量名就叫self,所以我们在定义的时候第一个参数也是self
//当然不是self也可以,只是为了保持一种规范,也叫作self
//声明一个PyMethodObject *
PyMethodObject *im;
if (self == NULL) {
PyErr_BadInternalCall();
return NULL;
}
im = free_list;
if (im != NULL) {
//这里是使用缓冲池计数,Python中的一些对象在引用计数为0的时候,并不一定是直接回收所占内存
//而是通过缓冲池技术存储起来,再次申请的时候可以直接拿来用,从而提高效率。tuple、list对象也都有缓冲池
free_list = (PyMethodObject *)(im->im_self);
// 给其绑定一个指针,指向具体的类型,显然类型就是PyMethod_Type
// 所以PyMethodObject的类型是PyMethod_Type,在Python中使用type查看一个方法的类型得到的正是一个<class 'method'>
// 而PyMethod_Type的类型是啥呢?显然是PyType_Type,因此Python中<class 'method'>的类型就是<class 'type'>
(void)PyObject_INIT(im, &PyMethod_Type);
//使用之后,缓冲池内可使用数量减一
numfree--;
}
else {
//不使用缓冲池,直接创建PyMethodObject对象
im = PyObject_GC_New(PyMethodObject, &PyMethod_Type);
if (im == NULL)
return NULL;
}
im->im_weakreflist = NULL;
//增加引用计数
Py_INCREF(func);
//让im内部的成员im_func等于传递的func
im->im_func = func;
//增加引用计数
Py_XINCREF(self);
//让im内部的im_self指向self
im->im_self = self;
_PyObject_GC_TRACK(im);
//转成PyMethodObject *,然后返回
return (PyObject *)im;
}
所以目前的流程就很清晰了,如果是实例访问函数,那么会先调用描述符func_descr_get,将实例访问得到的PyFunctionObject *通过PyMethod_New进行了一个封装。而封装的结果就是:python虚拟机在im_func和im_self的基础上创建一个新的对象PyMethodObject
(当然返回的还是它的指针,因为Python中的变量在C中就是一个指向某个结构体的指针),从而将函数和实例绑定在了一起。调用PyFunctionObject的时候相当于调用的是PyMethodObject,而在调用PyMethodObject的时候,会自动将im_self作为第一个参数传递给PyFunctionObject,所以为什么实例调用方法的时候会自动传递第一个参数现在是真相大白了。
class A:
def foo(self): pass
# 类访问是一个函数
print(type(A.foo)) # <class 'function'>
# 实例访问,我们说会将得到的函数封装成方法
print(type(A().foo)) # <class 'method'>
# 方法和函数的类型都是type, 但是这两个类的接口解释器没有暴露给我们,因此需要调用两次type
print(type(type(A.foo))) # <class 'type'>
print(type(type(A().foo))) # <class 'type'>
这里稍微扯得有点远,但是了解一下总归是好的。
引用技术和静态字符串类型
我们知道Python会自动管理内存的,解释器CPython通过直接的引用计数来判断一个对象是否应该被回收,但是无法解决循环引用,于是Python中又提供了垃圾回收来解决这一点。
这里多提一句Python中的gc,我们知道Python判断一个对象回收的标准就是它的引用计数是否为0,为0就被回收。但是这样无法解决循环引用,于是Python中的gc就是来解决这个问题的。那么它是怎么解决的呢?
首先什么样的对象会发生循环引用呢?不用说,显然是可变对象,比如:列表、类的实例对象等等,像int、str这些不可变对象肯定是不会发生循环引用的,单纯的引用计数足以解决。
而对于可变对象,Python会通过分代技术,维护三个链表:零代链表、一代链表、二代链表。将那些可变对象移到链表上,然后通过三色标记模型找到那些发生循环引用的对象,将它们的引用计数减一,从而解决循环引用的问题。不过有人好奇了,为什么是三个链表,一个不行吗?事实上,Python检测循环引用、或者触发一次gc还是要花费一些代价的,对于某些经过gc的洗礼之后还活着的对象,我们认为它们是比较稳定的,不应该每次触发gc就对它们进行检测。所以Python会把零代链表中比较稳定的对象移动到一代链表中,同理一代链表也是如此,不过最多就是二代链表,没有三代链表。当清理零代链表的次数达到10次的时候,会清理一次一代链表;清理一代链表达到10次的时候,会清理一次二代链表。
而Cython也为我们处理所有的引用计数问题,确保Python对象(无论是Cython动态声明、还是Python动态声明)在引用计数为0时被销毁。
很好理解,就是内存管理的问题Cython也会负责的。其实不用想也大概能猜到Cython会这么做,毕竟
cdef tuple a = (1, 2, 3)和a = (1, 2, 3)底层都对应PyTupleObject *,只不过后者在操作的时候需要先通过PyObject *获取类型(PyTupleObject *)再转化罢了,而前者则省略了这一步。但它们底层都是CPython中的结构体,所以内存都由解释器管理。还是那句话,Cython代码是要被翻译成C的代码的,在翻译的时候会自动处理内存的问题,当然这点和Python也是一样的。正如我们之前说的,手动通过Python/C api来编写扩展也是可以的。只不过需要我们来考虑内存方面的问题,判断引用计数是加1还是减1,然后通过提供的操作引用计数的api进行实现,因此会比较麻烦罢了。而Cython也可以很方便的让我们编写扩展,并且还不需要我们关心内存管理方面的问题。
但是当Cython中动态变量和静态变量混合时,那么内存管理会有微妙的影响。我们举个栗子:
# 我们说针对char *,后面只能跟一个普通的非ascii字符串,所以下面这种方式是编译不过去的
cdef char *name = "古明地觉".encode("utf-8")
# 为什么会编译不过,原因就在于,encode之后就是Python中的bytes对象。
# 然后这行代码表示的就是提取该对象的char指针,然后赋值给name。
# 但是我们看到这个bytes对象它是一个临时对象,什么是临时对象呢?就是创建完了但是没有变量指向它
# 这里的name是使用C的类型创建的变量,所以它不会增加这个bytes对象的引用计数。
# 所以这个bytes对象创建出来之后就会被销毁。因此Cython会抛出:Storing unsafe C derivative of temporary Python reference
# 告诉我们创建出来的Python对象是临时的
# 而如果是cdef char *name = "satori",这种方式是可以的,因为此时"satori"会被当成是C中的字符串
# 同理cdef int a = 123;这个123也是C中的整型,但cdef char *name = "古明地觉"则不行,因为它不是ascii字符。
那么如何解决这一点呢?答案是使用变量保存起来就可以了
