楔子
SQL是每个开发人员都应该掌握的,很多人可能觉得SQL没啥大不了的,但是说真的,SQL要是写好了,是很厉害的。下面我们来从零开始学习SQL。
在SQL的世界里一切都是关系
正如linux中一切皆文件,python中一切皆对象,SQL(结构化查询语言)中可以把一切都看成是关系。我们来看看一些概念:
关系型数据库:
关系型数据库(Relational database)是指基于关系模型的数据库。关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
数据结构:
在关系模型中,用于存储数据的逻辑结构称为关系(Relation);对于使用者而言,关系就是二维表(Table)。
以下是一张员工信息表,知道Excel的人肯定会很熟悉,因为它和Excel的结构非常类似,由行(Row)和列(Column)组成。
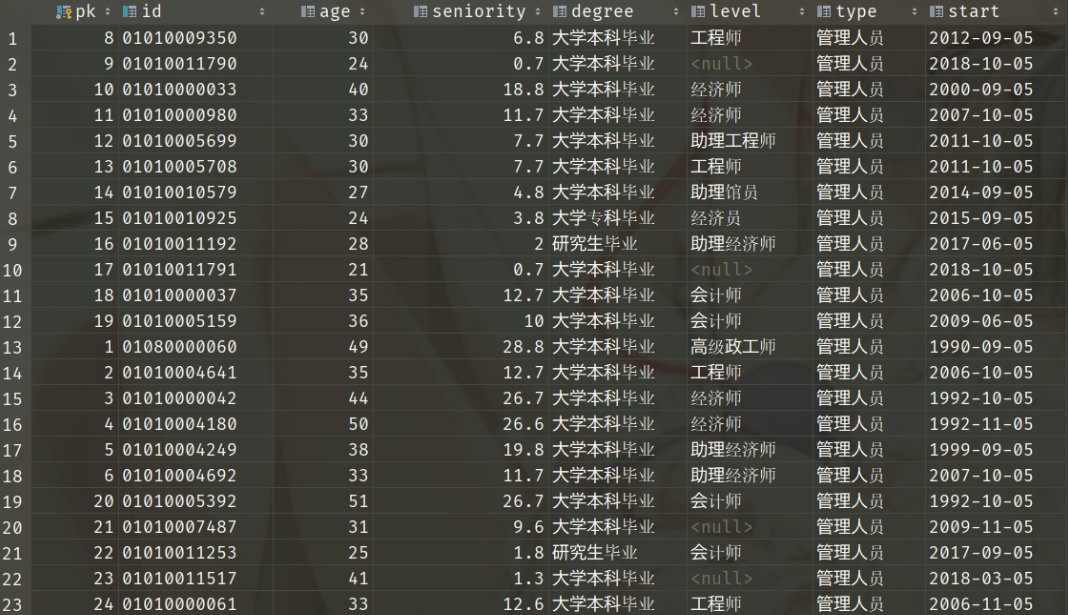
关系型数据库中还有一些常见的概念:
关系,也称为表,用于表示现实世界中的实体(Entity)或者实体之间的联系(Relationship)。举例来说,一个公司的员工、部门和职位都是实体,分别对应员工信息表、部门信息表和职位信息表;销售的产品和订单都是实体,同时它们之间存在联系,对应订单明细表。行,也称为记录(Record),代表了关系中的单个实体。上图中pk为 8 的数据行存储了id 为"01010009350"的相关信息。关系(表)可以看作是由行组成的集合。列,也称为字段(Field),表示实体的某个属性。上图中的第二列包含了员工的id。表中的每个列都有一个对应的数据类型,常见的数据类型包括字符类型、数字类型、日期时间类型等。
操作集合:
有了关系结构之后,就需要定义基于关系的数据操作。
常见的数据操作包括增加(Create)、查询(Retrieve)、更新(Update)以及删除(Delete),或者统称为增删改查(CRUD)。
其中,使用最多、也最复杂的操作就是查询,具体来说包括选择(Selection)、投影(Projection)、并集(Union)、交集(Intersection)、差集(exception)以及笛卡儿积(Cartesian product)等。我们将会介绍如何使用 SQL 语句完成以上各种数据操作。
为了维护数据的完整性或者满足业务需求,关系模型还定义了完整性约束。
完整性约束:
关系模型中定义了三种完整性约束:实体完整性、参照完整性以及用户定义完整性。
实体完整性是指表的主键字段不能为空。现实中的每个实体都具有唯一性,比如每个人都有唯一的身份证号;在关系数据库中,这种唯一标识每一行数据的字段称为主键(Primary Key),主键字段不能为空。每个表可以有且只能有一个主键。但是一个主键不一定只对应一个字段,也可以是多个字段共同组合成联合主键,但它仍然是一个主键参照完整性是指外键参照的完整性。外键(Foreign Key)代表了两个表之间的关联关系,比如员工属于某个部门;因此员工表中存在部门编号字段,引用了部门表中的部门编号字段。对于外键引用,被引用的数据必须存在,员工不可能属于一个不存在的部门;删除某个部门之前,也需要对部门中的员工进行相应的处理。用户定义完整性是指基于业务需要自定义的约束。非空约束(NOT NULL)确保了相应的字段不会出现空值,例如员工一定要有姓名;唯一约束(UNIQUE)用于确保字段中的值不会重复,每个员工的电子邮箱必须唯一;检查约束(CHECK)可以定义更多的业务规则。例如,薪水必须大于 0 ,字符必须大写等;默认值(DEFAULT)用于向字段中插入默认的数据。
另外我们说的SQL其实是一个工业标准,或者说它指的是操作数据库中的二维表时所使用的语言,而不同种类的关系型数据库的SQL也是不同的,但是,它们大致都是一样的。常见的数据库一般有MySQL、Oracle、PostgreSQL、SQL Server。我们下面介绍的SQL,这四种数据库都支持,如果不支持,我们单独指出来。
SQL的语法特性
SQL 是一种声明性的编程语言,语法接近于自然语言(英语)。通过几个简单的英文单词,例如 SELECT、INSERT、UPDATE、CREATE、DROP 等,完成大部分的数据库操作。以下是一个简单的查询示例,这里只是提前感受一下SQL,具体的语法细节我们后面会说:
SELECT emp_id, emp_name, salary
FROM employee
WHERE salary > 10000
ORDER BY emp_id;
即使没有学过 SQL 语句,但只要知道几个单词的意思,就能明白该语句的作用。它查询员工表(employee)中月薪(salary)大于 10000 的员工,返回工号、姓名以及月薪,并且按照工号进行排序。可以看出,SQL 语句非常简单直观。
以上查询中的 SELECT、FROM 等称为关键字(也称为子句),一般大写;表名、列名等内容一般小写;分号(;)表示语句的结束。SQL 语句不区分大小写,但是遵循一定的规则可以让代码更容易阅读。
面向集合:
对于 SQL 语句而言,它所操作的对象是一个集合(表),操作的结果也是一个集合(表)。例如以下查询:
SELECT emp_id, emp_name, salary
FROM employee;
其中 employee 是一个表,它是该语句查询的对象;同时,查询的结果也是一个表。所以,我们可以继续扩展该查询:
SELECT emp_id, emp_name, salary
FROM (
SELECT emp_id, emp_name, salary
FROM employee
) as dt;
我们将括号中的查询结果(取名为 dt)作为输入值,传递给了外面的查询;最终整个语句的结果仍然是一个表。在后续中,我们将会介绍这种嵌套在其他语句中的查询就是子查询(Subquery)。
SQL 中的查询可以完成各种数据操作,例如过滤转换、分组汇总、排序显示等;但是它们本质上都是针对表的操作,结果也是表。
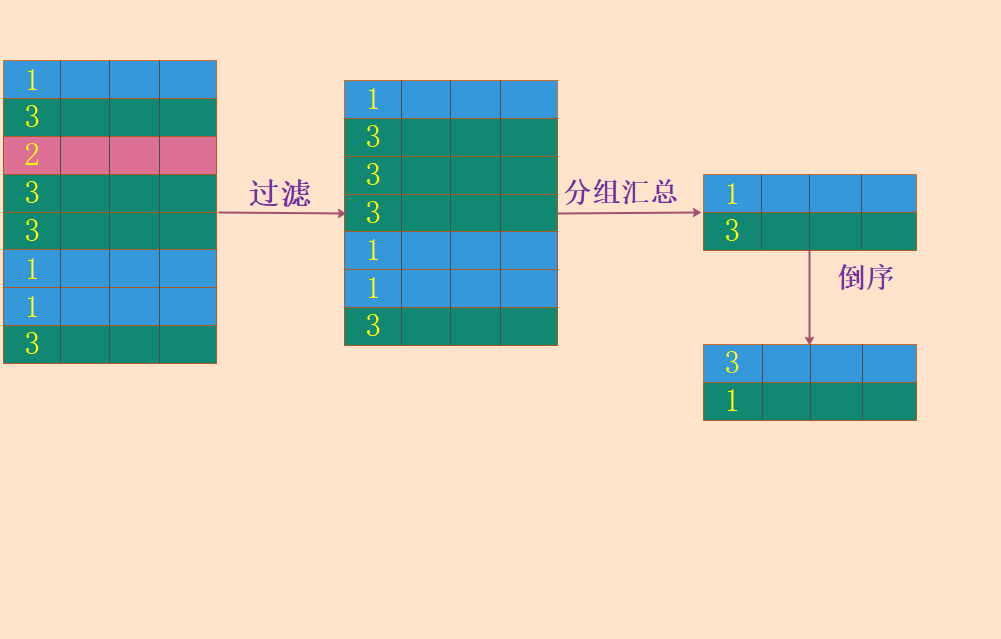
不仅仅是查询语句,SQL 中的插入、更新和删除都以集合为操作对象。我们再看一个插入数据的示例:
CREATE TABLE t(id INTEGER);
-- 适用于 MySQL、SQL Server 以及 PostgreSQL
INSERT INTO t(id)
VALUES (1), (2), (3);
我们首先使用 CREATE TABLE 语句创建了一个表,然后使用 INSERT INTO 语句插入数据。在执行插入操作之前,会在内存中创建一个包含 3 条数据的临时集合(表),然后将该集合插入目标表中。由于我们通常一次插入一条数据,以为是按照数据行进行插入;实际上,一条数据也是一个集合,只不过它只有一个元素而已。
Oracle 不支持以上插入多行数据的语法,可以使用下面的插入语句:
-- 适用于 Oracle
INSERT INTO t(id)
SELECT 1 FROM DUAL
UNION ALL
SELECT 2 FROM DUAL
UNION ALL
SELECT 3 FROM DUAL;
UNION ALL 是 SQL 中的并集运算,用于将两个集合组成一个更大的集合。此外,SQL 还支持交集运算(INTERSECT)、差集运算(EXCEPT)以及笛卡儿积(Cartesian product)。我们后面会慢慢介绍
安装数据库
我们既然要学习SQL,那么就需要安装一个数据库,安装的数据库我推荐MySQL或者PostgreSQL,因为这两个安装起来非常方便,学习SQL的时候用什么数据库没有太大影响。我这里使用的是PostgreSQL,至于如何安装我这里就不演示了,Windows上安装很简单,网上搜索一下即可。
小结
关系模型中定义了一个简单的数据结构,即关系(表),用于存储数据。SQL 是关系数据库的通用标准语言,它使用接近于自然语言(英语)的语法,通过声明的方式执行数据定义、数据操作、访问控制等。对于 SQL 而言,一切都是关系(表)。
使用 SELECT 语句初步探索数据库
正文
查询是数据库中最常见的操作,所以我们先来了解一下基本的查询语句。再次强调:下面所有的 SQL 语句默认都适用于 4 种数据库,数据库专用的语法将会进行特殊说明。
关于表,我下面使用的表的结构如下:

表名为people。
查询指定字段:
在people表中,存储了员工的信息,我们现在要找到id、age、degree,在 SQL 中可以通过一个简单的查询语句来实现,为了方便,我这里关键字就使用小写了,当然SQL中关键字是不区分大小写的,但是一般都会大写。我这里为了方便用的小写。
select id, age, degree
from people;
其中 SELECT 表示查询,随后列出需要返回的字段,多个字段使用逗号分隔;FROM 表示要从哪个表中进行查询;分号表示 SQL 语句的结束。该语句执行的结果如下(显示部分数据):
这种查询表中指定字段的操作在关系运算中被称为投影(Projection),使用 SELECT 子句进行表示。投影是针对表进行的垂直选择,保留需要的字段用于生成新的表。以下是投影操作的示意图:

投影操作中包含一个特殊的操作,就是查询表中所有的字段。
查询全部字段:
查看表中的全部字段可以使用一个简单的写法,就是使用星号(*)表示全部字段。例如,以下语句查询员工表中的所有数据:
select *
from people;
数据库在解析该语句时,会使用表中的字段名进行扩展:
select pk, id, age, seniority,
degree, level, type, start
from people;

注意:星号可以便于快速编写查询语句,但是在实际项目中不要使用这种写法。因为应用程序可能并不需要所有的字段,避免返回过多的无用数据;另外,当表结构发生变化时,星号返回的信息也会发生改变。
除了查询表的字段之外,SELECT 语句还支持扩展的投影操作,包括基于字段的算术运算、函数和表达式等。
扩展操作:
比如:我们将员工的age加1,返回。
select pk, age + 1
from people;
但是我们看到,返回的字段名变了,这里给出了一个?column?,那么我们可不可以指定返回的名字呢?答案是可以的
指定别名:
为了提高查询结果的可读性,可以使用别名为表或者字段指定一个临时的名称。SQL 中使用关键字 AS 指定别名。我们为上面的示例指定一些更好理解的标题:
select pk as new_pk, age + 1 as age_incr_1
from people;
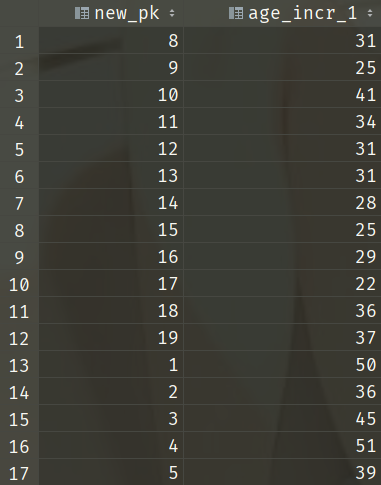
这样的话,返回的字段名就不会给人造成困惑了。另外除了给字段指定别名,还可以给表指定别名。
select pk as new_pk, age + 1 as age_incr_1
from people as p;
返回的结果是一样的,另外我们看到给表起不起别名貌似跟之前没啥区别啊,是的,对于单表查询来讲给表起不起别名没任何影响。但是,对于多个表join的时候,为了区分select后面的字段到底是哪一个表的字段,我们在选择的时候就不会只输入字段名了,而是会通过表名.字段名的方式,可如果表名比较长,那么给表起别名就很有意义了。
select p.pk as new_pk, p.age + 1 as age_incr_1
from people as p;
上面表示我要找people表下面的pk和age,但是people比较长,我们用p来代替。当然上面我们还是以单表查询为例,所以直接输入字段名也是可以的
另外as其实是可以省略的,可以使用一个或多个空格代替
select p.pk new_pk, p.age + 1 age_incr_1
from people p;
这样写也是一点问题都没有的,但是注意:我们说加不加as没有任何影响,可以使用as也可以使用空格(相当于不加as),但是对于Oracle数据库来讲,给表起别名一定不能加as,只能用空格代替,字段名用不用as就没要求了。
另外,在 SQL 语句中使用别名不会修改数据库中存储的表名或者列名,别名只在当前语句中生效。
SQL 注释:
在 SQL 中可以像其他编程语言一样使用注释;注释可以方便我们理解代码的作用,但不会被执行。SQL中的注释分为单行注释和多行注释。单行注释以两个连字符(--)开始,直到这一行结束;SQL 使用 C 语言风格的多行注释(/* … */),例如:
select pk, --这是主键
age -- 年龄
/*
我们要从people表中查询主键和年龄
*/
from people;
MySQL中的 # 也可以用于表示单行注释。
无表查询:
在 SQL 中,SELECT ... FROM ... 是最基本的查询形式;但是,有时候我们会看到一种更简单的查询:只有 SELECT 子句,没有 FROM 子句的查询。
select 1 + 1 as one_plus_one,
substr('古明地觉', 1, 3) as trunc_string,
3 * 8 as three_mul_eight;

