楔子
最近本人看了一个库叫sh,可以很方便的执行Linux的shell命令。比如:Linux中可以使用ls、touch、cp、pwd等命令,那么在sh中也可以使用。
>>> sh.ls
<Command '/usr/bin/ls'>
>>> sh.touch
<Command '/usr/bin/touch'>
>>> sh.ps
<Command '/usr/bin/ps'>
>>> sh.grep
<Command '/usr/bin/grep'>
>>> sh.touch
<Command '/usr/bin/touch'>
>>> sh.cp
<Command '/usr/bin/cp'>
>>> type(sh.ls)
<class 'sh.Command'>
所以Linux上命令,直接通过sh进行调用即可。并且它们的类型都是<class 'sh.Command'>,可是Linux系统中那么多命令,难道每一个命令都创建一个Commend实例对象,显然sh模块不是这么做的,不然的话要实例化多少个Command。可如果不是这么做的,那它是怎么办到的呢?并且我们通过dir查看的话,里面压根就没有ls、ps之类的这些属性
>>> dir(sh)
['_SelfWrapper__env', '_SelfWrapper__self_module', '__builtins__', '__doc__', '__file__', '__name__', '__package__', '__path__']
我们看到sh模块就这些属性,那么它是什么做到调用Linux中的命令的呢?下面就来分析一下
python是如何加载模块的
首先python中的模块也是一个对象,类型为module
import os
print(type(os)) # <class 'module'>
我们知道一个模块可以是一个单独的文件、也可以是一个拥有多个文件的目录,但是在python中实际上区分的没有这么明显。不管你是一个单独的文件还是一个目录,它们的类型在python的底层都是PyModuleObject、也就是python中module。
import os
import pandas
print(type(os)) # <class 'module'>
print(type(pandas)) # <class 'module'>
os是一个单独的py文件、而pandas是一个目录,但是它们的类型都是module,甚至一个空目录也是一个module对象。只不过平时为了区分,我们会把单独的文件称之为模块、目录称之为包,但是它们在底层都是一个module对象。
另外虽然模块是一个module对象,但是module这个类我们不能直接使用,我们只能通过type函数去获取,因为python没有直接将这个类的接口暴露出来给我们使用。
如果直接写上一个module,那么会出现一个NameError:module未定义
而且我们看到module是一个class,所以python中真的一切皆对象,python中的模块也是一个对象,是<class 'module'>的实例对象。既然是<class 'module'>,我们就也可以把module当成类理解。
# 文件名:hanser.py
a = 1
class A:
pass
def foo():
pass
当我们导入hanser这个模块的时候,那么里面的变量a、类A、函数foo都是hanser这个模块的一个属性,这很好理解。所以我们执行hanser.a的时候,也可以理解为实例对象在调用属性。
那么问题来了,Python是怎么加载模块的呢?
当我们import一个模块的时候,假设导入的是hanser.py,那么python就会将这个模块里面的内容加载进来,最终变成一个module对象(简单来说是这样,当然底层实际上做了很多事情,只不过要涉及到解释器原理,我们暂时不说那么多),然后放到sys.modules里面。sys.modules是一个字典,key是模块名,value是对应的module对象。
事实上,当我们import hanser的时候,会先检查sys.modules里面有没有hanser这个模块,如果有直接取出来,如果没有则导入、然后放到sys.modules里面。
import sys
# tornado这个模块没有导入,所以它不在sys.modules里面
print("tornado" in sys.modules) # False
def foo():
import tornado
# 我们在函数里面执行,import tornado
# 我们说导入一个模块的时候,会先检测sys.modules里面有没有,如果有直接从sys.modules里面取出来
# 如果没有,那么再进行导入,然后放到sys.modules里面,这么做的原因就是可以避免一个模块的重复导入
foo()
# 所以此时tornado这个模块就在sys.modules里面了
print("tornado" in sys.modules) # True
# 另外多提一句,关于sys这个模块,它是内嵌在解释器里面的,当解释器启动的时候,这个模块就已经加载进来了
# 不管我们是否导入,这个模块就已经存在了,只不过我们如果想使用,还是需要import sys,当然sys这个模块本身也在sys.modules里面
# 是的,你没有看错,sys也在sys.modules里面,只要是模块都在sys.modules里面。
# 因为python中的模块、函数、类都可以看成是变量,而python中变量的本质上是对值的引用,在底层只是一个指针
# 当然这一点目前没必要纠结,当然有兴趣的可以自己去搜索一下相关的资料也可以,我们举个栗子:
print(sys