# 这种做法是完全合法的,因为我们这个bytes对象是被name1指向了
name1 = "古明地觉".encode("utf-8")
cdef char *buf1 = name1
# 然鹅这么做是不行的,编译是通过的,但是执行的时候会报错:TypeError: expected bytes, str found
name2 = "satori"
cdef char *buf2 = name2
# 可能有人觉得,cdef char *buf2 = "satori"就可以,为什么赋值给一个变量就不行了。
# 因此char *它需要接收的是C中的字符串,或者Python中的bytes
cdef char *buf = "satori".encode("utf-8")理论上是合理的,但是由于这个对象创建完之后就被销毁,所以不行。这个是在编译的时候就会被检测到,因为这属于内存方面的问题。cdef char *buf = "satori"是可以的,因为此时"satori"会被解释成C中的字符串。name = "古明地觉".encode("utf-8"); cdef char *buf = name也可以的,因为name指向了字节对象,所以不会被销毁,能够提取它的char指针name = "satori"; cdef char *buf = name则不行,原因在于我们将"satori"赋值给了name,那么这个name显然就是Python中的字符串,而我们不可以将Python中的字符串赋值给C中的char *,只能赋字节,因此会报错。但该错误是属于赋值出错了,因为它是一个运行时错误,编译成扩展模块的时候是可以正常编译通过的。
不过还是那句话,只有当直接给char *变量赋一个ascii字符串的时候,才会被当成是C中的字符串,如果赋了非ascii字符串、或者是ascii字符串但是用变量接收了并且赋的是变量,那么也是不合法的。因此建议,字符串直接使用str即可。
那么下面的代码有没有问题呢?如果有问题该怎么改呢?
word1 = "hello".encode("utf-8")
word2 = "satori".encode("utf-8")
cdef char *word = word1 + word2
会不会出问题呢?显然会有大问题,尽管word1和word2指向了相应的字节,但是word1 + word2则是会创建一个新的字节对象,这个新的字节对象可没有人指向。因此提取其char *之后也没用,因为这个新创建的字节对象会被直接销毁。
解决的办法有两种:
tmp = word1 + word2; cdef char *word = tmp,使用一个动态的方式创建一个变量指向它,确保它不会被销毁。cdef bytes tmp = word1 + word2; cdef char *word = tmp,道理一样,只不过使用的是静态声明的方式。
另外,其实像上面这种情况并不常见,基本上只有char *会有这个问题,因为它比较特殊,底层使用一个指针来表示字符串。和int不同,cdef long a = 123,这个123直接就是C中的int,我们可以直接使用;同理赋值为字符串的时候,这个字符串如果是C的字符串也可以大胆使用,但是你不能使用Python的字符串(换句话说,就是先赋值给Python中的变量,再将这个变量赋值给char *),但显然这很不方便,总不能先把字符串打印一下看看是什么,然后再贴上去赋值吧。所以我们可以通过将Python中的bytes对象赋值给char *来实现这一点,但是在C的级别char *所引用的数据还是由CPython进行管理的,char *缓冲区无法告诉解释器还有一个对象(非Python对象)引用它,这就导致了它的引用计数不会加1,而是创建完之后就会被销毁。
所以我们需要提前使用Python中的变量将其保存起来,这样就不会删除了。而我们说只有char *会面临这个问题,而其它的则无需担心。
Cython的函数
我们上面所学的关于动态变量和静态变量的只是也适用于函数。Python的函数和C的函数都有一些共同的属性:函数名称、接收参数、返回值,但是Python中的函数更加的灵活这强大。因为Python中一切皆对象,所以函数也是一等公民,可以随意赋值、并具有相应的状态和行为,这种抽象是非常有用的。
一个Python函数可以:
在导入时和运行时动态创建使用lambda关键字匿名创建在另一个函数(或其它嵌套范围)中定义从其它函数中返回作为一个参数传递给其它函数使用位置参数和关键字参数调用函数参数可以使用默认值
C函数调用开销最小,比Python函数快几个数量级。一个C函数可以:
可以作为一个参数传递给其它函数,但这样做比Python麻烦的多不能在其它函数内部定义,而这在Python中不仅可以、而且还非常常见,毕竟Python中常用的装饰器就是通过高阶函数加上闭包实现的,而闭包则可以理解为是函数的内部嵌套其它函数。具有不可修改的静态分配名称只能接受位置参数函数参数不支持默认值
正所谓鱼和熊掌不可兼得,Python的函数调用虽然慢几个数量级、即使没有参数,但是它的灵活性和可扩展性都比C强大很多,这是以效率为代价换来的。而C的效率虽然高,但是灵活性没有Python好。这便是各自的优缺点。
说完Python函数和C函数各自的优缺点之后该说啥啦,对啦,肯定是Cython如何将它们组合起来、吸取精华剔除糟粕的啦,阿sir。
在Cython中使用def关键字定义Python函数
Cython支持使用def关键字定义一个通用的Python函数,并且还可以按照我们预期的那样工作。比如:
def rec(n):
if n == 1:
return 1
return n * rec(n - 1)
编译文件,文件名改一下,不叫mix了,就要cython_test吧。
>>> import cython_test
>>> dir(cython_test)
['__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '__test__', 'rec']
>>> cython_test.rec(20)
2432902008176640000
>>>
显然这是一个Python语法的函数,参数n是接收一个动态的Python变量,但它在Cython中也是合法的,并且表现形式是一样的。
我们知道即使是普通的Python函数,我们也可以通过cython进行编译,但是就调用而言,这两者是没有任何区别的。不过我们说执行扩展里面的代码时,已经绕过了解释器解释字节码这一过程;但是Python代码则不一样,它是需要被解释执行的,因此在运行期间可以随便动态修改内部的属性。我们举个栗子就很清晰了:
Python版本:
# 文件名:a.py
def foo():
return 123
# 另一个文件
from a import foo
print(foo()) # 123
print(foo.__name__) # foo
foo.__name__ = "哈哈"
print(foo.__name__) # 哈哈
我们看到可以动态修改内部的一些属性啥的,但是对于Cython,由于编译之后的扩展模块已经绕过了解释器解释这一步,所以我们就不能再像上面那样了。