这种形式的查询语句通常用于快速查找信息,或者当作计算器使用。但是需要注意的是这种语法并不属于 SQL 标准,而是数据库产品自己的扩展。我们不需要针对某张具体的表,可以直接通过数据库支持的函数对指定的数据进行计算。但是很少这么做,因为这样的话,数据需要我们手动输入,那这样的话还要数据库做什么?直接拿其它的编程语言手动计算不就行啦,其实说白了,这种功能最大的用处就是更方便我们学习语法,尤其是支持的函数。比如我想看某个函数支持的功能,我们上面用到了substr,我们输入一个字符串以及其它参数就可以通过执行结果来查看这个函数的功能了,就没有必要再先找一张表,然后再通过查询表中的字段来观察函数的用法了,因此可以快速的帮助我们学习。
MySQL、SQL Server 以及 PostgreSQL 都支持无表查询;对于 Oracle 而言,可以使用以下等价的形式:
-- Oracle 实现
SELECT 1+1
FROM dual;
dual 是 Oracle 中的一个特殊的表;它只有一个字段且只包含一行数据,就是为了方便快速查询信息。另外,MySQL 也提供了 dual 表。
小结
本节我们学习了如何使用 SELECT 和 FROM 查询表中的数据,通过投影操作获取指定的字段信息。SQL 不仅仅能够查询表中的数据,还可以返回算术运算、函数和表达式的结果。在许多数据库中,不包含 FROM 子句的无表查询可以用于快速获取信息。另外,别名和注释都可以让我们编写的 SQL 语句更易阅读和理解。
通过查询条件实现数据过滤
正文
我们上面学习了如何使用 SELECT 和 FROM 查询表中的数据,不过,在实际应用中通常并不需要返回表中的全部数据,而只需要找出满足某些条件的结果。比如,某个部门中的员工或者某个产品最近几天的销售情况。在 SQL 中,可以通过查询条件实现数据的过滤。
查询条件:
在 SQL 语句中,使用关键字 WHERE 指定查询的过滤条件。以下语句只返回age为30的员工信息
select * from people
where age = 30;

其中,WHERE 位于 FROM 之后,用于指定一个或者多个过滤条件;只有满足条件的数据才会返回,其他数据将被忽略。比如我们筛选所有的字段,但并不是每一行都要,只有当该行的age字段所对应的值等于30的,我们才要。
在 SQL 中,WHERE 子句也被称为谓词(Predicate)。
这种通过查询条件过滤数据的操作在关系运算中被称为选择(Selection)。它是针对表进行的水平选择,保留满足条件的行用于生成新的表。以下是选择操作的示意图:
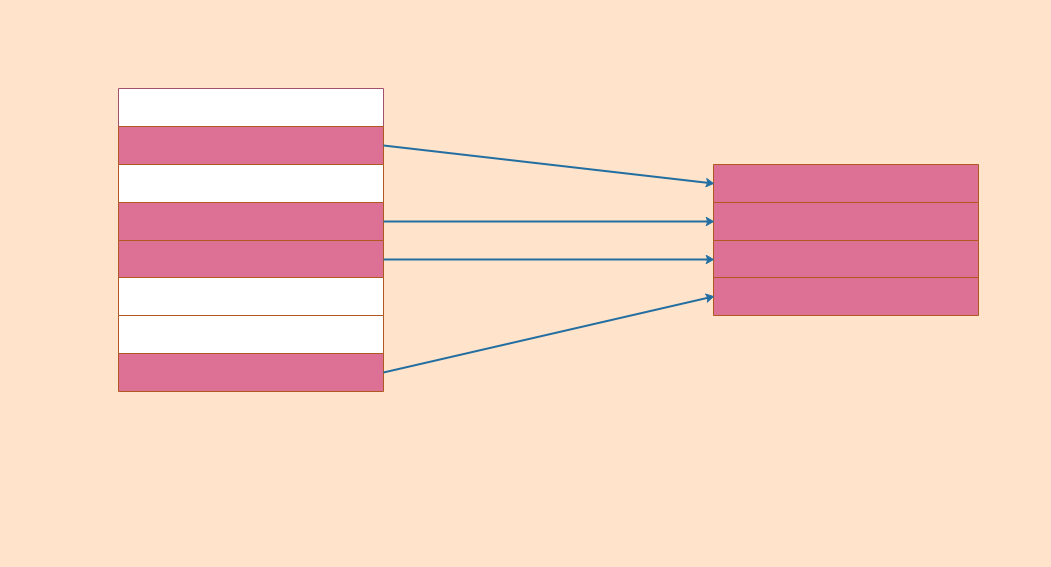
在查询条件中,使用最多的就是数据的比较运算。
比较运算符:
比较运算符可以比较两个数值的大小,包括字符、数字以及日期类型的数据。下表列出了 SQL 中的各种比较运算符:

Oracle 中 ^= 运算符也表示不等于。
这些运算符的作用都比较好理解。我们来看一个日期数据的比较操作,假设想要知道哪些员工在 2008 年 1 月 1 日之前入职,可以使用以下查询:
select * from people
where start <= date '2008-1-1';
其中,DATE '2008-01-01'定义了一个日期类型的常量值。对于 SQL Server、MySQL、PostgreSQL,指定日期时可以直接使用字符串字面值表示:
select * from people
where start <= '2008-1-1';
/*
start是一个日期类型,而'2008-1-1'是一个字符串
但是在比较的时候会自动将'2008-1-1'这个字符串解析成日期格式进行比较,但是它本质还是个字符串
*/
另外对于PostgreSQL,我们还可以通过::来改变类型,不仅仅是日期类型,还包括其它类型。
-- 1和'2'无法进行相加,但是我们通过'2'::int,变成了一个整型
-- current_date表示当前日期,'2018-1-1'::date表示将字符串解析成日期,然后相减得到相差的总天数
-- 当然我们说对于日期相减,如果一方为日期,另一方是字符串的话,那么会将字符串解析成日期再进行相减
select 1 + '2'::int, current_date - '2018-1-1'::date
/*
输出结果:
3 795
*/
between运算符:
如果想要查找一个范围内的数据,可以使用 BETWEEN 运算符。以下示例查询age位于 30 到 40 之间的员工,注意:包含区间的两侧:
select * from people
where age between 30 and 40;
in运算符:
IN 运算符可以用于查找列表中的值,比如以下例子表示查询age为30或36或38的员工。
select * from people
where age in (30, 36, 38);

只要匹配列表中的任何一个值,都会返回结果。IN 运算符还有一个常见的用途就是子查询的结果匹配,我们后面会说。
空值判断:
空值(NULL)是 SQL 中的一个特殊值,代表了缺失或者未知的数据。与其他编程语言(例如 Java)不同,SQL 中判断一个值是否为空不能使用等于或者不等于。例如,以下查询尝试找出字段level为空的员工:
select * from people
where level is null;

如果表达式 expression 的值为空,IS NULL 返回真,IS NOT NULL 返回假;如果表达式的值不为空,IS NULL 返回假,IS NOT NULL 返回真。因此我们需要使用is判断
不能使用=或者!=来判断是否为空,将一个值与一个未知的值进行数学比较,结果仍然未知;即使是将两个空值进行比较,结果也是未知。以下运算的结果均为未知,用于查询条件的话不会返回任何结果:
NULL = 5;
NULL = NULL;
NULL != NULL;
复合条件:
如果仅仅能够指定单个过滤条件,就无法满足复杂的查询需求;为此,SQL 引入了用于构建复杂条件的逻辑运算符。借助于逻辑代数中的逻辑运算,SQL 提供了三个逻辑运算符:
-
AND,"逻辑与"运算符。只有当两边的条件都为真时,结果才为真,返回数据;否则,不返回数据--查找level为经济师的记录 select * from people where level = '经济师'; /* 10 01010000033 40 18.8 大学本科毕业 经济师 管理人员 2000-09-05 11 01010000980 33 11.7 大学本科毕业 经济师 管理人员 2007-10-05 3 01010000042 44 26.7 大学本科毕业 经济师 管理人员 1992-10-05 4 01010004180 50 26.6 大学本科毕业 经济师 管理人员 1992-11-05 */ --查找level为经济师并且age>45的记录 select * from people where level = '经济师' and age > 45; /* 4 01010004180 50 26.6 大学本科毕业 经济师 管理人员 1992-11-05 */ -
OR,"逻辑或"运算符。只要有一个条件为真,结果就为真,返回数据;否则,不返回数据。--查找level为助理工程师的记录 select * from people where level = '助理工程师'; /* 12 01010005699 30 7.7 大学本科毕业 助理工程师 管理人员 2011-10-05 */ --查找level为助理工程师或者age>45的记录 select * from people where level = '助理工程师' or age > 45; /* 12 01010005699 30 7.7 大学本科毕业 助理工程师 管理人员 2011-10-05 1 01080000060 49 28.8 大学本科毕业 高级政工师 管理人员 1990-09-05 4 01010004180 50 26.6 大学本科毕业 经济师 管理人员 1992-11-05 20 01010005392 51 26.7 大学本科毕业 会计师 管理人员 1992-10-05 */对于逻辑运算符 AND 和 OR,SQL 使用短路运算(short-circuit evaluation)。也就是说,只要前面的表达式能够决定最终的结果,不执行后面的计算。这样能够提高运算效率。因此,以下语句不会产生除零错误:
SELECT * FROM people WHERE 1 = 0 AND 1/0 = 1; SELECT * FROM people WHERE 1 = 1 OR 1/0 = 1;第一个查询由于 AND 左边的结果为假,肯定不会返回任何结果,因此也就不会计算 1/0;第二个查询由于 OR 左边的结果为真,一定会返回结果,同样不会产生除零错误。
-
NOT,"逻辑非"运算符。用于将判断结果取反,真变为假,假变为真;空值取反后仍然为空值。NOT 运算符可以结合其他的运算符一起使用,用于对查询条件的结果取反:
- NOT BETWEEN,位于范围之外。
- NOT IN,不在列表之中。
- NOT LIKE,不匹配某个模式。LIKE 运算符用于字符串的模糊查找,将在后面进行介绍。
- NOT EXISTS,子查询中不存在结果。关于子查询和 EXISTS 运算符,将在后面中进行介绍。
- NOT IS NULL,不为空。等价于 IS NOT NULL。
--查找level不为 '助理工程师'、 '经济师'、 '工程师'的记录 --等价于level != '助理工程师' and level != '经济师' and level != '工程师' select * from people where level not in ('助理工程师', '经济师', '工程师'); /* 14 01010010579 27 4.8 大学本科毕业 助理馆员 管理人员 2014-09-05 15 01010010925 24 3.8 大学专科毕业 经济员 管理人员 2015-09-05 16 01010011192 28 2 研究生毕业 助理经济师 管理人员 2017-06-05 18 01010000037 35 12.7 大学本科毕业 会计师 管理人员 2006-10-05 19 01010005159 36 10 大学本科毕业 会计师 管理人员 2009-06-05 1 01080000060 49 28.8 大学本科毕业 高级政工师 管理人员 1990-09-05 5 01010004249 38 19.8 大学本科毕业 助理经济师 管理人员 1999-09-05 6 01010004692 33 11.7 大学本科毕业 助理经济师 管理人员 2007-10-05 20 01010005392 51 26.7 大学本科毕业 会计师 管理人员 1992-10-05 22 01010011253 25 1.8 研究生毕业 会计师 管理人员 2017-09-05 7 01010005306 33 9.6 大学本科毕业 助理经济师 管理人员 2009-11-05 */ --另外还等价于not (level = '助理工程师' or level = '经济师' or level = '工程师'),这个逻辑有点绕看看你能否理解,当然也不推荐这种写法,让人有点困惑
运算符优先级:
将多个逻辑运算符进行组合,可以构造任意复杂的查询条件。不过,需要注意不同的运算符之间的优先级问题。
--查找age小于等于25或者大于等于50,并且level不为空的记录
select * from people
where age <= 25 or age >= 50 and level is not null;

但是我们看到把level为null的也选了进来,这个时候我们就要说一下多个逻辑运算符之间的优先级问题了。
/*
A or B and C
这样一个式子,没有括号的话,肯定是先判断A和B,但如果A为真,那么不好意思,B以及后面的那一长串就都不会判断了
所以我们应该使用括号括起来
*/
select * from people
where (age <= 25 or age >= 50) and level is not null;