is
# sys.modules["sys"]就是sys,所以不管调用多少层modules["sys"],得到的结果都是sys,sys is sys结果为True
sys.modules["sys"].modules["sys"].modules["sys"].modules["sys"].modules["sys"]) # True
# 而我们调用一个模块,本质上是取sys.modules里面根据模块名取出这个模块
# 但是我们目前在全局调用tornado是会报错的,因为这个模块是在foo函数里面导入的,所以只能在该函数里面使用
# 而我们在全局并没有导入tornado这个模块,但是我们说了,只要导入了模块都会放到sys.modules里面
# 所以我们是可以直接从sys.modules里面获取的
print(sys.modules["tornado"]) # <module 'tornado' from 'C:\python38\lib\site-packages\tornado\__init__.py'>
print(sys.modules["tornado"].version_info) # (6, 0, 3, 0)
# 而此时我们再在全局导入tornado模块
import tornado
# 但是我们说导入一个模块,会先看sys.modules里面是否存在,如果存在了就不会再导入了
# 而sys.modules里面已经存在了,所以上面的import tornado实际上就等价于tornado = sys.modules["tornado"]
所以我们可以做一个小trick
# 文件名:hanser.py
import sys
import pandas
sys.modules[__name__] = pandas
# 当hanser.py被导入的时候,那么__name__就是该模块名
然后我们导入这个模块
>>> import hanser
>>> hanser
<module 'pandas' from 'C:\python38\lib\site-packages\pandas\__init__.py'>
>>> hanser.DataFrame
<class 'pandas.core.frame.DataFrame'>
>>>
现在你肯定很清楚背后的原理,我们在导入hanser的时候,那么会把hanser.py变成一个module对象,然后把"hanser": "<module 'hanser'>"这个键值对放在sys.modules里面。当我们调用hanser的时候,本质上就是调用sys.module["hanser"],但是在hanser.py的最后一行,我们将sys.modules["hanser"]换成了pandas,所以下面我们通过hanser去调用的时候,实际上调用的是pandas。
相信你此刻对python加载模块已经有了一个很清晰的认识了,下面我们总结一下上面的内容
1.python中的模块也是一个对象,类型为<class 'module'>,模块里面类、函数、变量什么的,都是模块的一个属性,就跟我们自己定义的类生成的实例对象调用自身的属性是一个道理2.python的模块也可以看成是一个变量,import hanser,那么hanser虽然是一个模块,但是也可以看成是一个变量。模块名就是变量名,而模块、或者module对象本身则可以看成是变量的值。同理函数也是,函数名也可以看成是一个变量名,函数体则可以看成是变量的值。所以python中是一切皆对象3.导入一个模块,会先检测该模块是否存在于sys.modules里面,如果有直接取出;如果没有,那么执行导入逻辑,将"模块名": "module对象"作为键值对放在sys.modules里面。这样一旦再次导入就可以直接从sys.modules里面取出即可,不会进行重复导入。当我们调用这个模块,本质上也是从sys.modules里面根据模块名去获取相应的模块、或者module对象,然后执行相关逻辑。4.所以我们执行sys.modules["hanser"] = pandas,那么调用hanser的时候,那么从sys.modules["hanser"]已经不再是原来的<module 'hanser'>了,而是pandas对应的module对象。
将类变成一个模块
有了上面的前置知识,我们下面来实现sh模块里面的逻辑。
# 文件名:hanser.py
import sys
class A:
def __getattr__(self, item):
return f"你调用了'{item}'命令"
# 我们定义了__getattr__方法,那么当实例调用一个不存在的属性时,会执行__getattr__方法
# 因为模块的类型是<class 'module'>,我们的A()的类型是<class 'A'>
# 既然module和A都是一个class,那么它们内部的执行逻辑就也是一样的,既然找不到,那么就执行__getattr__方法
sys.modules[__name__] = A()
>>> import hanser
>>> hanser.ls
"你调用了'ls'命令"
>>> hanser.touch
"你调用了'touch'命令"
>>>