Cython版本:
def foo():
return 123
将上面的pyx文件进行编译
>>> from cython_test import foo
>>> foo()
123
>>> foo.__name__
'foo'
>>> foo.__name__ = "哈哈"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: attribute '__name__' of 'builtin_function_or_method' objects is not writable
我们看到报错了:'builtin_function_or_method'的属性'_name__'不可写。因为Python中的函数是一个类型函数,它是通过解释器的,所以它可以修改自身的一些属性。但是Cython代码在编译之后,变成了builtin_function_or_method,绕过了解释这一步,因为不能对它自身的属性进行修改。事实上,Python的一些内置函数也是不能修改的。
try:
getattr.__name__ = "xxx"
except Exception as e:
print(e) # attribute '__name__' of 'builtin_function_or_method' objects is not writable
这些内置的函数直接指向了底层C一级的函数,因此它们的属性是不能够被修改的。
回到刚才的用递归计算阶乘的例子上来,显然rec函数里面的n是一个动态变量,如果想要加快速度,就要使用静态变量,也就是规定好类型。
def rec(long n):
if n == 1:
return 1
return n * rec(n - 1)
此时当我们传递的时候,会将值转成C中的long,如果无法转换则会抛出异常。
另外在Cython中定义任何函数,我们都可以将动态类型的参数和静态类型的参数混合使用。Cython允许静态参数具有默认值,并且可以按照位置参数或者关键字参数的方式传递。
但是遗憾的是,即便我们使用了long n这种形式定义参数,效率也不会有提升。因为这里的rec还是一个Python函数,它的返回值也是一个Python中的整型,而不是静态的C long。因此在计算n * rec(n - 1)的时候,Cython必须生成大量代码,从返回的Python整数中提取底层的C long,然后乘上静态类型的变量n,最后再将结果得到的C long打包成Python的整型。所以整个过程基本上是没什么变化的。
那么如何才能提升性能呢?显然这明显可以不适用递归而是使用循环的方式,当然这个我们不谈,因为这个Cython没啥关系。我们想做的是告诉Cython:"这是一个C long,你要在不创建任何Python整型的情况下计算它,我会将你最终计算好的结果包装成Python中的整型,总之你计算的时候不需要Python整数参与。"
如何完成呢?往下看。
在Cython中使用cdef关键字定义C函数
cdef关键字除了创建变量之外,还可以创建具有C语义的函数。cdef定义的函数其参数和返回值通常都是静态类型的,它们可以处理C指针、结构体、以及其它一些无法自动转换为Python类型的C类型。所以把cdef定义的函数看成是长得像Python函数的C函数即可。
cdef long rec(long n):
if n == 1:
return 1
return n * rec(n - 1)
我们之前的例子就可以改写成上面这种形式,我们看到结构非常相似,主要区别就是指定了返回值的类型。
但是此时的函数是没有任何Python对象参与的,因此不需要从Python类型转化成C类型。该函数和纯C函数一样有效,调用函数的开销最小。另外,即便是cdef定义的函数,我们依旧可以创建Python对象和动态变量,或者接收它们作为参数也是可以的。但是cdef编写的函数应该是在,为了获取C的效率其不需要Python对象参数的情况下编写的。
当然我们在Cython源文件中可以使用cdef定义函数、也可以是用def定义函数,这是显然的。cdef函数返回的类型可以是任何的静态类型(如:指针、结构体、C数组、静态Python类型)。如果省略的返回值,那么默认是object( 比如:cdef f1():等价于cdef object f1() ),也就是说此时返回任何对象都是可以的。关于返回值的问题,我们来举个例子。
# 合法,返回的是一个list对象
cdef list f1():
return []
# 等于cdef object f2():,而Python中任何对象都是object对象
cdef f2():
pass
# 虽然要求返回列表,但是返回None也是可以的
cdef list f3():
pass
# 同样道理
cdef list f4():
return None
# 这里是会报错的:TypeError: Expected list, got tuple
cdef list f5():
return 1, 2, 3
使用cdef定义的函数,可以被其它的函数(cdef和def都行)调用,但是Cython不允许从外部Python代码来调用cdef函数,我们之前使用cdef定义的变量也是如此。因为Python中函数也可以看成是变量,所以我们通常会定义一个Python中的函数,然后让Python中的函数来调用cdef定义的函数。
cdef long _rec(long n):
if n == 1:
return 1
return n * rec(n - 1)
def rec(n):
return _rec(n)
这种方式是最快的,之前的方式都有大量的Python开销。
但不幸的时,这种方式有一个弊端,相信肯定都能想到。那就是C中的long存在精度问题,而Python的整型是不受限制的,只要你的内存足够。解决办法就是确保不会溢出,或者将long换成double。
这是一个很普遍的问题,基本上所有的语言都是这样子,只有Python在表示整型的时候是没有限制的。有些时候,Python数据和C数据并不能总是实现完美的映射,需要意识到C的局限性。这也是为什么Cython不会擅自把Python中的int变成C中的long,因为这两者在极端情况下不是等价的。但是绝大多数情况下,使用long是足够的,至少我平时很少遇见long存不下的数字。或者实在不行就用double嘛。
使用cpdef结合def、cdef
我们在Cython定义一个函数可以使用def和cdef,但是还有第三种定义函数的方式,使用cpdef关键字声明。cpdef是def和cdef的混合体,结合了这两种函数的特性,并解决了局限性。我们之前使用cdef定义了一个函数_rec,但是它没法直接被外部访问,因此又定义了一个Python函数rec供外部调用,相当于提供了一个接口。所以我们需要定义两个函数,一个是用来执行逻辑的(C版本),另一个是让外部访问的(Python版本,一般这种函数我们称之为Python包装器。很形象,C版本不能被外部访问,因为定义一个Python函数将其包起来)。
但是cpdef定义的函数会同时具备这两种身份,怎么理解呢?一个cpdef定义的函数会自动为我们提供上面那两个函数的功能,它们具备相同的名称。从Cython中调用函数时,会调用C的版本,在外部的Python中导入并访问时,会调用包装器。这样的话,cpdef函数就可以将cdef函数的性能和def函数的可访问性结合起来了。
因此上面那个例子,我们就可以改写成如下:
cpdef long rec(long n):
if n == 1:
return 1
return n * rec(n - 1)
如果定义两个函数,这两个函数还不能重名,但是使用cpdef就不需要关心了,这样可有达到更高的效率。
inline cdef and cpdef functions
在C和C++中,在定义函数时还可以使用一个可选的关键字inline,这个inline是做什么的呢?我们知道函数调用是有开销的(话说你效率这么高了,还在乎这一点啊),而使用inline关键字定义的函数,那么代码会被放在符号表中,在使用时直接进行替换(像宏一样展开),没有了调用的开销,提高效率。
Cython同样支持inline关键字,使用时只需要将inline放在cdef或者cpdef后面即可,但是不能放在def后面。
cpdef inline unsigned long rec(int n):
if n == 1:
return 1
return rec(n - 1) * n
>>> import cython_test
>>> cython_test.rec(20)
2432902008176640000
>>>
inline如果使用得当,那么可以提高性能,特别是在深度嵌套循环中调用的小型内联函数。
使用cpdef有一个局限性,那就是它要同时兼容Python和C:意味着它的参数和返回值类型必须同时兼容Python类型和C类型。但我们知道,并非所有的C类型都可以用Python类型表示,比如:C指针、void、C数组等等,它们不可以作为cpdef定义的函数的参数类型和返回值类型。
函数和异常处理
def定义的函数在C的级别总是会返回一个PyObject*,这个是恒定的不会改变,因为Python中的所有变量在底层都是一个PyObject *。它允许Cython正确地从def函数中抛出异常,但是cdef和cpdef可能会返回一个非Python类型,因此此时则需要一些其它的异常提示机制。
cpdef int divide_ints(int i, int j):
return i / j
如果这里的j我们传递了一个0,会引发ZeroDivisionError,但是这个异常却没有办法传递给它的调用方。
>>> import cython_test
>>> cython_test.divide_ints(1, 1)
1
>>> cython_test.divide_ints(1, 0)
ZeroDivisionError: integer division or modulo by zero
Exception ignored in: 'cython_test.divide_ints'
ZeroDivisionError: integer division or modulo by zero
0
>>>
异常没法传递,换句话说就是异常没有办法向上抛,即使检测到了这也异常。会忽略警告信息,并且也会返回一个错误的值0。
为了正确传递此异常,Cython提供了一个except字句,允许cdef、cpdef函数和调用方通信,说明在执行中发生了、或可能发生了Python异常。
cpdef int divide_ints(int i, int j) except? -1:
return i / j
>>> import cython_test
>>> cython_test.divide_ints(1, 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "1.pyx", line 1, in cython_test.divide_ints
cpdef int divide_ints(int i, int j)except?-1:
File "1.pyx", line 2, in cython_test.divide_ints
return i / j
ZeroDivisionError: integer division or modulo by zero
>>>
我们看到此时异常被正常的传递给调用方了,此时程序就崩溃了,而之前那种情况程序是没有崩溃的。
这里我们实现的方式是通过在结尾加上except ? -1来实现这一点,这个except ? -1允许返回值-1充当发生异常时的哨兵。事实上不仅是-1,只要在返回值类型的范围内的任何数字都行,它们的作用就是传递异常。但是问题来了,如果函数恰好就返回了-1的时候该怎么办呢?看到except ? -1中的那个问号了吗,它就是用来做这个的,如果函数恰好返回了一个-1,那么Cython会检测是否有异常回溯栈,有的话会自动展开堆栈。如果我们将那个问号去掉,看看会有什么结果吧。
cpdef int divide_ints(int i, int j) except -1:
return i / j
>>> import cython_test
>>> cython_test.divide_ints(1, 1)
1
>>>
>>> cython_test.divide_ints(1, 0) # 依旧会引发异常,这没问题
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "1.pyx", line 1, in cython_test.divide_ints
cpdef int divide_ints(int i, int j)except-1:
File "1.pyx", line 2, in cython_test.divide_ints
return i / j
ZeroDivisionError: integer division or modulo by zero
>>>
>>> cython_test.divide_ints(1, -1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
SystemError: <built-in function divide_ints> returned NULL without setting an error
如果你使用C编写过扩展模块的话,你应该会遇见过这个问题。Python中的函数总会有一个返回值的,所以在C中一定会返回一个PyObject *。如果Python中的函数出错了,那么在C一级就会返回一个NULL,并且将发生异常设置进去。如果返回了NULL但是没有设置异常的话,就会抛出上面的那个错误。而我们这里的except -1表示返回了-1就代表发生异常了、底层会返回NULL,但是此时却没有异常,所以提示我们returned NULL without setting an error。
所以我们看到except ? -1只是单纯为了在发生异常的时候能够往上抛罢了,这里可以是-1、也可以是其它的什么值。而函数如果也返回了相同的值,那么就会检测异常回溯栈,没有报错就会正常返回。而触发检测的条件就是中的那个?,如果不指定?,那么当函数返回了和except指定的相同的值,那么是会报错的,因此这个时候你应该确保函数不可能会返回except后面指定的值。所以尽管加上了?会牺牲一些效率(因为涉及回溯栈的展开,但实际上是没有什么差别的),但如果你没有百分之百的把握确定函数不会返回相同的值,那么就使用?做一层检测吧。或者还可以使用except *,此时会对返回的任何值都进行检测,但没有什么必要、会产生开销,直接写上except ? -1即可。这样只对-1进行检测,因为我们的目的是能够在发生异常的时候进行传递。