去除重复值:
SQL 使用 DISTINCT 关键字去除查询结果中的重复数据。例如,以下查询返回了people表所有的degree:
select distinct(degree) from people;
/*
大学专科毕业
大学本科毕业
研究生毕业
*/
首先,DISTINCT 位于 SELECT 之后而不是像其他过滤条件一样位于 WHERE 之后;其次,查询结果中重复的记录只会出现一次。与 DISTINCT 相反的是 ALL,用于返回不去重的结果。我们通常不需要加上 ALL 关键字,因为它是默认的行为。另外,为了消除重复值,数据库系统需要对结果进行排序,然后扫描重复值;因此,大量数据的重复值处理可能会降低查询的速度
Oracle 中的 UNIQUE 等价于 DISTINCT,MySQL 中的 DISTINCTROW 等价于 DISTINCT
小结
在 SQL 中使用 WHERE 子句指定一个或者多个过滤条件,可以查找满足要求的数据。SQL 查询条件中支持各种比较运算符、逻辑运算符以及空值判断等。另外,DISITINCT 关键字可以去除查询结果中的重复记录。
如何使用 SQL 语句进行模糊查找
正文
我们之前介绍了如何利用 WHERE 子句中的查询条件过滤数据,包括比较运算符、逻辑运算符以及空值判断等。同时,我们也提到了 LIKE 运算符可以用于字符串的模糊查找。下面我们就来讨论一下 SQL 中的模糊匹配。
当需要查找的信息不太确定时,例如只记住了某个员工姓名的一部分,可以使用模糊查找的功能进行搜索。SQL 提供了两种模糊匹配的方法:LIKE 运算符和正则表达式函数。
LIKE 运算符:
下面的语句查找degree包括“专科”的员工
select * from people
where degree like '%专科%';
/*
15 01010010925 24 3.8 大学专科毕业 经济员 管理人员 2015-09-05
*/
该语句使用了一个新的运算符:LIKE。LIKE 用于指定一个模式,并且返回匹配该模式的数据。LIKE 运算符支持两个通配符,用于指定模式:
- %,百分号可以匹配零个或者多个任意字符。
- _,下划线可以匹配一个任意字符。
以下是一些模式和匹配的字符串:
LIKE 'en%',匹配以“en”开始的字符串,例如“english languages”、“end”;LIKE '%en%',匹配包含“en”的字符串,例如“length”、“when are you”;LIKE '%en',匹配以“en”结束的字符串,例如“ten”、“when”;LIKE 'Be_',匹配以“Be”开始,再加上一个任意字符的字符串。例如“Bed”、“Bet”;LIKE '_e%',匹配一个任意字符加上“e”开始的字符串,例如“her”、“year”。
如果想要执行相反的操作,返回不匹配某个模式的数据,可以使用 NOT LIKE 运算符。
“%”和“_”是 LIKE 运算符中的通配符。如果需要查找的内容自身包含了“%”或者“_”时,例如想要知道哪些数据包含了“10%”(百分之十,而不是以 10 开始的字符串),应该如何指定模式呢?这种情况需要用到转义字符(escape character)。
转义字符:
转义字符可以将通配符“%”和“_”进行转义,将它们当作普通字符使用。默认的转义字符为反斜杠()。因此,如果我想选择字符串中包含"25%"的,就应该这么写:
select xxx from xxx where xxx like "%25\%%";
--倒数第二个%的前面有,表示转义,所以\%就是普通的%
SQL Server 支持更多的通配符:'[ad]' 匹配 'a' 和 'd';'[a-d]' 匹配 'a' 、'b'、'c' 和 'd';'[^ad]' 匹配除了 'a' 和 'd' 之外的其他字符。
大小写匹配:
在使用 LIKE 查找数据时,还需要注意的一个问题就是大小写。对于汉字,不需要区分大小写;但是英文字母却有大小写之分,“A”和“a”是两个不同的字符。不过,4 种数据库对此采取了不同的处理方式:
Oracle 和 PostgreSQL 默认区分 LIKE 中的大小写,PostgreSQL 提供了不区分大小写的 ILIKE 运算符;MySQL 和 SQL Server 默认不区分 LIKE 中的大小写。
正则表达式:
正则表达式用于检索或者替换符合某个模式(规则)的文本。很多的编程语言和编辑工具都提供了正则表达式搜索和替换,比如文本编辑器 Notepad++
正则表达式的具体使用不会说的特别细致,网上一大堆可以去搜索。这里简单提一下:^ 匹配字符串的开头;[a-zA-Z0-9] 匹配大小写字母或数字;+ 表示匹配前面的内容一次或多次;. 匹配任何一个字符,. 匹配点号自身;{2,4} 匹配前面的内容 2 次到 4次;$ 匹配字符串的结束。
我们看到这个正则跟主流编程语言的正则是比较类似的,但是如何使用正则表达式,我们需要调用哪个函数呢?
Oracle 和 MySQL 支持类似的正则表达式函数:REGEXP_LIKE(source_str, pattern [, match_type])。其中source_str表示被搜索的字符串,pattern表示模式,match_type指定可选的匹配方式,例如 i 表示不区分大小写,c 表示区分大小写。
但是对于PostgreSQL来讲,是通过波浪线~来进行匹配的
~ 匹配某个正则表达式,区分大小写;~* 匹配某个正则表达式,不区分大小写!~ 不匹配某个正则表达式,区分大小写;!~* 不匹配某个正则表达式,不区分大小写。
我这里使用的是PostgreSQL,就以它为例了。
select id from people
where id ~ '0101000[1458]{2}[2579]{2}';
/*
01010005159
*/
SQL Server 中没有提供相关的正则表达式函数或者运算符。
小结
SQL 支持使用模式匹配对文本内容进行模糊查找,主要的方式有两种:LIKE 运算符和正则表达式函数或运算符。其中,LIKE 运算符通用性更好,但是只能进行一些简单的模糊匹配;正则表达式函数功能更加强大,但是依赖于不同数据库的实现,虽然函数不同,但是语法都是差不多的。并且,数据库的正则语法非常类似于python语言的正则,走的应该也是Perl风格的。
使用order by对数据进行排序显示
正文
上面我们讨论了如何使用 LIKE 运算符和正则表达式函数进行文本数据的模糊查找。但是有时候返回的数据的顺序未必使我们希望的,这是因为 SQL 在查询时不保证返回结果的顺序。
如果想要查询的结果按照某种规则进行排序,例如按照工资从高到低排序,可以使用 SQL 中的 ORDER BY 子句。
单列排序:
按照单个字段或者表达式的值进行排序称为单列排序。单列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 [ASC | DESC];
其中,ORDER BY 用于指定排序的字段;ASC 表示升序排序(Ascending),DESC 表示降序排序(Descending),默认值为升序排序。
select pk, id, level from people
where level = '经济师';
/*
10 01010000033 经济师
11 01010000980 经济师
3 01010000042 经济师
4 01010004180 经济师
*/
--按照pk进行排序,默认升序
select pk, id, level from people
where level = '经济师' order by pk;
/*
3 01010000042 经济师
4 01010004180 经济师
10 01010000033 经济师
11 01010000980 经济师
*/
--降序排序,加上desc
select pk, id, level from people
where level = '经济师' order by pk desc;
/*
11 01010000980 经济师
10 01010000033 经济师
4 01010004180 经济师
3 01010000042 经济师
*/
该查询中使用了 WHERE 过滤条件,此时 ORDER BY 子句位于 WHERE 之后。
对于升序排序,数字按照从小到大的顺序排列,字符按照编码的顺序排列,日期时间按照从早到晚的顺序排列;降序排序正好相反。
多列排序:
多列排序是指基于多个字段或表达式的排序,使用逗号进行分隔。多列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 ASC, col2 DESC, ...;
首先基于第一个字段进行排序;对于第一个字段排序相同的数据,再基于第二个字段进行排序;依此类推。
--我们按照age进行排序,但是里面还使用了where,where要放在order by的前面
select pk, id, age from people
where level in ('经济师', '工程师') order by age;
/*
8 01010009350 30
13 01010005708 30
24 01010000061 33
11 01010000980 33
2 01010004641 35
10 01010000033 40
3 01010000042 44
4 01010004180 50
*/
-- 但是会发现,如果年龄一样怎么办呢?那么谁排在前面呢,答案是不确定
-- 所以我们需要再指定一个字段,比如pk。先按照age升序排序,如果age一样,那么按照pk升序排序
select pk, id, age from people
where level in ('经济师', '工程师') order by age, pk;
/*
8 01010009350 30
13 01010005708 30
11 01010000980 33
24 01010000061 33
2 01010004641 35
10 01010000033 40
3 01010000042 44
4 01010004180 50
*/
中文排序:
在创建数据库或者表时,我们会指定一个字符集(Charset)和排序规则(Collation)。
字符集决定了数据库能够存储哪些字符,比如 ASCII 字符集只能存储简单的英文、数字和一些控制字符;GB2312 字符集可以存储中文;Unicode 字符集能够支持世界上的各种语言。
排序规则定义了字符集中字符的排序顺序,包括是否区分大小写,是否区分重音等。对于中文而言,排序方式与英文有所不同;中文通常需要按照拼音、偏旁部首或者笔画进行排序。
如果想要支持中文排序,最简单的方式就是使用支持中文排序的排序规则;但是常见的 Unicode 字符集默认不支持中文排序。所以我们需要解决这种情况下的中文排序问题。
首先是 Oracle,使用 AL32UTF8 字符编码时不支持中文排序规则,可以通过一个转换函数实现该功能。比如按照姓名的拼音进行排序:
-- Oracle 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY NLSSORT(name,'NLS_SORT = SCHINESE_PINYIN_M');
/*
NLSSORT 是一个函数,返回了按照某种排序规则得到的字符序列;SCHINESEPINYINM 表示中文的拼音排序规则。
Oracle 还支持按偏旁部首进行排序:SCHINESE_RADICALM,以及按笔画进行排序:SCHINESE_STROKEM。
*/
再来看一下 MySQL 的中文排序。MySQL 8.0 默认使用 utf8mb4 字符编码,不支持中文排序规则。以下语句按照姓名的拼音进行排序:
-- MySQL 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY CONVERT(name USING GBK);
/*
CONVERT 是一个函数,用于转换数据的字符集编码;这里是中文 GBK 字符集,默认使用拼音排序。该语句的结果和上面的 Oracle 示例一样。
*/
对于 SQL Server,字符集和排序规则是同一个概念。如果需要存储中文,需要使用相应的排序规则,例如 Chinese_PRC_CI_AI_WS;。以下查询按照员工姓名的拼音进行排序:
-- SQL Server 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY name COLLATE Chinese_PRC_CI_AI_WS;
/*
COLLATE 表示按照某种排序规则进行排序;如果数据库使用的是 Chinese_PRC_CI_AI_WS 排序规则,可以省略 COLLATE 选项。该语句的结果和上面的 Oracle 示例一样。
*/
最后,PostgreSQL 默认使用 UTF8 编码字符集,不支持中文排序规则。以下示例按照员工姓名的拼音进行排序:
-- PostgreSQL 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY name COLLATE "zh_CN";
/*
COLLATE 指定了中文排序规则 zh_CN,该语句的结果和上面的 Oracle 示例一样。
*/
空值排序:
空值(NULL)在 SQL 中表示未知或者缺失的值。如果排序的字段中存在空值时,会怎么样呢?由于比较简单,自己测试一下就知道了,这里直接说结论:
- MySQL 和 SQL Server 认为空值最小,升序时空值排在最前,降序时空值排在最后;
- Oracle 和 PostgreSQL 认为空值最大,升序时空值排在最后,降序时空值排在最前;同时支持使用 NULLS FIRST 和 NULLS LAST 指定空值的顺序。
解决空值的排序问题还有一个更通用的方法,就是利用 COALESCE 函数将空值转换为一个指定的值。例如,将奖金为空的数据转换为 0,这样升序排序时一定在最前。当然即使不排序,我们在筛选字段的时候,如果存在空值,我们也可以替换成默认的值。
select pk, id, level from people
where pk > 20;
/*
21 01010007487 <null>
22 01010011253 会计师
23 01010011517 <null>
24 01010000061 工程师
*/
--通过coalesce指定默认值
select pk, id, coalesce(level, '新来的') from people
where pk > 20;
/*
21 01010007487 新来的
22 01010011253 会计师
23 01010011517 新来的
24 01010000061 工程师
*/
关于函数我们后面会说。
小结
ORDER BY 子句可以将查询的结果按照某种规则进行排序。排序方式分为升序和降序;可以基于单列或表达式排序,也可以基于多列或多个表达式排序。中文排序需要字符集和排序规则的支持,不同数据库的实现各不相同。另外,还需要注意空值的排序问题。
如何实现排行榜和前端分页效果
正文
我们上面讨论了如何利用 ORDER BY 子句实现查询结果的排序。对数据进行排序之后,还可以进一步进行处理。我们经常会看到各种 Top-N 排行榜,例如十大热门金曲、电影排行榜、游戏排行榜等。另外,在客户端显示数据时通常不是一次列出所有的结果,而是每次显示 N 条(10、20、50 等)记录;然后提供“下一页”、“上一页”等翻页功能。本篇我们就来了解一下如何使用 SQL 语句实现以上两种常见的功能。
Top-N 排行榜:
Top-N 排行榜的原理就是先排序,再返回前 N 条记录。
实现 Top-N 排行榜的方式主要有两种:
- 标准 SQL 提供的 FETCH 语法;
- 另一种常见的 LIMIT 语法。
比如我们查看员工年龄最小的前五位。
-- Oracle、SQL Server 以及 PostgreSQL 支持
--表示先按照age升序排序,然后选取前5条
select pk, id, age from people
order by age fetch first 5 rows only offset 0;
/*
17 01010011791 21
15 01010010925 24
9 01010011790 24
22 01010011253 25
14 01010010579 27
*/
--这里的语法规则就是,假设选取n条,那么就是fetch first n rows only
--后面的offset则表示偏移量,表示从第几条开始取5条,我们这里是0,表示从头开始,当然默认也是从头开始的
--假设我们从第三条开始取三条,从第三条开始则代表偏移量为2
select pk, id, age from people
order by age fetch first 3 rows only offset 2;
/*
9 01010011790 24
22 01010011253 25
14 01010010579 27
*/
-- 结果正好是上面结果的最后三条
以上使用的是fetch,然后例子不变,使用limit演示一下,个人用的最多的还是limit。
-- MySQL 以及 PostgreSQL 支持
select pk, id, age from people
order by age limit 5 offset 0;
/*
17 01010011791 21
15 01010010925 24
9 01010011790 24
22 01010011253 25
14 01010010579 27
*/
select pk, id, age from people
order by age limit 3 offset 2;
/*
9 01010011790 24
22 01010011253 25
14 01010010579 27
*/
我们发现使用limit貌似变得方便多了,当然了两个offset的含义都是一样的。
分页效果:
现在我们肯定能够明白分页效果是怎么做的了,分页查询的原理就是先跳过指定的行数,再返回 Top-N 记录。
小结
查询语句中的 FETCH 和 OFFSET 子句可以限定返回结果的数量和偏移量,从而实现排行榜和分页查询效果。LIMIT 和 OFFSET 子句也是实现该功能的一种常见的用法。另外,某些数据库还实现了其他的替代方式。
什么是函数?如何利用函数提高数值计算的效率
正文
SQL 语句主要的功能就是对数据进行处理和分析。为了避免重复造轮子,提高数据处理的效率,SQL 为我们提供了许多标准的功能模块:函数(Function)。实际上我们已经使用过 SQL 函数,例如截取字符串指定部分的substr函数。
函数概述:
SQL 函数是一种具有某种功能的模块,可以接收零个或多个输入值,并且返回一个输出值。
在 SQL 中,函数主要分为两种类型:
- 标量函数(scalar function)。标量函数针对每个输入参数,返回一个输出结果。例如,ABS(x) 可以计算 x 的绝对值。
- 聚合函数(aggregate function)。聚合函数基于一组数据进行计算,返回一个输出结果。例如,AVG 函数可以计算一组数据的平均值。
我们先介绍标量函数,聚合函数将会在后续进行介绍。为了方便学习,我们将常见的 SQL 标量函数分为以下几类:数值函数、字符函数、日期函数以及类型转换函数。先只介绍数值函数。

这个比较简单,应该不用演示了,我们来随便挑几个吧。
--我们没有使用from,这是数据库自己支持的。
--所以我们说这种方式很适合学习一些函数
select abs(-1), ceil(3.5), floor(3.5),
sqrt(4);