# 怎么样,是不是很神奇呢?其实逻辑很简单,就是像我们上面分析的那样。
# 因为我们调用hanser的时候,本质上就是去sys.modules里面去找key为"hanser"对应的value
# 但是sys.modules[__name__] = A(),__name__为"hanser",所以调用hanser的时候,实际上调用的是A的实例对象
当然sh模块内部还有其它的逻辑,但那是执行Linux命令用的,但就调用属性来说,用的方法就是我们上面分析的那样。
只不过我们上面的逻辑还有一点点不完美
sys.modules里面的value应该是一个<class 'module'>对象,而我们目前的是<class 'A'>对象,所以pycharm这种智能编辑器也进行了提示。
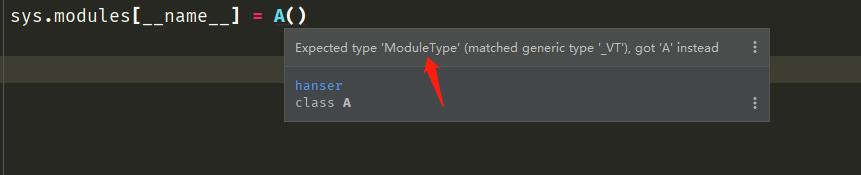
当然由于python的动态特性、以及鸭子类型,所以我们使用起来是没有问题的。但是既然要追求完美,就贯彻到底楼。它提示我们sys.modules[__name__]应该是一个ModuleType,我们来看看这是什么,实际上不用想,也知道这啃腚是<class 'module'>
# types里面定义了很多的类型,当然这些类型我们也可以自己实现
from types import ModuleType
print(ModuleType) # <class 'module'>
# 我们说很多类型,python并没有直接提供给我们,只能是我们通过type去获取
# 事实上,types这个模块里面也是这么做的,比如这里的ModuleType
# types源码里面就是这么干的:ModuleType = type(sys)
# 再比如函数,python中函数的类型是<class 'function'>,所以在底层函数也是一个对象,是类function的实例对象
# 但是同样的function这个类python也没有直接暴露给我们使用,我们只能通过type去获取,那么问题来了,如何判断一个变量指向的是不是一个函数呢?
# 很简单,定义一个函数foo,然后 isinstance(变量, type(foo))即可
# 比如types里面还有一个FunctionType,也就是函数类型,看看它是怎么干的
"""
def _f(): pass
FunctionType = type(_f)
LambdaType = type(lambda: None) # Same as FunctionType
"""
# 是不是跟我们说的一样呢?而且不仅是函数,还有匿名函数lambda,当然它也是一个function对象
print(type(lambda : None)) # <class 'function'>
# 所以更多类型可以去types这个模块里面查看,它是一个标准库
# 这里我们再来看看module的类型是什么,事实上不用想,既然是一个class,那么类型肯定是type
print(type(type(sys))) # <class 'type'>
然后我们就可以这样改:
# 文件名:hanser.py
import sys
# 或者继承types.ModuleType也是一样的,这样我们的class A就变成了一个module了,实例化就得到一个模块了
# 只不过python中module实例化需要一个参数,我们可以接收一个模块,就接收pandas吧,至于怎么做看你自己
class A(type(sys)):
def __init__(self, module):
self.module = module
def __getattr__(self, item):
if item in self.module.__dict__:
return self.module.__dict__[item]
return f"你调用了'{item}'命令"
import pandas
sys.modules[__name__] = A(pandas)
>>> import hanser
>>> hanser.DataFrame
<class 'pandas.core.frame.DataFrame'>
>>> hanser.isna
<function isna at 0x00000243D6E665E0>
>>> hanser.哈哈
"你调用了'哈哈'命令"
>>>
所以python中的所有对象都是由一个class实例化得到的,像整型、字符串、列表、集合就不用说了,包括int、list、dict等内建的类、我们自己定义的类、函数、以及模块等等,它们也都是由一个具体的类实例化得到的,它们的类型都是<class 'xxx'>,只不过由于内部的构造不同,所以实例化得到的结果不同。但不管咋样,总之类型都是class。所以我们如果是class A(type):,那么这个A就是一个元类;如果是class A(type(sys)):,那么这个A就可以看成是一个module,实例化得到的就是一个模块。
所以python里面一切皆对象,这句话说的是非常正确。因为你能看到的任何东西,都是由一个class实例化得到的,它们都可以称之为某个class的对象。只不过class内部的构造不同,表现出来的状态也不同。比如:type和我们定义的class A,type和A都是一个class,但是type实例化得到的还是一个class,但是A实例化得到的就不是class了
所以可以好好的细品一下,python真的是一个将面向对象这个理念贯彻到极致的语言。比起java这种,抱歉不说了,狗头保命。