另外只有返回值是C的类型,才需要指定except ? -1
cpdef tuple divide_ints(int i, int j):
a = i / j
这个时候即使给j传递了0,异常也是会向上抛的,因为返回值不再是C中的类型,而是Python中的类型;如果将这里tuple改成int之后异常还是会被忽略掉的。
因此,在不指定
except ? -1的情况下,异常不会向上抛需要满足两个条件:1. 必须是C中的对象在操作时发生了错误,这里是i和j相除发生了错误;2. 返回值必须是C中的类型。
关于扩展模块中的函数信息
一个函数可以有很多信息,我们可以通过函数的字节码进行获取。
def foo(a, b):
pass
print(foo.__code__.co_varnames) # ('a', 'b')
import inspect
print(inspect.signature(foo)) # (a, b)
但是对于扩展模块中的函数就不能这样获取了,以上面的扩展模块为例。
>>> import cython_test
>>> cython_test.divide_ints.__code__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'builtin_function_or_method' object has no attribute '__code__'
>>> inspect.signature(cython_test.divide_ints)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib64/python3.6/inspect.py", line 3065, in signature
return Signature.from_callable(obj, follow_wrapped=follow_wrapped)
File "/usr/lib64/python3.6/inspect.py", line 2815, in from_callable
follow_wrapper_chains=follow_wrapped)
File "/usr/lib64/python3.6/inspect.py", line 2273, in _signature_from_callable
skip_bound_arg=skip_bound_arg)
File "/usr/lib64/python3.6/inspect.py", line 2097, in _signature_from_builtin
raise ValueError("no signature found for builtin {!r}".format(func))
ValueError: no signature found for builtin <built-in function divide_ints>
>>>
>>> cython_test.divide_ints.__file__
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'builtin_function_or_method' object has no attribute '__file__'
我们看到扩展模块内的函数变成built-in级别的了,所以一些动态信息已经没有了,即便有也是无法动态修改的,比如之前说的__name__。因为信息的访问、动态修改都是在解释器解释执行的时候完成的,而扩展模块已经是不需要解释、直接拿来执行就可以,已经是终极形态,所以不像常规定义的Python函数,扩展模块内的函数的动态信息是不支持动态修改的,有的甚至无法访问。
既然这样的话,那我如何才能将函数信息体现出来呢?答案是通过docstring。
cpdef int divide_ints(int i, int j) except ? -1:
"""
:param i: 第一个整型i
:param j: 第二个整型j
:return: i和j相除
"""
return i / j
>>> import cython_test
>>> cython_test.divide_ints.__doc__
'
:param i: 第一个整型i
:param j: 第二个整型j
:return: i和j相除
'
>>>
由于终端打印的格式问题,显示在了一行,但是我们看到__doc__是可以获取的,因此我们可以通过注释来传达信息。
类型转换
C和Python在数值类型上都有各自的成熟规则,但是这里我们介绍的是C类型,因为Cython使用的是C类型。
类型转换在C中很常见,尤其是指针,Cython也提供了相似的操作。
# 这里是将其它类型的指针变量v转成了int *
cdef int *ptr_i = <int *>v
# 在C中,类似于int *ptr_i = (int *)v,只不过小括号变成尖括号
显示的转换在C中是不被检测的,因此可以对类型进行完全的控制
def print_address(a):
cdef void *v = <void*>a
cdef long addr = <long>v
print "Cython address:", addr
print "Python id :", id(a)
>>> import cython_test
>>> cython_test.print_address("古明地觉")
Cython address: 140341186033432
Python id : 140341186033432
>>>
>>> cython_test.print_address([])
Cython address: 140341057249224
Python id : 140341057249224
>>>
这里传递的对象显然是一个PyObject *,然后这里先转成void *,此时v肯定是一个地址,然后再转成long,将地址使用十进制表示,这一点和内置函数id做的事情是相同的。
我们也可以对Python中的类型进行强制转换,转换之后的类型可以是内置的、也可以是我们自己定义的,来看比较做作的例子。
def func(a):
cdef list lst1 = list(a)
print(lst1)
print(type(lst1))
cdef list lst2 = <list> a
print(lst2)
print(type(lst2))
>>> import cython_test
>>> cython_test.func("123")
['1', '2', '3']
<class 'list'>
123
<class 'str'>
>>>
>>>
>>> cython_test.func((1, 2, 3))
[1, 2, 3]
<class 'list'>
(1, 2, 3)
<class 'tuple'>
我们看到使用list(a)转换是正常的,但是<list> a则没有实现转换,还是原本的类型。这里的<list>作用是接收一个列表然后将其转化为静态的列表,换句话说就是将PyObject *转成PyListObject *。如果接收的不是一个list,那么会转换失败。在早期的Cython中会引发一个SystemError,但目前不会了,尽管这里的lst2我们定义的时候使用的是cdef list,但如果转化失败还保留原来的类型。
可如果我们希望在无法转化的时候报错,这个时候要怎么做呢?