最后我们来看一下random函数,我们这个函数会返回一个0-1的随机数。
select id, random() from people limit 5;
/*
01010009350 0.9424830074422061
01010011790 0.7888742927461863
01010000033 0.46751561388373375
01010000980 0.7419315502047539
01010005699 0.5436281533911824
*/
--我们看到,给每一个记录都加上了一个随机数
--那么它可以干什么呢?显然可以进行随机的样本选择
select id from people order by random()
limit 5;
/*
01010005708
01010007487
01080000060
01010005159
01010005699
*/
--我们按照random()进行排序,当然,即使random()不在字段里面也是可以的
--然后选择前5个幸运员工,当然由于random()是随机的,所以选择的员工也是随机的
小结
掌握常见的 SQL 函数将会方便我们进行数据的处理和分析,避免重复实现已有的功能。本篇主要介绍了常见的数值函数,大多数函数都可以在不同的数据库之间通用,但是也存在一些数据库专有的函数实现。
SQL 常见函数之文本数据处理
正文
上面我们介绍了 SQL 中常见的数值函数。接下来我们继续学习用于处理文本数据的字符函数。
字符函数:
字符函数用于字符数据的处理,例如字符串的拼接、大小写转换、子串的查找和替换等。下表列出了 SQL 中常见的字符函数:
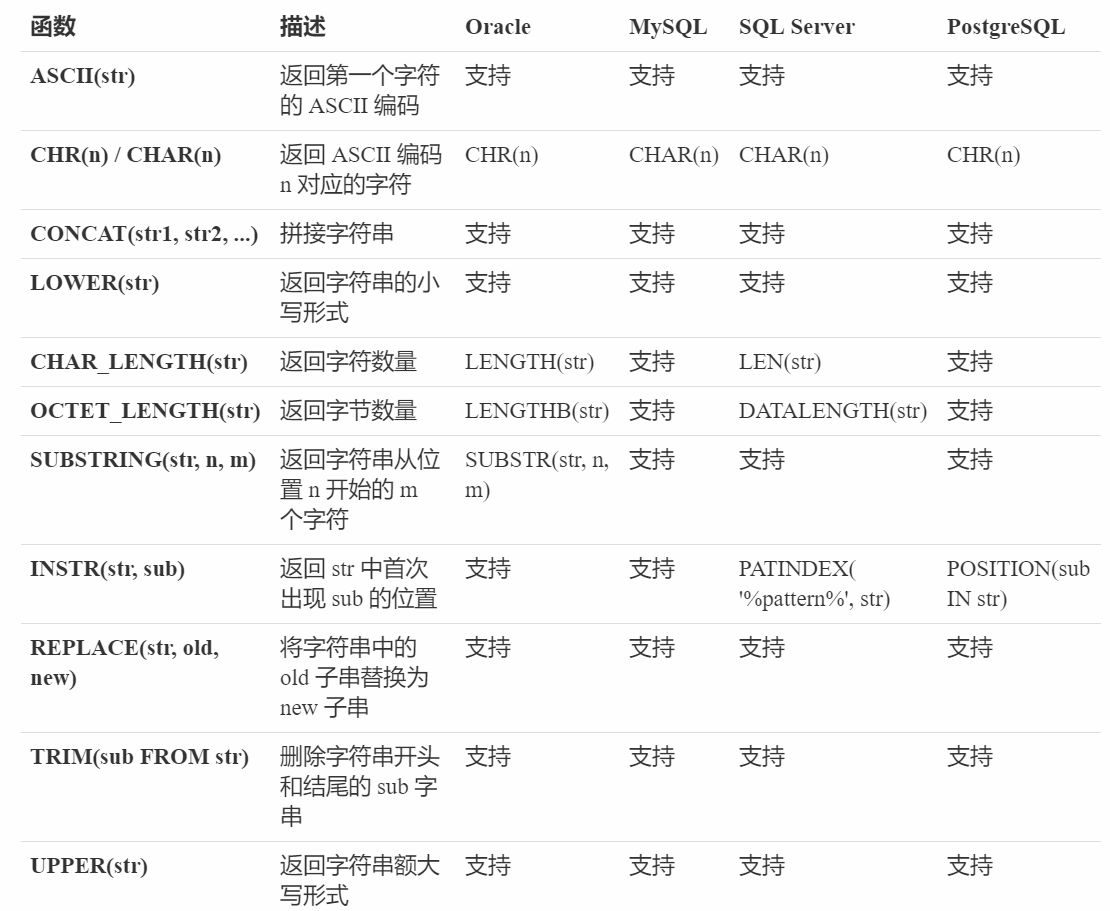
我们通过示例说明一下这些函数的作用,当然不会全部举例,会介绍一些常用的。
--即便里面出现了数字也无所谓,甚至全部是数字都行,会把里面的内容统统解释成字符串
select concat('你好', 123, '啊'); -- 你好123啊
--对于PostgreSQL来说,字符串拼接还可以使用||,但是||要求至少要有一方是字符串
--比如1||2||3就是不行的,因为全部是数字,||要求两边至少有一边是字符串,因此我们可以通过::text转化成字符串
select 1::text || 2 || 3; -- 123
-- 另外||的顺序,是从左到右依次拼接,尽管第二个||左右两边都是数字,但是先拼接第一个||两边的内容,拼接完之后就变成了字符串
-- 我们我们只需要将第一个||的左边或者右边的元素变成字符串类型即可
-- 字符串变小写 变大写
select lower('SaTori'), upper('SaTori'); -- satori SATORI
-- 返回字符的数量 返回字节的数量,一个汉字三个字节
select char_length('古明地觉'), octet_length('古明地觉'); -- 4 12
-- 返回字符串的指定位置的字符,索引从1开始
-- substr和substring对于PostgreSQL来说都可以
-- 表示从第2个字符开始选,选6个
select substr('where are you', 2, 6); -- here a
-- 查找某个子串在字符串中首次出现的位置,这是PostgreSQL的语法
-- 索引从1开始
select position('to' in 'satori'); -- 3
-- 将字符串中的指定字符替换成其它的字符
-- 下面将空格全部换成空字符
select replace('I Love Satori', ' ', ''); -- ILoveSatori
-- 删除字符串开头和结尾位于子串的部分,直接说比较难理解,我们距离说明
select trim('~ab' from '~~abXXXXb'); -- XXXX
--从两端开始,如果字符在'~ab'当中,那么就删掉,直到出现一个不在'~ab'中的字符
现在我们有一个需求,将people中的level字段的倒数第二个字符串换成*、然后去重返回,要怎么做呢?
-- 首先肯定是replace(level, '倒数第二个字符', '*')
-- 那么如何找到倒数第二个字符呢?显然是substr
-- replace(level, substr(level, '倒数第二个字符的位置', 1), '*')
-- 计算倒数第二个字符的位置,显然使用char_length
-- replace(level, substr(level, char_length(level) - 1, 1), '*')
-- 然后再通过distinct去重即可
select distinct(replace(level, substr(level, char_length(level) - 1, 1), '*'))
from people;
/*
<null>
助理工*师
高级政*师
助理*员
经*师
工*师
经*员
助理经*师
会*师
*/
小结
本篇介绍了常见的字符函数,掌握这些函数可以方便我们对文本数据进行清洗和转换等处理。除了这些函数之外,各种数据库还提供了大量的字符处理函数。当我们需要实现某种操作时,可以先查找数据库的文档,避免重复实现已有的功能。
日期和时间的存储与格式转换
正文
刚才我们介绍了 SQL 中常见的字符函数,学习了如何对文本数据进行连接、大小写转换、子串的查找和替换等处理。下面我们继续讨论常见的日期和时间函数,以及不同数据类型之间的转换函数。
日期和时间的存储:
在数据库中,日期时间类型存在 3 种形式:
- DATE,日期类型,包含年、月、日。可以用于存储出生日期、入职日期等。
- TIME,时间类型,包含时、分、秒,以及小数秒。一般使用较少。
- TIMESTAMP,时间戳类型,包含年、月、日、时、分、秒,以及小数秒。用于对时间精度要求比较高的场景,比如存储订单时间。
TIMESTAMP 和 TIME 还可以添加 WITH TIME ZONE 选项,用于指定一个时区偏移量。例如,UTC 标准时间的 0 点等于北京时间的早上 8 点。时区选项通常用于支持全球化的应用系统中。
以下是 4 种数据库对于日期时间类型的支持情况。
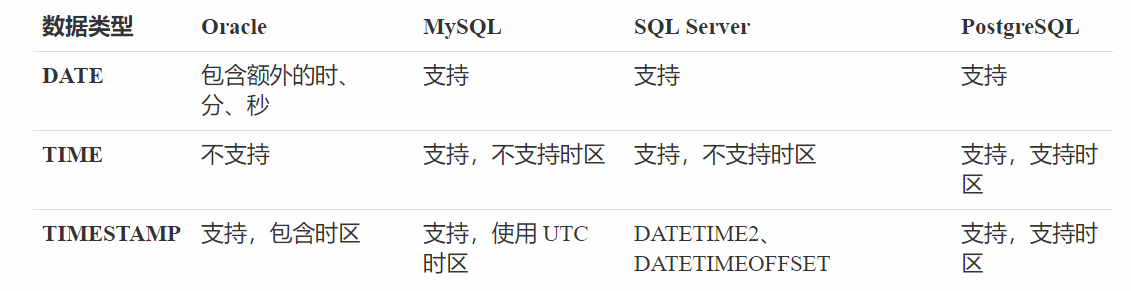
其中,Oracle 的 DATE 类型包含了日期和时间两部分,但不支持 TIME 类型。MySQL 还提供了 DATETIME 日期时间类型。
日期时间函数:
日期时间函数用于操作日期和时间数据,例如获取当前日期、为指定日期增加天数,计算两个日期之间的差或者获取日期的部分信息。下表列出了 SQL 中常见的日期时间函数:
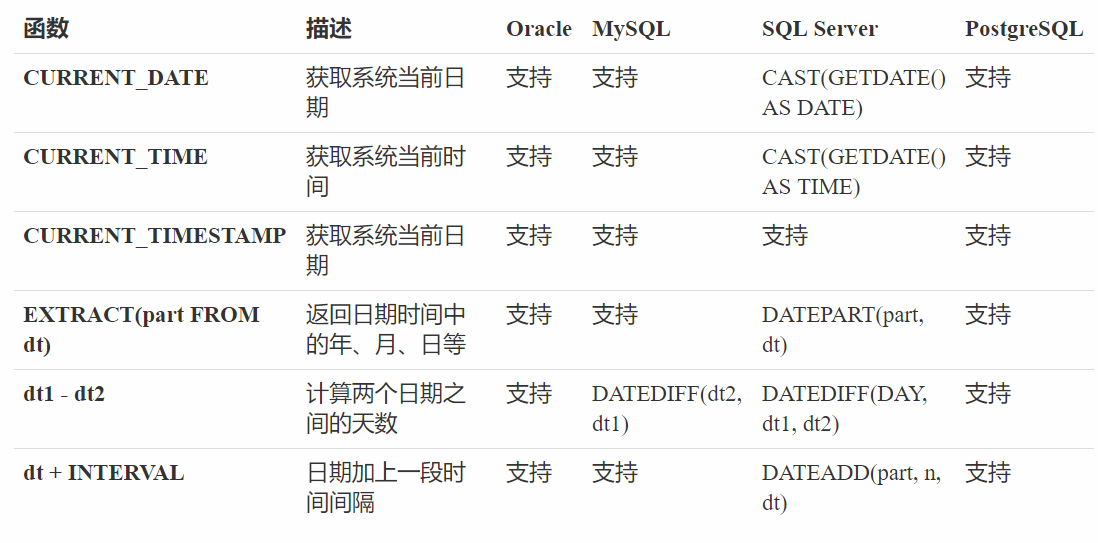
我们以PostgreSQL为例子演示一下这几个函数的用法:
-- 当前日期
select current_date; -- 2020-03-07
-- 当前时间
select current_time; -- 08:33:38.352962
-- 当前日期加上时间,除了current_timestamp,还可以通过now()来获取
select current_timestamp; -- 2020-03-07 08:33:38.653528
-- 截取指定部分
select extract(year from current_timestamp),
extract(month from current_timestamp),
extract(day from current_timestamp);
-- 2020 3 7
select extract(hour from current_timestamp),
extract(minute from current_timestamp),
extract(second from current_timestamp)
-- 8 33 39.021131
除此之外,两个日期、时间之间也是可以相减的,得到的是一个interval(时间间隔)类型。
-- 表示两者之间 相差796天、4个小时、24分、49秒
select now() - '2018-1-1 12:14:50'; -- 796 days 04:24:49.680551
-- 当然日期、时间还可以加上interval
-- 别忘记将字符串进行转换
select '2018-1-1'::date + '7 day'::interval; -- 2018-01-08 00:00:00.000000
-- 再比如我有一个日期类型的数据 2018-02-02,我要在当然日期上面加上前者的月份
select current_date + (extract(month from '2018-2-2'::date) || 'month')::interval; -- 2020-05-07 00:00:00.000000
-- 解释一下,首先"n year"::interval 就表示时间间隔n年 同理 "n month"::interval表示时间间隔n月
-- 当然还有day、hour什么的
-- extract(month from '2018-2-2'::date)解析出来月份,然后和month进行拼接,最后转成interval类型,再相加
-- 另外,我这个是PostgreSQL语法,支持通过::来进行类型转化,但是其它数据库则不一定支持,因此注意自己所使用的数据库
类型转换函数:
CAST(expr AS type) 函数用于将数据转换为不同的类型。以下是一个类型转换的示例:
select cast('123' as int) + 234; -- 357
select '123'::int + 234; -- 357
-- 对于PostgreSQL来说,以上是等价的
小结
这一节我们介绍了日期和时间数据类型以及相关的函数,同时了解了数据类型之间的显式转换和隐式转换。到此为止,我们已经学习了 SQL 中各种常见的标量函数。
如何为 SQL 增加 IF-THEN-ELSE 逻辑,并且实现行列转换
正文
上一节我们学习了 SQL 中常见的日期时间函数和类型转换函数,熟练使用各种函数可以让我们的数据处理和分析工作事半功倍。
本篇我们介绍一种为 SQL 语句增加逻辑处理功能的方法:CASE 表达式。
SQL 中的 CASE 表达式可以根据不同条件产生不同的结果,实现类似于编程语言中的 IF-THEN-ELSE 逻辑功能。例如,根据员工的 KPI 计算相应的涨薪幅度,根据考试成绩评出优秀、良好、及格等。
CASE 表达式支持两种形式:简单 CASE 表达式和搜索 CASE 表达式。
简单 CASE 表达式:
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
...
[ELSE default_result]
END
/*
首先计算 expression 的值;然后依次与 WHEN 列表中的值(value1,value2,…)进行比较,找到第一个相等的值并返回对应的结果(result1,result2,…);如果没有找到相等的值,返回 ELSE 中的默认结果;如果此时没有指定 ELSE,返回 NULL 值。
*/
select age,
case age
when 30 then '三十'
when 35 then '三十五'
when 40 then '四十'
else '不是三十、三十五、四十'
end as age1
from people;

CASE 表达式的一个常见应用就是实现行列转换。
-- 创建成绩表 t_case,sname 为学生姓名,cname 为课程名称,score 为考试成绩
CREATE TABLE t_case(sname varchar(10), cname varchar(10), score int);
-- 插入测试数据
INSERT INTO t_case(sname, cname, score) VALUES ('张三', '语文', 80);
INSERT INTO t_case(sname, cname, score) VALUES ('李四', '语文', 77);
INSERT INTO t_case(sname, cname, score) VALUES ('王五', '语文', 91);
INSERT INTO t_case(sname, cname, score) VALUES ('张三', '数学', 85);
INSERT INTO t_case(sname, cname, score) VALUES ('李四', '数学', 90);
INSERT INTO t_case(sname, cname, score) VALUES ('王五', '数学', 60);
INSERT INTO t_case(sname, cname, score) VALUES ('张三', '英语', 81);
INSERT INTO t_case(sname, cname, score) VALUES ('李四', '英语', 69);
INSERT INTO t_case(sname, cname, score) VALUES ('王五', '英语', 82);
执行以上语句创建 t_case 表并且插入数据。该表中的数据如下:

现在我们要把表变成这样的形式:

我们便可以通过case来解决:
SELECT sname,
CASE cname WHEN '语文' THEN score ELSE 0 END AS "语文",
CASE cname WHEN '数学' THEN score ELSE 0 END AS "数学",
CASE cname WHEN '英语' THEN score ELSE 0 END AS "英语"
FROM t_case;
第一个 CASE 表达式用于获取学生的语文成绩,cname 等于“语文”就返回考试成绩,不是“语文”就记为 0 分。第二个和第三个 CASE 表达式分别用于获取数学和英语成绩,原理和第一个 CASE 表达式相同。该语句执行的结果如下:
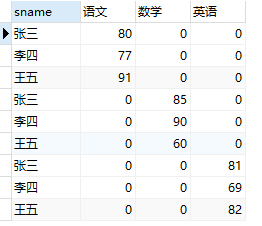
已经有那么回事了,然后再聚合一下即可,聚合我们后面会说:
SELECT sname,
SUM(CASE cname WHEN '语文' THEN score ELSE 0 END) AS "语文",
SUM(CASE cname WHEN '数学' THEN score ELSE 0 END) AS "数学",
SUM(CASE cname WHEN '英语' THEN score ELSE 0 END) AS "英语"
FROM t_case
GROUP BY sname;