def func(a):
# 将<list>换成<list?>即可
cdef list lst2 = <list?> a
print(lst2)
print(type(lst2))
>>> import cython_test
>>> cython_test.func([])
[]
<class 'list'>
>>>
>>> cython_test.func(())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "1.pyx", line 2, in cython_test.func
cdef list lst2 = <list?> a
TypeError: Expected list, got tuple
>>> # 提示我们需要的是list,但却给了一个tuple
如果我们处理一些基类或者派生类时,强制转换也会发生作用。有关强制转换我们会在后续介绍。
声明并使用结构体、共同体、枚举
Cython也支持声明、创建、操作C中的结构体、共同体、枚举。先看一下C中没有使用typedef的结构体、共同体的声明。
struct mycpx {
float a;
float b;
};
union uu {
int a;
short b, c;
};
如果使用Cython创建的话,那么是如下形式:
cdef struct mycpx:
float real
float imag
cdef union uu:
int a
short b, c
这里的cdef也可以写成ctypedef的形式。
ctypedef struct mycpx:
float real
float imag
ctypedef union uu:
int a
short b, c
# 此时我们相当于为结构体和共同体起了一个别名叫:mycpx、uu
cdef mycpx zz # 此时的zz就是一个mycpx类型的变量
# 当然无论结构体是使用cdef声明的还是ctypedef声明的,变量zz的声明都是相似的
# 但是变量的赋值方式有以下几种
# 1. 创建的时候直接赋值
cdef mycpx a = mycpx(1, 2)
# 也可以支持关键字的方式,但是注意关键字参数要在位置参数之后
cdef mycpx b = mycpx(real=1, imag=2)
# 2. 声明之后,单独赋值
cdef mycpx c
c.real = 1
c.imag = 2
# 这种方式会麻烦一些,但是可以更新单个字段
# 3. 通过Python中的字典赋值
cdef mycpx d = {"real": 1, "imag": 2}
# 显然这是使用Cython的自动转换完成此任务,它涉及更多的开销,不建议用此种方式。
如果是嵌套结构体也是可以的,但是需要换种方式
# 如果是C中我们创建一个嵌套结构体,可以使用下面这种方式
"""
struct girl{
char *where;
struct _info {
char *name;
int age;
char *gender;
} info;
};
"""
# 但是Cython中不可以这样,需要把内部的结构体单独拿出来才行
ctypedef struct _info:
char *name
int age
char *gender
ctypedef struct girl:
char *where
_info info # 创建一个info成员,类型是_info
# 这里我的编译器比较低级,所以直接赋值中文了,但是不要这里做,因为这是不合法的,只是我当前的编译器没有检测到罢了
cdef girl g = girl(where="东方地灵殿", info=_info("古明地觉", 16, "female"))
print(g.where)
print(g.info.name)
print(g.info.age)
print(g.info.gender)
定义枚举也很简单,我们可以在多行中定义,也可以在单行中定义然后用逗号隔开。
cdef enum my_enum1:
RED = 1
YELLOW = 3
GREEN = 5
cdef enum my_enum2:
PURPLE, BROWN
# 注意:即使是不同枚举中的成员,但也不能重复
# 比如my_enum1中出现了RED,那么在my_enum2中就不可以出现了
# 当然声明枚举除了cdef之外,同样也可以使用cdef
# 此外,如果我们不指定枚举名,那么它就是匿名枚举,匿名枚举用于声明全局整数常量
关于结构体、共同体、枚举,我们在后面的系列介绍和外部代码进行交互时会使用的更频繁,目前先知道即可,了解一下相关的语法即可。
使用ctypedef给类型起别名
Cython支持的另一个C特性就是可以使用ctypedef给类型起一个别名,和C中的typedef非常类似。主要用在和外部代码进行交互上面,我们还是将在后续系列中重点使用,目前可以先看一下用法。
ctypedef list LIST # 给list起一个别名
# 参数是一个LIST类型
def f(LIST v):
print(v)
>>> import cython_test
>>> cython_test.f([])
[]
>>> cython_test.f(())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Argument 'v' has incorrect type (expected list, got tuple)
>>> cython_test.f(None)
None
我们看到接收的是list,但是我们传了一个tuple进去,因此LIST是list的别名,当然不管什么Python类型,None都是满足的。