我们看到已经实现了,因此case语句还是能做很多事情的,但是简单 CASE 表达式在进行判断的时候,使用的是等值比较(=),只能处理简单的逻辑。如果想要进行复杂的逻辑处理,例如根据考试成绩评出优秀、良好、及格等,就需要使用更加强大的搜索 CASE 表达式。
搜索 CASE 表达式:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
[ELSE default_result]
END
按照顺序依次计算每个分支中的条件(condition1,condition2,…),找到第一个结果为真的分支并返回相应的结果(result1,result2,…);如果没有任何条件为真,返回 ELSE 中的默认结果;如果此时没有指定 ELSE,返回 NULL 值。
所有的简单 CASE 表达式都可以替换为等价的搜索 CASE 表达式,我们刚才的例子就可以改写成如下:
select age,
case
when age = 30 then '三十'
when age = 35 then '三十五'
when age = 40 then '四十'
else '不是三十、三十五、四十'
end as age1
from people;
我们看到可以通过case 字段,然后when后面写一个值,来判断字段的值和when后面的值是否相等,但这也仅能判断相等的情况。如果是更复杂的情况,那么就要使用搜索case表达式,也就是case后面什么也不用加,直接把条件写在when后面,这样不仅能判断相等的情况,还可以进行更复杂的判断。
select age,
case
when age < 30 then '青年'
when age < 45 then '中年'
when age < 60 then '老年'
else '耄耋'
end as age1
from people;
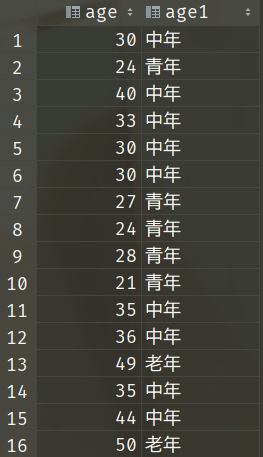
CASE 表达式除了可以用于查询语句的 SELECT 列表,也可以出现在其他子句中,例如 WHERE、ORDER BY 等。
select age,
level
from people
where level not in ('工程师', '经济师', '会计师');
/*
30 助理工程师
27 助理馆员
24 经济员
28 助理经济师
49 高级政工师
38 助理经济师
33 助理经济师
33 助理经济师
*/
-- 我们注意到,如果没有is null或者is not null之类的判断的话
-- 那么默认where后面是不包含null的,也就是在判断的时候直接就不考虑null值了
select age,
level
from people
where case
when level not in ('工程师', '经济师', '会计师') then true
when level is null then true
end
;
/*
24 <null>
30 助理工程师
27 助理馆员
24 经济员
28 助理经济师
21 <null>
49 高级政工师
38 助理经济师
33 助理经济师
31 <null>
41 <null>
33 助理经济师
*/
-- 我们注意到这样就筛选出来了,如果满足条件我们就标记为true
-- 一旦where后面的是true,那么这一行就会保留,所以当level为空的时候,我们也标记为true即可
order by也是类似的,可以自己尝试。
CASE 表达式是标准的 SQL 功能,所有数据库都支持并且实现一致。除此之外,Oracle 还提供了一个专有函数:DECODE。
DECODE(expression, value1, result1, value2, result2, ...[, default_result ])
该函数依次比较表达式 expression 与 valueN 的值,如果找到相等的值就返回对应的 resultN;如果没有匹配到任何相等的值,返回默认结果 default_result;如果此时没有提供 default_result,返回 NULL 值。DECODE 是 Oracle 专有函数,推荐大家使用标准的 CASE 表达式。
MySQL 中的 DECODE 函数是一个解密函数,与此无关。。
小结
CASE 表达式为 SQL 语句提供了逻辑处理的能力,可以基于不同的条件返回不同的结果。CASE 表达式支持两种形式:简单 CASE 表达式和搜索 CASE 表达式。
聚合函数对数据进行汇总
正文
在上节行转列的示例中,我们使用了 SUM 函数;它是一个聚合函数,可以对数据进行汇总求和。SQL 提供了许多这类函数,本篇我们就来学习如何利用聚合函数实现数据报表中的汇总分析。
聚合函数:
汇总分析是数据报表中的基本功能,例如销售额度的汇总统计、计算学生的平均身高以及标准差等。为此,SQL 提供了许多具有汇总功能的聚合函数。
在 SQL 中,聚合函数(Aggregate Function)用于对一组数据进行汇总计算,并且返回单个分析结果。常见的聚合函数包括:
- COUNT,统计查询结果的行数;
- AVG,计算一组数值的平均值;
- SUM,计算一组数值的总和;
- MAX ,计算一组数据中的最大值;
- MIN,计算一组数据中的最小值;
- VAR_SAMP、STDDEV_SAMP,计算一组数据的方差和标准差。
接下来我们分别演示这些函数的作用。
-- 查看总数,对于count,可以使用count(*)、count(字段),甚至是count(1)也可以
select count(*), count(age), count(1) from people; -- 24 24 24
-- 当前记录总数为24
-- 在聚合函数的参数中加上 DISTINCT 关键字,可以在计算之前排除重复值;
select count(distinct(age)) from people; -- 17
-- 聚合函数在计算时,忽略输入值为 NULL 的数据行;
-- 如COUNT(level)计算的是level不为null的数量,但是count(*)和count(1)例外,它们计算的是总数。
select count(level) from people; -- 20
-- avg计算平均值,sum计算总和
-- 因此avg(age)和sum(age) / count(age)是等价的,只不过后者自动取整了
select avg(age), sum(age) / count(age) from people; -- 34.2083333333333333 34
-- max计算最大值,min计算最小值
select max(age), min(age) from people; -- 51 21
计算方差和标准差:
统计学中通常使用方差(Variance)和标准差(Standard Deviation)衡量数据的离散程度,结果越小表示数据越集中。例如在打靶比赛中,两人的平均分都是 9 环,此时方差/标准差越小说明发挥越稳定。
SQL 定义了计算样本方差/标准差和总体方差/样本差的函数,它们在各种数据库中的实现如下:
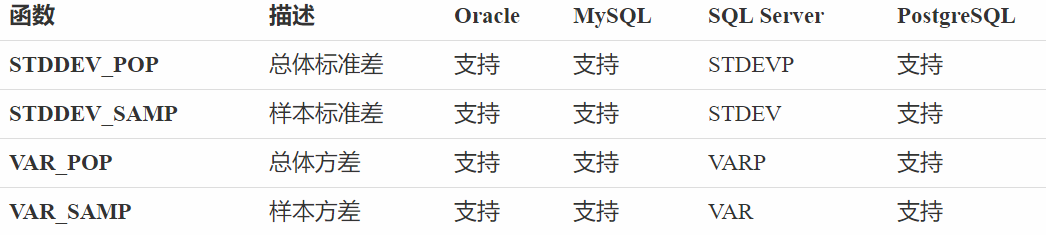
在 Oracle 和 PostgreSQL 中,STDDEV 函数也可用于计算样本标准差,VARIANCE 函数也可用于计算样本方差。 在 MySQL 中,STDDEV、STD 函数也可用于计算总体标准差,VARIANCE 函数也用于计算样本方差。
Oracle、MySQL 以及 PostgreSQL 都与标准一致,SQL Server 使用专有的函数名。
Oracle 和 MySQL 中的这些统计函数不支持 DISTINCT 参数;SQL Server 和 PostgreSQL 中的这些统计函数支持 DISTINCT 参数,在计算之前排除重复的值,但是这么做通常没有什么意义。另外,这些函数在计算时自动忽略 NULL 值。
小结
聚合函数可以用于数据的汇总分析,本篇介绍了如何使用 SQL 聚合函数统计行数、平均值、总和、最大值、最小值以及统计学中的方差和标准差。
group by分组统计
正文
上节我们学习了如何利用 SQL 聚合函数对数据进行汇总分析。聚合函数在单独使用时,会将所有的数据作为一个整体(分组)进行统计;因此上一节中的示例都只返回了一个结果。
但是在实际应用中,我们通常需要将数据按照某些规则进行分组,然后分别进行汇总统计。例如,按照部门计算员工的平均月薪,按照不同的产品和渠道统计销售金额等。为了实现这种分组统计的功能,需要将聚合函数与分组操作(GROUP BY)一起使用。
数据分组:
SQL 中的 GROUP BY 子句可以将数据按照某种规则进行分组。以下示例使用 GROUP BY 将员工按照degree进行分组:
select degree from people group by degree;
/*
大学专科毕业
大学本科毕业
研究生毕业
*/
GROUP BY 将degree的每个不同取值分为一组,每个组返回一条记录。由于员工表中只存在三种不同的degree,所以返回的结果只有三条记录。该语句使用 DISTINCT 关键字的效果相同
多字段分组:
GROUP BY 也可以基于多个字段或表达式进行分组。
select degree, level from people group by degree, level;
/*
大学本科毕业 经济师
大学本科毕业 会计师
研究生毕业 会计师
研究生毕业 助理经济师
大学本科毕业 助理经济师
大学本科毕业 工程师
大学本科毕业 助理工程师
大学本科毕业 高级政工师
大学本科毕业
大学本科毕业 助理馆员
大学专科毕业 经济员
*/
以上则是根据degree和level进行分组,也就是说degree和level组合起来没有重复的。
然而我们在分组的时候,绝大部分都是搭配聚合函数使用
基于分组字段,将不同的值分为n组,然后在组内分别应用聚合函数进行统计,每个组返回一个结果
select degree, count(*) from people group by degree;
/*
大学专科毕业 1
大学本科毕业 21
研究生毕业 2
*/
以上表示按照degree进行分组,然后通过相同的degree对应的数量
select degree, avg(age) from people group by degree order by avg(age);
/*
大学专科毕业 24
研究生毕业 26.5
大学本科毕业 35.4285714285714286
*/
以上表按照degree进行分组,然后计算相同的degree对应的一组age的平均值,并按照平均值的大小升序排序
当然group by后面可以跟多个字段,另外group by后面也是可以跟表达式的。
select extract(year from start), avg(age) from people group by extract(year from start);
/*
2018 28.6666666666666667
2012 30
2000 40
2007 33
2011 30
2014 27
1999 38
1992 48.3333333333333333
2009 33.3333333333333333
2006 34.3333333333333333
1990 49
2017 26.5
2015 24
*/
表示按照start的year部分进行聚合
空值分组:
对于分组操作而言,同样需要注意空值问题。对于 GROUP BY,如果分组字段中存在多个 NULL 值,它们将被分为一个组。
select count(age), level from people group by level;
/*
4 <null>
1 高级政工师
1 助理工程师
4 工程师
1 经济员
4 助理经济师
4 经济师
4 会计师
1 助理馆员
*/
从查询结果可以看出,4个员工的level字段为空;但是他们都被分组同一个组中,而不是多个不同的组。
常见错误:
在使用分组汇总时,初学者常见的一个错误就是在 SELECT 列表中使用了既不是聚合函数,也不属于分组字段的字段。例如:
select level, degree, sum(age)
from people
group by level;
以上语句会返回一个错误:字段 degree没有出现在 GROUP BY 子句或者聚合函数中。举个栗子,我们按照level进行分组,level字段中值相同的会分为一组,然后对该组的age进行sum,那么存在总数减少的情况,如果数量一样,只能说明level字段没有重复的。但事实上,我们也不会对一个值都不重复的字段进行group by,按照level聚合之后,总数减少。但是我们没有对degree使用聚合函数,那么degree的数量还和表的总数量一样,如此一来就会产生冲突。所以一旦使用了聚合函数,那么select后面的字段要么出现在聚合函数里面,要么出现在group by后面。
所以上面的例子我们有两种修改方式
-- 我们对degree也使用聚合
select level, count(degree), sum(age)
from people
group by level;
-- 或者让degree也出现在group by后面
select level, degree, sum(age)
from people
group by level, degree;
我们说select后面的字段如果不在聚合函数里面,那么必须在group by字句中,但是group by字句中的字段则不一定要出现在select中
select sum(age)
from people
group by level, degree;
我们按照level和degree进行分组,但是level和degree并没有出现在select语句中,这是正确的语法。
分组后的过滤:
我们知道 WHERE 条件可以用于过滤表中的数据。但是如果需要针对分组之后的结果进行过滤,是不是也可以使用 WHERE 实现呢?答案是不可以,WHERE 子句中不允许使用聚合函数。因为 SQL 中的 WHERE 子句在 GROUP BY 子句之前执行(关于执行顺序,我们后面会说),它是针对 FROM 中的表进行数据过滤。也就是说,WHERE 子句执行时还没有进行分组操作,所以where后面不能跟聚合函数。
为了支持基于汇总结果的过滤,SQL 提供了 HAVING 子句;同时要求 HAVING 必须与 GROUP BY 一起使用。
select degree, count(age)
from people
group by degree;
/*
大学专科毕业 1
大学本科毕业 21
研究生毕业 2
*/
select degree, count(age)
from people
group by degree
having count(age) > 2;
/*
大学本科毕业 21
*/
但是having后面的聚合并不一定是select后面的聚合,比如:
select degree
from people
group by degree having count(age) > 2;
/*
大学本科毕业
*/
我们看到count(age)并没有在select后面,我们只是选择degree,选择按照其分组之后count(age)、或者说对应组的记录数大于2的degree
因此,在 SQL 语句中可以使用 WHERE 子句对表进行过滤,同时使用 HAVING 对分组结果进行过滤。
select degree, count(age)
from people where age > 30
group by degree having count(age) > 2;
/*
大学本科毕业 15
*/
-- where是选择整个表中age > 30的记录
-- having是选择分组之后count(age) > 2的记录
从性能的角度来说,应该尽量使用 WHERE 条件过滤掉更多的数据,而不是等到分组之后再使用 HAVING 进行过滤;但如果业务需求只能基于汇总之后的结果进行过滤,那就另当别论了。
另外,除了多表join以及窗口函数之外,目前我们基本上已经了解到了一条SQL语句的所有部分了
所以如果把我们之前学的每一个部分都用上,那么就是select .. from .. where .. group by .. having .. order by .. limit .. offset ..,并且它们出现的顺序也是这个顺序,对于单表来说。当然,多表join也差不多。
其实对于单表来说,这些部分已经满足我们大部分的日常需求了。另外关于它们的执行顺序,我们先不涉及的这么深,就说后几个吧。如果它们同时出现,那么执行顺序是where、group by、having、order by、offset、limit,是的,除了limit和offset之外,其它顺序一样。
逻辑就是:先通过where后面的条件从整张表中筛选满足条件的数据,再通过group by分组汇总、having按照汇总之后的结果再进行过滤、然后order by进行排序,最后跳过offset指定的行数,获取limit指定的行数。
小结
GROUP BY 子句可以基于字段或者表达式的值对数据进行分组操作,结合聚合函数可以实现数据的分组统计。另外,HAVING 子句提供了基于汇总结果再次进行过滤的功能。
小心SQL中的空值陷阱
从本节开始我们将会学习进阶内容。进阶内容将会介绍更加复杂的多表查询、子查询、集合运算以及各种高级的数据分析技术,能够让我们真正体会到 SQL 数据处理和分析的强大。
正文
作为进阶的开始,我们先来讨论一下 SQL 中的空值问题,因为空值的特殊性导致我们很容易出现一些错误和问题。
空值与三值逻辑:
SQL 中的空值(NULL)是一个特殊的值,代表了缺失/未知的数据或者不适用的情况。例如,用户在注册时没有提供电子邮箱地址,那么该用户的邮箱就未知;是否怀孕对于男性员工就不适用。
对于大多数的编程语言而言,逻辑运算的结果只有两种情况:真(Ture)或者假(False)。但是对于 SQL 而言,逻辑运算结果存在三种情况:真、假或者未知(Unknown):
对于 SQL 查询中的 WHERE 条件,只有结果为真的数据才会返回,结果为假或者未知都不会返回。
而布尔值和null进行逻辑运算的话,那么结果为null,除非通过短路求值提前判断结果,举个例子
-- and要求两边都为真,所以左边的true决定不了结果,因此会检测null,而两者逻辑运算结果为null
true and null; -- null
-- and左边为假,直接判断结果,所以右边的null不会检测了,所以结果为false
false and null; -- false
-- or要求有一边为真即可,左边为true,所以右边的null不检测了,结果为true
true or null; -- true
-- 左边为false,所以看右边,而右边为null,所以结果是null
false or null; -- false
-- 如果null在左边,不用想了,结果必为null
-- 同理对null取反,结果依旧是null
空值比较与运算:
任何值与 NULL 值进行比较时,结果无法确认是真还是假。以下比较运算的结果都是未知:
NULL = 0
NULL != 0
NULL > 1
NULL = NULL
NULL != NULL
NULL 等于 NULL 的运算结果未知,NULL 不等于 NULL 的运算结果也未知。因此,为了判断某个值是否为空,SQL 提供了 IS NULL 和 IS NOT NULL 谓词
另外,当表达式或者函数涉及 NULL 值时,通常结果也是 NULL 值。例如:
100 + NULL;
UPPER(NULL);
不过也存在一些例外,比如:
select concat('hello', null); -- hello
该查询只有在 MySQL 返回 NULL,CONCAT 函数在 Oracle、SQL Server 以及 PostgreSQL 中将 NULL 当作空字符串处理,返回字符串“hello”。由于不同数据库采取了不同的实现,因此在使用时这些函数时需要小心。
空值的排序:
我们之前介绍了 ORDER BY 排序,并且讨论了空值的排序规则。由于 SQL 标准没有提出明确要求,导致在不同的数据库中存在两种空值排序方式:
- Oracle 和 PostgreSQL,认为空值最大,升序时空值排在最后,降序时空值排在最前;同时支持使用 NULLS FIRST 和 NULLS LAST 指定空值的顺序;
- MySQL 和 SQL Server,认为空值最小,升序时空值排在最前,降序时空值排在最后。
我们可以利用 COALESCE 函数或者 CASE 表达式解决空值的排序问题,上面也给出了 CASE 表达式相关的示例。下面我们介绍一下 SQL 中关于空值处理的函数。
空值函数:
SQL 中定义了两个与空值转换相关的函数:NULLIF 和 COALESCE 。
NULLIF(expr1, expr2) 函数接受 2 个参数,如果第一个参数等于第二个参数,返回 NULL;否则,返回第一个参数的值。
select nullif(1, 2), nullif(3, 3); -- 1 <null>
因为 1 不等于 2,该查询的第一列结果为 1;因为 3 等于 3,第二列结果为 NULL。
NULLIF 函数的一个常见用途是防止除零错误:
select 1 / 0; -- 除零错误
select 1 / nullif(0, 0); -- <null>
第一个查询中被除数为 0,出现除零错误(MySQL 可能不会提示错误);第二个查询使用 NULLIF 函数将被除数 0 转换为 NULL,整个结果为 NULL。
COALESCE:
COALESCE(expr1, expr2, expr3, ...) 函数接受一个参数列表,并且返回第一个非空的参数;如果所有参数都为空,返回 NULL。
我们之前使用过这个函数,一般第一个参数写字段,第二个参数写默认值。如果第一个字段为空,则返回默认值
专有函数:
除了SQL 标准中定义的表达式之外,许多数据库还实现了一些类似的扩展函数:
- Oracle 提供了 NVL(expr1, expr2) 以及 NVL2(expr1, expr2, expr3) 函数;
- MySQL 提供了 IFNULL(expr1, expr2) 以及 IF(expr1, expr2, expr3) 函数;
- SQL Server 提供了 ISNULL(expr1, expr2) 函数。
NVL、IFNULL、ISNULL它们都相当于只有两个参数的COALESCE,但是NVL2和IF比较特殊、类似于编程语言中的三元运算符,对于NVL2来说,如果expr1不为空,那么返回expr2的值,否则返回expr3的值;而对于IF也是一样,如果expr1不为空、并且为真,那么返回expr2,否则返回expr3
分组与聚合函数中的空值:
GROUP BY 子句、DISTINCT 运算符将所有的空值视为相同,因此将它们分为一组。
我们介绍了常见的聚合函数(AVG、SUM、COUNT 等),聚合函数通常会忽略空值。
NOT IN 中的空值:
IN 操作符用于查询位于列表之中的数据,NOT IN 用于查询不位于列表中的数据。
select level from people where level in (1, 2, 3, null);
该查询没有返回任何结果。原因在于 IN 操作符使用等号(=)依次与列表中的数据进行比较,该查询等价于以下形式:
select level from people
where level = 1 or level = 2 or level = 3 or level = null;
任何值与 NULL 比较的结果都是未知;因此没有数据满足该条件,也就没有返回结果。
为了避免各种情况下空值可能带来的问题,可以利用 SQL 提供的空值处理函数将 NULL 值转换为其他数据。
小结
空值(NULL)是 SQL 中容易被忽略的地方,经常会导致一些不可预知的错误结果。需要注意 SQL 在各个子句和函数中对于空值的处理方式。一个比较通用的解决方法就是利用 COALESCE 函数或者 CASE 表达式将这些空值转换成确定的数据。
通过join同时查询多个表中的相关数据
正文
到目前为止,我们的查询都是从单个表中获取数据。下面我们开始探讨一下如何从多个表中获取相关的数据。因为在关系数据库中,通常将不同的信息和它们之间的联系存储到多个表中。比如产品表、用户表、用户订单表、以及关联的订单明细表等。当我们想要查看某个订单时,需要同时从这几个表中查找关于订单的全部信息。
在 SQL 中,我们可以使用多表连接(JOIN)查询获取多个表中的关联数据。
连接语法:
在 SQL 的发展过程中,出现了两种连接查询的语法:
- ANSI SQL/86 标准,使用 FROM 和 WHERE 关键字指定表的连接。
- ANSI SQL/92 标准,使用 JOIN 和 ON 关键字指定表的连接;
当前有两张表,一张叫girl_info、存储了id、name、age,另一张叫girl_score、存储了id、score。
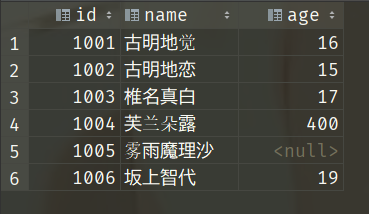
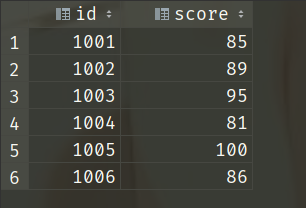
如果我想知道某个女孩考了多少分,需要同时查询girl_info和girl_score两张表,这个问题就可以使用from where解决
select a.name, b.score from girl_info as a, girl_score as b
where a.id = b.id;

其中,FROM 子句中的逗号用于连接两个表;同时在 WHERE 子句中指定了连接的条件是girl_info中的id等于girl_score表中的id。另外,该查询中还通过别名(a 和 b)指定了查询的字段来自哪个表,当然不使用别名、而是使用整个表名也是可以的,只不过比较长。
当然我们这里的id字段是不重复的,如果一方的id字段重复了怎么办?这个问题,我们先放在这里,后面再说。
对于同样的问题,我们看看如何使用 JOIN 和 ON 实现连接查询:
select a.name, b.score from girl_info as a join girl_score as b
on a.id = b.id;
我们看到整体是差不多的,除了把两张表改成用join连接,where改成on。
join表示连接girl_info和girl_score两张表,on则是用于指定连接条件,返回结果和上面是一样的。那么我们使用哪一种呢?
推荐使用 JOIN 和 ON 进行连接查询,它们的语义更清晰,更符合 SQL 的声明性;另外,我们知道where还可以指定整张表的过滤条件,那么当 WHERE 中包含多个查询条件,又用于指定表的连接关系时,会显得比较混乱。
所以推荐使用join和on,至于where,它就用来对整张表进行过滤。
select a.name, b.score
from girl_info as a
join girl_score as b
on a.id = b.id
where a.id > 1003;
/*
芙兰朵露 81
雾雨魔理沙 100
坂上智代 86
*/
-- 表示只对girl_info中id大于1003的进行join
-- 当然,from where也是可以的
-- 只是我们把表的过滤、以及连接关系都写在了where里面
select a.name, b.score
from girl_info as a, girl_score as b
where a.id = b.id and a.id > 1003
/*
芙兰朵露 81
雾雨魔理沙 100
坂上智代 86
*/
另外我们这里on指定的是两张表的id字段相等,但是不一定是id,两张表的其它字段也可以,并且指定的两张表的字段也可以不一样,比如让一张表的id和另一张表的nid相等之类的,on后面也可以指定多个条件,使用and或者or连接。
连接类型:
接下来我们详细介绍一下 SQL 中的各种连接类型。为了介绍连接类型,我们将表的数据改一下,当然结果不变,只是两张表都增加一条数据。
1001 古明地觉 16
1002 古明地恋 15
1003 椎名真白 17
1004 芙兰朵露 400
1005 雾雨魔理沙
1006 坂上智代 19
1007 古明地觉 16
1001 85
1002 89
1003 95
1004 81
1005 100
1006 86
1002 89
girl_info增加一个id为1001的数据,girl_score增加一条id为1002的数据,显然这两条数据是重复的
至于SQL 支持的连接查询,包括内连接、外连接、交叉连接、自然连接以及自连接等。其中,外连接又可以分为左外连接、右外连接以及全外连接。
另外,连接查询中的 ON 子句与 WHERE 子句类似,可以支持各种条件运算符(=、>=、!=、BETWEEN 等)。但最常用的是等值连接(=),我们主要介绍这种条件的连接查询。
内连接:
内连接(Inner Join)返回两个表中满足连接条件的数据;使用关键字 INNER JOIN 表示,也可以简写成 JOIN。内连接的原理如下图所示(基于两个表的 id 进行等值连接):