ctypedef可以作用于C的类型也可以作用于Python类型,起别名之后这个别名可以像上面那样作用于函数参数、也可以用于声明一个变量(cdef LIST lst),但是不可以像这样:LIST("123")。起的别名用于声明变量,但是不能当成list来用,否则会报错:'LIST' is not a constant, variable or function identifier。
ctypedef对于Cython来说不是很常用,但是对于C++来说则特别有用,使用typedef可以显著的缩短长模板类型,另外ctypedef必须出现在文件内,不可以出现在函数内等局部作用域里。
泛型编程
Cython有一个新的类型特性,称为融合类型,它允许我们用一个类型来引用多个类型。
Cython目前提供了三种我们可以直接使用的混合类型,integral、floating、numeric,它们都是通过cython命名空间来访问的,这个命名空间必须是通过cimport导入的。
integral:代指C中的short、int、longfloating:代指C中的float、doublenumeric:最通用的类型,包含上面的integral和floating以及复数
from cython cimport integral
cpdef integral integral_max(integral a, integral b):
return a if a >= b else b
上面这段代码,Cython将会创建三个版本:1. a和b都是short、2. a和b都是int、 3. a和b都是long。如果是在Cython内部使用的话,那么Cython在编译时会检查到底使用哪个版本;如果是从外部Python代码导入时,将使用long版本。
比如我们在Cython中调用一下,可以这么做。
cdef allowed():
print integral_max(<short> 1, <short> 2)
print integral_max(<int> 1, <int> 2)
print integral_max(<long> 1, <long> 2)
# 但是下面的方式不可以
cdef not_allowed():
print integral_max(<short> 1, <int> 2)
print integral_max(<int> 1, <long> 2)
# 里面的类型不能混合,否则产生编译时错误
# 因为Cython没生成对应的版本的函数
所以这里就要求了我们必须传递integral,如果传递了其它类型,那么在Cython中会引发一个编译时错误,在Python中会引发一个TypeError。
如果我们希望同时支持integral和floating呢?有人说可以使用numeric,是的,但是它也支持复数,而我们不希望支持复数,所以可以定义一个混合类型。
from cython cimport int, float, short, long, double
# 通过ctypedef fused 类型即可定义一个混合类型,支持的类型可以写在块里面
ctypedef fused int_float:
int
float
short
long
double
# 不仅是C的类型,Python类型也是可以的
ctypedef fused list_tuple:
list
tuple
def f1(int_float a):
pass
def f2(list_tuple b):
pass
>>> import cython_test
>>> cython_test.f1(123)
>>> cython_test.f2((1, 2, 3))
>>> cython_test.f1("xx")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "1.pyx", line 15, in cython_test.__pyx_fused_cpdef
def f1(int_float a):
TypeError: No matching signature found
>>>
>>> cython_test.f2("xx")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "1.pyx", line 18, in cython_test.__pyx_fused_cpdef
def f2(list_tuple b):
TypeError: No matching signature found
传递的时候会对参数进行检测,不符合条件会抛出TypeError。
混合类型以及对应的泛型函数还有其它的一些特性,我们将在后面的系列中指出。
Cython中的for循环和while循环
Python中的for循环和while循环是灵活并且高级的,语法自然、读起来像伪代码。而Cython也是支持for和while的,无需修改,并且循环通常占据程序运行时的大部分时间,因此我们可以通过一些指针,确保Cython能够将Python中的循环转换为高效的C循环。
n = 100
for i in range(n):
...
上面是一个标准的Python for循环,如果这个i和n是静态类型,那么Cython就能生成更快的C代码。
cdef unsigned long i, n = 100
for i in range(n):
...
# 这段代码和下面的C代码是等效的
"""
for (i=0; i<n; ++i) {
/* ... */
}
"""
Cython能够推断类型并自动生成快速的循环,但却并不总是这样。如果想加速训话,需要遵循以下原则。
当通过range进行循环时,我们应该将range里面的参数换成C的整型。
cdef unsigned long n = 100
for i in range(n):
...
在循环的时候,这里的i也会被当成是整型,前提是我们没有在循环体的表达式中使用i这个变量。但如果我们使用了,那么Cython无法确定是否会发生溢出,因此会保守的选择Python中的类型。
cdef unsigned n = 100
for i in range(n):
print i + 2 ** 32
我们看到我们在表达式中使用到了i,如果这里的i是C中的整型,那么在和一个纯数字相加的时候,Cython不知道是否会发生溢出,所以这里的i就不会变成C中的整型。
如果我们能保证表达式中一定不会发生溢出,那么我们可以显式地将i也声明为C中的整数类型。比如:
cdef unsigned long i, n = 100。
当我们遍历一个容器(list、tuple、dict等等)的时候,使用上面的方式可能会带来更多的开销,当然取决于具体情况。对于容器的高效循环,我们可以考虑将容器转化为C++的有效容器、或者使用类型化的内存视图。当然这些我们也是在后面系列中说了,因为这些东西显然没办法一次说清(感觉埋了好多坑,欠了好多债)。
目前只能在range中减少循环开销,我们将在后续系列中了解优化循环体的更多信息,包括numpy在Cython中的使用以及类型化内存视图。至于while循环的优化方式和for循环是类似的。
Cython预处理器
我们知道在C中可以使用#define定义一个宏,在Cython中也是可以的,不过使用的是DEF关键字。
DEF pi = 3.14
print(pi * 2)
DEF定义的宏在编译的时候就会被替换成我们指定的值,可以用于声明C的类型、也可以是Python的类型。比如这里的pi,在编译的时候就会被换成3.14,注意:这个宏只是简单的字符串替换,如果你了解C中的宏的话,那么Cython中的宏和C中的宏是类似的。
Cython还提供了一些预定义的宏,我们可以直接拿来用。
UNAME_SYSNAME:操作系统的名称UNAME_RELEASE:操作系统的发行版UNAME_VERSION:操作系统的版本UNAME_MACHINE:操作系统的机型、或者硬件名称UNAME_NODENAME:网络名称
除此之外,Cython还允许我们像C一样使用IF ELIF ELSE进行条件编译。
IF UNAME_SYSNAME == "Windows":
print("这是Windows系统")
ELIF UNAME_SYSNAME == "Linux":
print("这是Linux系统")
ELSE:
print("这是其它系统")
>>> import cython_test
这是Linux系统
>>>
另外:操作系统这些内置的宏,需要搭配
IF ELIF ELSE使用,单独使用是会报错的。
消除Python2和Python3之间的差异
老实说,这一节可以不用看,因为现在都用Python3,再用Python2真的过时了。
我们在之前的系列中,知道可以用Cython为Python编写特定版本的扩展模块。为了方便起见,我们可以使用Python2和Python3的语法编写pyx文件。比如:print在Python2中是一个语句,但是在Python3中是一个函数,但是在pyx文件中,我们既可以print 123、也可以print(123)。生成C源文件会和Python2、Python3都兼容。说是这样,但其实有些地方还是不兼容的,比如str,Python2中的str和Python3中的str是两码事。到后面的系列我会举例子说明,总之在编译的时候最好指定language_level=3。
Python从2.x升级到3.x真的是划时代,之前的代码全都不能用了。Python2想要移植到Python3是蛮困难的,而Cython能生成一个兼容两个大版本的扩展模块,可以消除版本移植的痛苦。
默认情况下,Cython假定语言版本使用的是Python2,但是在编译的时候可以指定language_level=3显式的将语义更改为Python3的语法和语义。此时的pyx文件里面的代码,就必须遵循完全遵循Python3的语法规范了。
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = Extension(name="cython_test", sources=["1.pyx"])
setup(ext_modules=cythonize(ext, language_level=3))
此外,Cython也支持__future__,将Python3的语义导入到Python2中,但还是那句话,现在都2020年了,不要再用Python2了。
总结
本篇博客深入介绍了Cython的语言特性,并且为了更好的理解,使用了很多Python解释器里面才出现的术语,比如:PyObject、PyFunctionObject等等,在学习Cython的某些知识时相当于站在了解释器的角度上,当然也介绍了Python解释器的一些知识。所以看这一篇博客,需要你有Python解释器相关的知识、以及了解C语言,不然学习起来可能有点吃力。
我们后续将会以这些特性为基础,进行深入地使用。目前的话,有些知识并没有覆盖的那么详细,比如:结构体等等,因为循序渐进嘛,所以暂时先抛出来,后面系列再慢慢研究。
Cython生态
Cython是一个辅助语言,它是建立在Python之上的,是为Python编写扩展模块的。所以很少有项目会完全使用Cython编写,但它确实是一个成熟的语言,有自己的语法
(个人非常喜欢,觉得设计的真是酷)。在GitHub上搜索,会发现大量的Cython源文件分布在众多的存储库中。考虑到numpy、pandas、scipy、sklearn等知名模块内部都在使用,所以Cython也算是间接地被数百万的开发人员、分析师、工程师和科学家直接或者间接使用
(我屮艸芔茻,还带这么算的,哈哈可以可以,你速度快,你说啥是啥,蛤蛤蛤蛤蛤嗝~)。如果Pareto原理是可信的,程序中百分之80的运行时开销是由百分之20的代码引起的,那么对于一个Python项目来说,只需要将少部分Python代码转换成Cython代码。
一些用到Cython的顶尖项目都是与数据分析和科学计算有关的,这并非偶然。Cython之所以会在这些领域大放异彩,有以下几个原因:
1. Cython可以高效且简便地封装先有的C、C++、FORTRAN库,从而对那些已经优化并调试过的功能进行访问。这里多提一句,FORTRAN算是一个上古的语言了,它的历史比C还要早,但是别看它出现的早、但速度是真的快,尤其是在数值计算方面甚至比C还要快。包括numpy使用的blas内部也用到了FORTRAN,虽然FORTRAN编写代码异常的痛苦,但是它在一些学术界和工业界还是具有一席之地的。原因就是它内部的一些算法,都是经过大量的优化、并且久经考验的,直接拿来用就可以。而Cython也提供了相应的姿势来调用FORTRAN已经编写好的功能。2. 当转化为静态类型语言时,内存和CPU密集的Python计算会有更好的执行性能。3. 在处理大型的数据集时,与Python内置的数据结构相比,在低级别控制精确的数据类型和数据结构可以让存储更高效、执行性能更优秀。4. Cython可以和C、C++、FORTRAN库共享同类型的连续数组,通过numpy中的数组直接暴露给Python。不过即便不是在数据分析和科学计算领域,Cython也可以大放异彩,它也可以加速一般的Python代码,包括数据结构和密集型算法。例如:lxml这个高性能的xml解析器内部就大量使用了Cython。因此即使它不在科学计算和数据分析的保护伞下,也依旧有很大的用途。
这一篇博客居然写了3万多字,妈呀,累死我了。