其中,id = 1 和 id = 3 是两个表中匹配的数据,因此内连接返回了这 2 行记录。
左外连接:
左外连接(Left Outer Join)首先返回左表中所有的数据;对于右表,返回满足连接条件的数据;如果没有相应的数据就返回空值。左外连接使用关键字 LEFT OUTER JOIN 表示,也可以简写成 LEFT JOIN。左外连接的原理如下图所示(基于两个表的 id 进行连接):
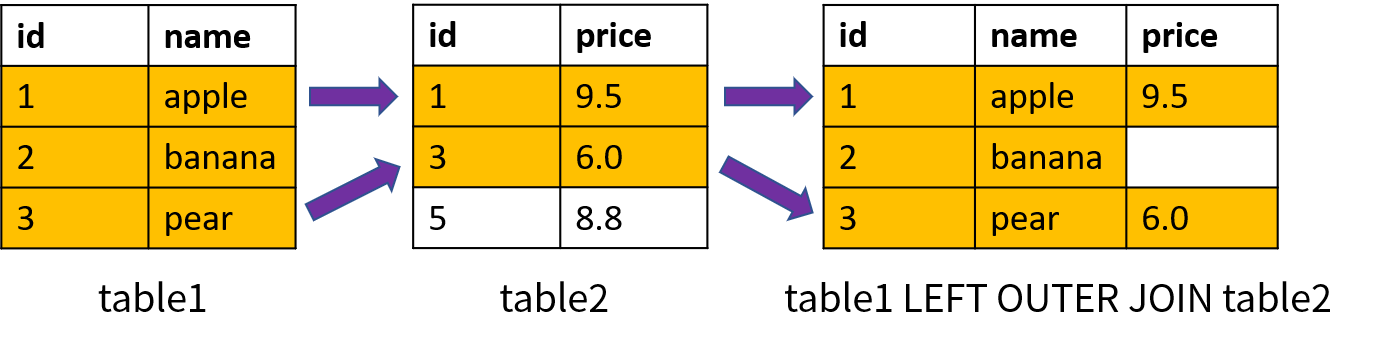
其中,id = 2 的数据在 table1 中存在,在 table2 中不存在;左外连接仍然会返回左表中的该记录,而对于 table2 中的价格(price),返回的是空值。
右外连接:
右外连接(Right Outer Join)首先返回右表中所有的数据;对于左表,返回满足连接条件的数据,如果没有相应的数据就返回空值。右外连接使用关键字 RIGHT OUTER JOIN 表示,也可以简写成 RIGHT JOIN。右外连接的原理如下图所示(基于两个表的 id 进行连接):
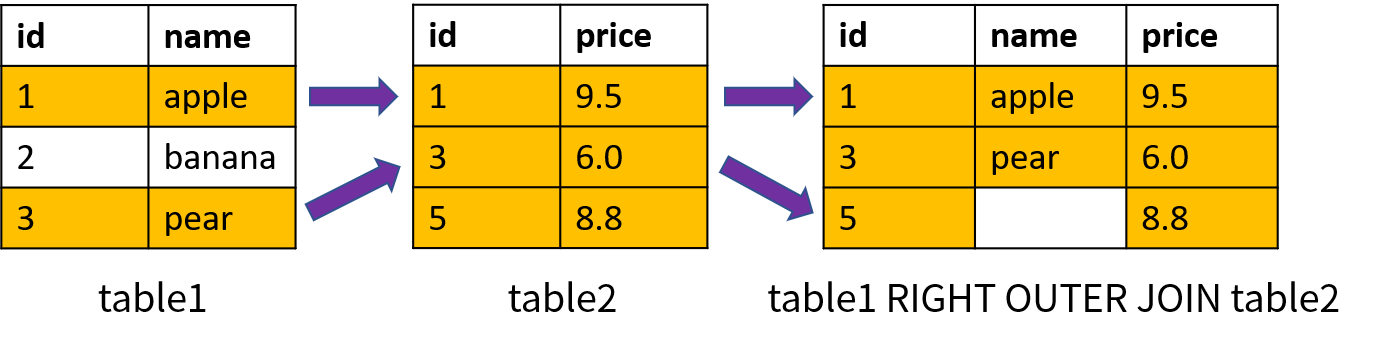
其中,id = 5 的数据在 table2 中存在,在 table1 中不存在;右外连接仍然会返回右表中的该记录,而对于 table1 中的名称(name),返回的是空值。简而言之:
table1 RIGHT JOIN table2等价于table2 LEFT JOIN table1
因此右外连接和左外连接可以相互转换,就我个人而言习惯左连接。如果需要右连接的逻辑,那么我会把两张表的顺序颠倒,而不会把左连接改成右连接,当然这只是我个人习惯。具体怎么做由你自己决定。
全外连接:
全外连接(Full Outer Join)等价于左外连接加上右外连接,同时返回左表和右表中所有的数据;对于两个表中不满足连接条件的数据返回空值。全外连接使用关键字 FULL OUTER JOIN 表示,也可以简写成 FULL JOIN 。全外连接的原理如下图所示(基于两个表的 id 进行连接):
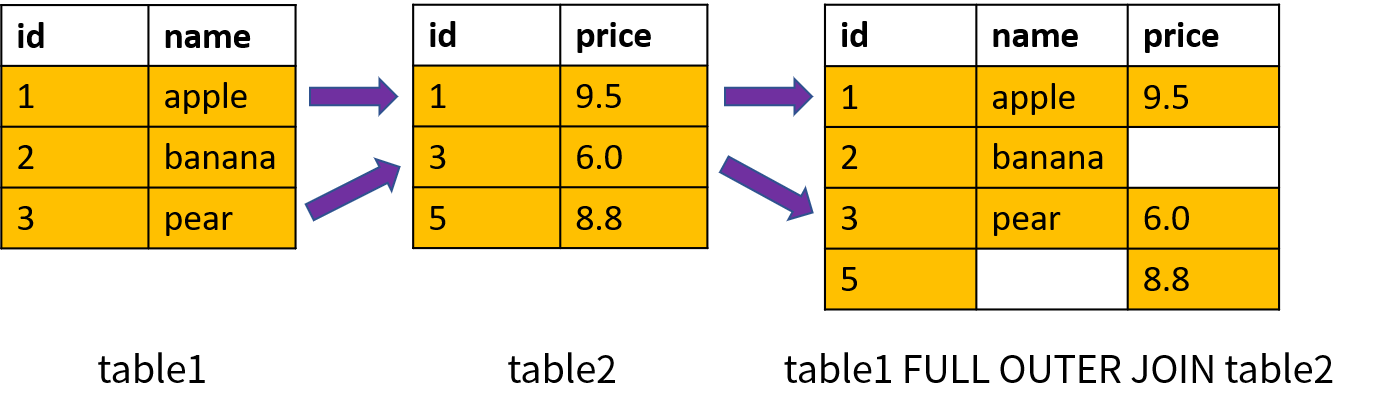
MySQL不支持全外连接。
交叉连接:
交叉连接也称为笛卡尔积(Cartesian Product),使用关键字 CROSS JOIN 表示。两个表的交叉连接相当于一个表的所有行和另一个表的所有行两两组合,结果的数量为两个表的行数相乘。如果第一个表有 1000 行,第二个表有 2000 行,它们的交叉连接将会产生 2000000 行数据。
交叉连接可能会导致查询结果的数量急剧增长,从而引起性能问题;通常应该使用连接条件进行过滤,避免产生交叉连接。
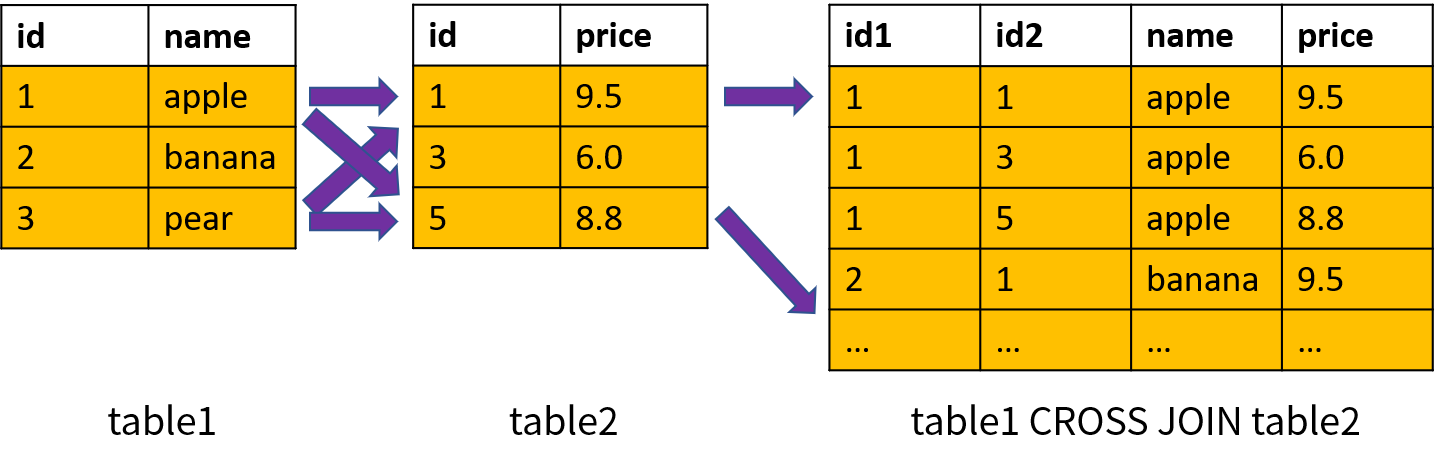
箭头画的比较少,总之就是table1的id=1的记录对应table2全表,然后id=2对应table2全表,依次类推。所以结果总共包含 9 条记录(3 * 3)
交叉连接一般使用较少。
除了上面介绍的几种连接类型,SQL 中还存在一些特殊形式的连接查询。
自然连接:
对于连接查询,如果满足以下条件,可以使用 USING 替代 ON 简化连接条件的输入:
- 连接条件是等值连接;
- 两个表中的连接字段必须名称相同,类型也相同。
比如我们之前的例子,根据两张表的id字段、并且判断是否相等,所以可以改写如下
select a.name, b.score
from girl_info as a
join girl_score as b
using(id)
where a.id > 1003;
得到的结果也是和之前一样
其中,USING 表示使用两个表中的公共字段(id)进行等值连接。查询语句中的公共字段不需要添加表名限定。该语句的结果与上文中的内连接查询示例相同。
SQL Server 不支持 USING 语法。
另外一张表也可以和其自身进行连接
字段重复:
我们目前以id进行连接,但是我们看到了, 我们将记录给改了,id有重复的。那么结果会怎么样呢?
select a.id, a.name, b.score
from girl_info as a
join girl_score as b
using (id);
/*
1001 古明地觉 85
1001 古明地觉 85
1002 古明地恋 89
1003 椎名真白 95
1004 芙兰朵露 81
1005 雾雨魔理沙 100
1006 坂上智代 86
1002 古明地恋 89
*/
我们看到"古明地觉"和"古明地恋"都出现了两次,因为id=1001的记录在girl_info中出现了两次,id=1002的记录在girl_score中出现了两次,那么在进行join的时候,id=1001和id=1002都会出现两次,因为能匹配上。同理,如果girl_score中出现了3个id=1001的记录,那么结果id=1001的记录总数就是2 * 3 = 6。因为也进行了笛卡尔积
所以有时候在做left join之后,会发现结果数据的总数和左表不一致,会好奇,明明是按照左表进行join的呀,为啥结果和左表的总数对不上呢?出现这种情况就是on后面的连接字段中出现了重复。假设按照id进行连接,左表有一个id=3的记录,这时候右表有三个id=3的记录,那么在连接的时候,左表的id=3会和右表的三个id=3的记录进行连接,因此会变成3条记录。因此如果join之后发现结果不对,并且语法也没有写错,那么数量对不上的原因十有八九就是我们目前说的数据重复的问题。
小结
连接查询使得 SQL 能够方便地通过一个查询获取多个表中的关联数据。这节我们讨论了内连接、左/右/全外连接、交叉连接、自然连接以及自连接的概念和作用。推荐使用语义更加清晰、更加通用的 JOIN 和 ON 语法实现连接查询。
子查询:多表查询的另一种方式
正文
上一节我们介绍了如何在 SQL 语句中使用连接查询(JOIN)获取多个表中的关联数据,具体讨论了内连接、左/右/全外连接、交叉连接、自然连接以及自连接的原理和使用方法。
除了连接查询,SQL 还提供了另一种同时查询多个表的方法:子查询(Subquery)。本节我们就来了解一下各种类型的子查询和相关的运算符。
以之前的people表为例,我们要计算年龄大于平均年龄的员工:
-- 一种笨办法就是先计算年龄的平均值,然后拿到这个平均值再去查询
select avg(age) from people; -- 34.2083333333333333
select * from people
where age > 34;
/*
10 01010000033 40 18.8 大学本科毕业 经济师 管理人员 2000-09-05
18 01010000037 35 12.7 大学本科毕业 会计师 管理人员 2006-10-05
19 01010005159 36 10 大学本科毕业 会计师 管理人员 2009-06-05
1 01080000060 49 28.8 大学本科毕业 高级政工师 管理人员 1990-09-05
2 01010004641 35 12.7 大学本科毕业 工程师 管理人员 2006-10-05
3 01010000042 44 26.7 大学本科毕业 经济师 管理人员 1992-10-05
4 01010004180 50 26.6 大学本科毕业 经济师 管理人员 1992-11-05
5 01010004249 38 19.8 大学本科毕业 助理经济师 管理人员 1999-09-05
20 01010005392 51 26.7 大学本科毕业 会计师 管理人员 1992-10-05
23 01010011517 41 1.3 大学本科毕业 管理人员 2018-03-05
*/
我们使用了两个查询来解决这个简单的问题,然而实际应用中的需求往往更加复杂;显然我们需要更加高级的查询功能。
SQL 提供了一种查询方式叫做子查询,可以非常容易地解决这个问题:
select * from people
where age > (select avg(age) from people);
/*
10 01010000033 40 18.8 大学本科毕业 经济师 管理人员 2000-09-05
18 01010000037 35 12.7 大学本科毕业 会计师 管理人员 2006-10-05
19 01010005159 36 10 大学本科毕业 会计师 管理人员 2009-06-05
1 01080000060 49 28.8 大学本科毕业 高级政工师 管理人员 1990-09-05
2 01010004641 35 12.7 大学本科毕业 工程师 管理人员 2006-10-05
3 01010000042 44 26.7 大学本科毕业 经济师 管理人员 1992-10-05
4 01010004180 50 26.6 大学本科毕业 经济师 管理人员 1992-11-05
5 01010004249 38 19.8 大学本科毕业 助理经济师 管理人员 1999-09-05
20 01010005392 51 26.7 大学本科毕业 会计师 管理人员 1992-10-05
23 01010011517 41 1.3 大学本科毕业 管理人员 2018-03-05
*/
简单来说,子查询是指嵌套在其他语句(SELECT、INSERT、UPDATE、DELETE 等)中的 SELECT 语句;子查询也称为内查询(inner query)或者嵌套查询(nested query);子查询必须位于括号之中。
SQL 中的子查询可以分为以下三种类型:
- 标量子查询(Scalar Subquery):返回单个值(一行一列)的子查询。上面的示例就是一个标量子查询。
- 行子查询(Row Subquery):返回单行结果(一行多列)的子查询,标量子查询是行子查询的一个特例。
- 表子查询(Table Subquery):返回一个虚拟表(多行多列)的子查询,行子查询是表子查询的一个特例。
标量子查询:
标量子查询的结果就像一个常量一样,可以用于 SELECT、WHERE、GROUP BY、HAVING 以及 ORDER BY 等子句中。我们计算一下员工的年龄和平均年龄之差
select id, age, (age - (select avg(age) from people))::int
from people
/*
01010009350 30 -4
01010011790 24 -10
01010000033 40 6
01010000980 33 -1
01010005699 30 -4
01010005708 30 -4
01010010579 27 -7
01010010925 24 -10
01010011192 28 -6
01010011791 21 -13
01010000037 35 1
01010005159 36 2
01080000060 49 15
01010004641 35 1
01010000042 44 10
01010004180 50 16
01010004249 38 4
01010004692 33 -1
01010005392 51 17
01010007487 31 -3
01010011253 25 -9
01010011517 41 7
01010000061 33 -1
01010005306 33 -1
*/
估计有人会这么干
select id, age, (age - avg(age))::int
from people
-- 直接用age - avg(age),这样写虽然人很容易理解
-- 但是不好意思,这样写SQL不允许,因为一旦出现了聚合函数
-- 那么select后面的字段要么出现在聚合函数中,要么出现在group by字句中
同理如果寻找年龄第二大的,我们可以这么做
select max(age) from people
where age < (select max(age) from people);
-- 先把最大的age选出来,然后让age小于这个最大值,然后在剩余的记录中再选择最大值
-- 得到的不就是第二大的了吗
-- 但是这要求,最大值不能有重复,假设最大值是50,但是有两个50,这样的话选择就是第三大的了
-- 但是不管怎样,我们肯定不可以这么写
select max(age) from people
where age < max(age);
-- 这样写是错的,先不说max(age)中的age有可能是其它表中的age
-- 即使是一张表的age,也不可以这么写。
-- 因为where是表过滤,where逻辑里面不能包含聚合,如果包含,那么聚合一定是子查询里面的聚合。
行子查询:
行子查询可以当作一个一行多列的临时表使用,顾名思义就是返回一行
我们以之前的girl_info和girl_score为例
-- 选择id出现在girl_score中的girl_info表的记录
select * from girl_info
where id in (select id from girl_score);
/*
1002 古明地恋 15
1003 椎名真白 17
1004 芙兰朵露 400
1005 雾雨魔理沙
1006 坂上智代 19
1001 古明地觉 16
1001 古明地觉 21
*/
-- 当然我们这里是全部记录
表子查询:
当子查询返回的结果包含多行、多列的时候,成为表子查询,表子查询通常用于查询条件或者FROM 子句中。
select * from (select id, score from girl_score where id > 1002) as g;
/*
1003 95
1004 81
1005 100
1006 86
*/
我们这里把子查询返回的结果直接当成一张表来用,当然标量子查询、行子查询也是可以这么做的,跟在from的后面充当一张表的作用。另外,如果是这么做的话,那么必须要起一个别名。
小心陷阱:
对于 WHERE 中的子查询,需要注意返回的数据要进行匹配。比如:
-- 这个语句就是不合法的,因为id=的后面需要跟一个标量,会返回girl_info的id字段中和这个标量相等的值所以对应的记录
-- 而我们返回的是多条数据,所以不匹配
select * from girl_info
where id = (select id from girl_score);
-- 这样也是不合法的,因为还是返回了多条
select *
from girl_info
where id = (select id from girl_score where id != 1002);
-- 合法
select *
from girl_info
where id = (select id from girl_score where id != 1002 and id != 1001 and id != 1003 and id != 1004 and id != 1005);
/*
这样是合法的,因为我们只保留了一条数据,所以返回的是标量
*/
-- 一般这种情况,我们会使用in,in后面需要跟一列
-- 把=改成in是没问题的
select * from girl_info
where id in (select id from girl_score);
-- 但是,下面的语句也是可以的
select *
from girl_info
where id in (select id from girl_score where id != 1002 and id != 1001 and id != 1003 and id != 1004 and id != 1005);
-- 我们说,虽然只返回了一条数据,但是它即可以看成是标量,也可以看成行,只不过这个行只有一列数据
-- 同理,如下是不合法的
select * from girl_info
where id in (select id, age from girl_score);
/*
提示我们,子查询有太多的字段,前面的id是一个字段,但是我们子查询返回了两个
*/
因此在涉及子查询的时候,要小心,可以自己下去多尝试一下。
子查询返回的内容可以在很多地方使用,只要遵循之前的语法规范,比如join是连接表,而子查询返回的内容也可以看成是一张表,那么它就可以跟在join后面,只是当它作为表的时候需要起一个别名。
再比如子查询返回的内容可以看成是一个标量,那么标量能在什么地方用,子查询范返回的结果也可以在什么地方用,前提返回的得是一个标量。同理对于行、表也是一样的,根据返回的内容判断子查询是什么身份,该身份能在什么地方使用,那么子查询返回的结果就可以在什么地方使用。所以子查询能作用的返回很广,也正因为如此,才可以用SQL做更多的事情,如果不支持子查询,可以说,SQL算是"没了两条腿"。也正因为如此,SQL学好了也是很厉害的,因为表之间层层连接、子查询之间层层嵌套的逻辑也不是那么简单的。
子查询和普通查询本质上没什么两样,所以里面也可以嵌套group by、join、limit等逻辑
ALL、ANY/SOME 运算符:
ALL 运算符一般与比较运算符(=、!=、<、<=、>、>=)结合,表示等于、不等于、小于、小于等于、大于或者大于等于子查询结果中的所有值
select * from girl_info
where id >= all(select id from girl_score); -- 1006 坂上智代 19
-- 因为girl_score中id的最大值为1006,girl_info中id的最大值也为1006,所以只有id=1006的记录返回
-- all要求必须和子查询中所有值都满足相应的关系,所以这里是选择girl_info中的id 大于等于 girl_score中的所有id的记录
ANY/SOME 运算符与比较运算符(=、!=、<、<=、>、>=)结合表示等于、不等于、小于、小于等于、大于或者大于等于子查询结果中的某个值即可。
select * from girl_info
where id > any(select id from girl_score);
/*
1002 古明地恋 15
1003 椎名真白 17
1004 芙兰朵露 400
1005 雾雨魔理沙
1006 坂上智代 19
*/
-- girl_score中id最小的值为1001,因为girl_info中,只要id大于1001就满足条件
-- some和any一样,不再演示
EXISTS 操作符:
EXISTS 操作符用于判断子查询结果的存在性。如果子查询存在任何结果,EXISTS 返回真;否则,返回假。
我们将girl_info表修改一下,为了能看到效果
1001 古明地觉 16
1002 古明地恋 15
1003 椎名真白 17
10040 芙兰朵露 400
10050 雾雨魔理沙
1006 坂上智代 19
1001 古明地觉 16
我们将1004和1005后面加上了一个0
girl_score表不变
select *
from girl_info as gi
where exists(select 1
from girl_score as gs
where gi.id = gs.id)
/*
1002 古明地恋 15
1003 椎名真白 17
1006 坂上智代 19
1001 古明地觉 16
1001 古明地觉 21
*/
我们来分析一下逻辑,我们exists只是判断子查询有没有返回内容,至于返回的内容是什么不关心,只要返回了东西即可。
我们先执行外部查询,找到gi.id,然后传递给子查询,一旦在gs中找到个gi.id相等的id,那么就会返回。我们返回的是1,我们说返回的是什么不重要,重要的是有没有返回。而一旦返回了,那么exists函数的执行结果变为true,那么gi的这条记录就是符合的。而10040和10050在gs的id字段中不存在,所以exists函数执行结果为false。所以这个和我们之前的join、也就是内连接之间没有什么区别,只不过我们用exists和子查询重新实现了。
另外我们看到子查询当中也是可以使用外部查询的表的,比如我们这里的子查询使用了外部查询的girl_info表。
NOT EXISTS 执行相反的操作。
现在,我们知道 [NOT] EXISTS 和 [NOT] IN 都可以用于判断子查询返回的结果。但是它们之间存在一个重要的区别:[NOT] EXISTS 只检查存在性,[NOT] IN 需要比较实际的值是否相等。因此,当子查询的结果包含 NULL 值时,EXISTS 仍然返回结果,NOT EXISTS 不返回结果;但是此时 IN 和 NOT IN 都不会返回结果,因为 (X = NULL) 和 NOT (X = NULL) 的结果都是未知。其实说白了,因为exists前面不需要加字段,不会进行比较,只能判断肚子里面的子查询是否返回了东西。。。
我们还可以在子查询中包含其他的子查询,实现嵌套子查询。我们之前说过了
小结
子查询语句为我们提供了在一个查询中访问多个表的另一种方式,很多时候可以实现与连接查询相同的效果。本篇我们讨论了各种形式的子查询,包括相关的操作符和注意事项。
表的集合运算
正文
上一节我们介绍了 SQL 中各种形式的子查询,以及与子查询相关的 IN、ALL、ANY/SOME、EXISTS 运算符。
我们已经学习了两种涉及多个表的查询语句,今天我们来讨论另一种从多个查询中返回组合结果的方法:集合运算。
集合运算:
数据库中的表与集合理论中的集合非常类似,表是由行组成的集合。因此, SQL 支持基于行的各种集合操作:并集运算(UNION)、交集运算(INTERSECT)和差集运算(EXCEPT)。它们都用于将两个查询的结果集合并成一个结果集,但是合并的规则各不相同。
需要注意的是,SQL 集合操作中的两个查询结果需要满足以下条件:
- 结果集中字段的数量和顺序必须相同;
- 结果集中对应字段的类型必须匹配或兼容。
也就是说,对于参与运算的两个查询结果,要求它们的字段结构相同。如果一个查询返回 2 个字段,另一个查询返回 3 个字段,肯定无法合并。如果一个查询返回数字类型的字段,另一个查询返回字符类型的字段,通常也无法合并;不过数据库可能会尝试执行隐式的类型转换。
交集运算:
INTERSECT 操作符用于返回两个查询结果中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据,并且对最终结果进行了去重操作。交集运算的示意图如下:

select *
from girl_info
where id in (1002, 1003, 1004)
intersect
select *
from girl_info
where id in (1002, 1003)
/*
1002 古明地恋 15
1003 椎名真白 17
*/
并集运算:
UNION 操作符用于将两个查询结果相加,返回出现在第一个查询结果或者第二个查询结果中的数据。并集运算的示意图如下:
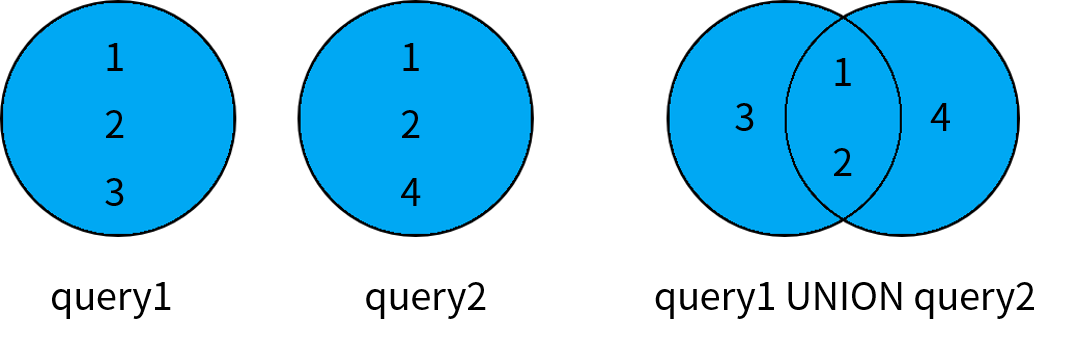
select *
from girl_info
where id in (1002, 1003, 10040)
union
select *
from girl_info
where id in (1002, 1003);
/*
1002 古明地恋 15
10040 芙兰朵露 400
1003 椎名真白 17
*/
但我们发现这个结果是去重了的,还有union等同于union distinct,除此之外还有union all,用于返回所有记录,也就是不去重
select *
from girl_info
where id in (1002, 1003, 10040)
union all
select *
from girl_info
where id in (1002, 1003);
/*
1002 古明地恋 15
1003 椎名真白 17
10040 芙兰朵露 400
1002 古明地恋 15
1003 椎名真白 17
*/
差集运算:
EXCEPT 操作符用于返回出现在第一个查询结果中,但不在第二个查询结果中的记录,并且对最终结果进行了去重操作。差集运算的示意图如下:

select *
from girl_info
where id in (1002, 1003, 10040)
except
select *
from girl_info
where id in (1002, 1003);
/*
10040 芙兰朵露 400
*/
Oracle 使用关键字 MINUS 表示差集运算。MySQL 不支持差集运算。
集合操作中的排序:
如果要对集合操作的结果进行排序,需要将 ORDER BY 子句写在最后;集合操作符之前的查询语句中不能出现排序操作。以下是一个错误的语法示例:
select *
from girl_info
where id in (1002, 1003, 10040)
order by age
union
select *
from girl_info
where id in (1002, 1003);
-- 我们union的时候就写了排序,不单单是因为union之前排序跟union之后是否有序没有任何关系
-- 而是这么写压根就是错误的语法,集合操作的两端不能出现order by关键字
select *
from girl_info
where id in (1002, 1003, 10040)
union
select *
from girl_info
where id in (1002, 1003)
order by age; -- 这么写是正确的
/*
1002 古明地恋 15
1003 椎名真白 17
10040 芙兰朵露 400
*/
-- 此时的order by不是对下面的select查询结果进行排序,而是对整个union之后的结果进行排序
-- 但是在union上面的select语句后面使用order by进行排序的话,则肯定是不符合语法规范的
另外除了 ORDER BY 子句的位置,还有一个常见的问题就是集合操作符的优先级。
集合操作符的优先级:
SQL 提供了 3 种集合操作符:UNION [ALL]、INTERSECT 以及 EXCEPT。我们可以通过多个集合操作符将多个查询的结果进行组合。此时,需要注意它们之间的优先级和执行顺序:
- INTERSECT 的优先级高于 UNION 和 EXCEPT,但是 Oracle 中所有集合操作符的优先级相同;
- 相同的集合操作符按照从左至右的顺序执行;
- 使用括号可以明确指定执行的顺序。
因此很多操作符,包括编程语言也是,尽量还是使用括号进行限定,尽管不加括号,根据优先级,结果也是正确的,但是如果多了的话,还是要加上。一方是为了避免错误,另一方面则是更加的直观。
小结
SQL 中的集合操作符可以将多个查询的结果组合成一个结果。本节讨论了三种集合操作符:UNION [ALL]、INTERSECT 以及 EXCEPT。但是有时候,可以利用连接查询实现与集合操作相同的效果,有兴趣可以自己尝试一下。
with语句把表变成一个变量
正文
上一节我们讨论了如何利用 SQL 集合运算符(UNION [ALL]、INTERSECT 以及 EXCEPT)将多个查询结果合并成一个结果。
接下来我们介绍 SQL 中一个非常强大的功能:通用表表达式(Common Table Expression)。
表即变量:
在编程语言中,通常会定义一些变量和函数(方法);变量可以被重复使用,函数(方法)可以将代码模块化并且提高程序的可读性与可维护性。
与此类似,SQL 中的通用表表达式能够实现查询结果的重复利用,简化复杂的连接查询和子查询;并且可以完成数据的递归处理和层次遍历。
举个例子:
select * from girl_info
where id in (select id from girl_score where id > 1001);
/*
1002 古明地恋 15
1003 椎名真白 17
1006 坂上智代 19
*/
这个是我们之前的例子,我们可以使用with语句,将子查询的结果变成一张临时表
with tmp as (
select id from girl_score where id > 1001
)
select * from girl_info
where id in (select * from tmp);
/*
1002 古明地恋 15
1003 椎名真白 17
1006 坂上智代 19
*/
我们将子查询的逻辑写在了with里面,把子查询返回的内容赋给了变量tmp。此时tmp就相当于是一张表,但是它在数据库中并不真实存在,是一张临时表,但我们是可以当成普通的表来使用的,tmp表的内容就是里面语句返回的结果,那么我们直接对tmp进行select *即可。
专业一点的话就是,with 关键字用于定义通用表表达式(cte);它实际上是定义了一个临时结果集(表),名称为 tmp;as 关键字指定了 tmp 的结构和数据
由于我们这里的示例比较简单,所以没啥区别,但如果子查询一多、或者发生了嵌套,with语句就很有用了。
另外with语句中不要出现分号,因为出现了分号就表示结束了,而我们的with显然和下面的select是分不开了,所以在with xxx as ()的后面不要出现分号。另外,with也可以同时创建多张临时表
-- 多个临时表之间使用逗号分隔,tmp1和tmp2就相当于普通的表
-- 可以进行union、join等等
with tmp1 as (
select id from girl_score where id > 1001
), tmp2 as (
select id from girl_score where id > 1001
)
select * from tmp1
union all
select * from tmp2
;
/*
1002
1003
1004
1005
1006
1002
1002
1003
1004
1005
1006
1002
*/
-- 独立的语句之间若想一次性全部执行,需要使用分隔进行分隔
-- 因为独立的语句之间没有关系,需要使用分号标志结束,才能执行下一行语句
-- 而一旦with下面的语句结束,那么with创建的临时表的生命周期也结束了
-- 也就是说,接下来我们是无法使用tmp1和tmp2的,因为它们已经不存在了
WITH 子句相当于定义了一个变量,变量的值是一个表,所以称为通用表表达式。CTE 和子查询类似,可以用于 SELECT、INSERT、UPDATE 以及 DELETE 语句中。Oracle 中称之为子查询因子(subquery factoring)
因此普通的通用表表达式可以将 SQL 语句进行模块化,便于阅读和理解;而递归形式的通用表表达式可以非常方便地遍历具有层次结构或者树状结构的数据,例如组织结构遍历和航班中转信息查询。
下面来看看递归查询
递归查询:
通用表表达式支持在定义中调用自己,也就是实现编程中的递归调用。接下来我们就介绍一些常用的递归 CTE 案例。
以下是一个简单的递归查询示例,该语句用于生成一个 1 到 10 的数字序列:
-- MySQL 以及 PostgreSQL需要加上recursive才表示递归
-- 而Oracle 以及 SQL Server不需要recursive,直接还是使用with即可
with recursive recursion(n) as (
select 1
union all
select n + 1 from recursion where n < 10
)
select * from recursion;
/*
1
2
3
4
5
6
7
8
9
10
*/
我们这里不再只使用with,而是使用with recursive,这样后面定义的recursion临时表才是可以递归的,我们下面才能from recursion。但是我们注意到,我们定义的时候还加上了一个参数。不加参数的话,里面的内容是从其它地方过来的,但是我们这里是from recursion,也就是说我们定义了一张表recursion,然后这张表的内容还是从recurion里面获取,而我们的数据是n取不同的值进行union得到的,显然这个n得有地方接收,那么接收的位置显然就是参数了。而这个n则是自动生成的,作为参数的它初始值的时候为1。
- 运行初始化语句,生成数字 1;
- 第 1 次运行递归部分,此时 n 等于 1,返回数字 2( n+1 );
- 第 2 次运行递归部分,此时 n 等于 2,返回数字 3( n+1 );
- 第 9 次运行递归部分,此时 n 等于 9,返回数字 10( n+1 );
- 第 10 次运行递归部分,此时 n 等于 10;由于查询不满足条件( WHERE n < 10 ),不返回任何结果,并且递归结束;
- 最后的查询语句返回 t 中的全部数据,也就是一个 1 到 10 的数字序列。
显然,递归 CTE 非常合适用于生成具有某种规律的数字序列,例如斐波那契数列(Fibonacci series)。
斐波那契数列指的是这样一个数列:0、1、1、2、3、5、8、13、...。从数字 0 和 1 开始,每个数字都等于它前面的两个数字之和。如果递归查询中的每一行都基于前面的两个数值求和,就能生成一个斐波那契数列:
with recursive fibonacci (n, fib_n, next_fib_n) as (
select 1, 0, 1
union all
select n + 1, next_fib_n, fib_n + next_fib_n
from fibonacci
where n < 10
)
select *
from fibonacci;

n,fib_n,next_fib_n,三者初始值均为1。
该语句的执行过程如下:
- 初始化第一个斐波那契数列值。字段 fib_n 表示第 n 个斐波那契数列值,第 1 个值为 0;字段 next_fib_n 表示下一个斐波那契数列值,第 2 个数列值为 1;
- 第一次运行递归部分,字段 n 等于 2(1 + 1);字段 fib_n 的值为 1(上一次的 next_fib_n);字段 next_fib_n 的值为 1(0 + 1);
- 继续执行递归部分,字段 n 加上 1;使用上一条记录中的 next_fib_n 作为此次的斐波那契数列值,并且使用 fib_n + next_fib_n 作为下一个斐波那契数列值;
- 不断迭代该过程,当 n 到达 10 之后结束递归过程;
- 最后的查询语句返回所有的数列值。
关于这里的递归,个人觉得不是很重要,了解一下即可。但是有时候递归却有很重要,因为使用递归最大的特点就是会用的话,那么问题就变得非常简单,几行就写完了。但是换来的代价就是非常的不好理解,因此关于递归可以自己平时多练习,至于工作中是否使用递归就看你自己的了。只是希望不要为了耍帅为用递归,普通办法能够高效率解决的话,那么还是使用普通办法。
递归限制:
通常来说,递归 CTE 的定义中需要包含一个终止递归的条件;否则的话,递归将会进入死循环。递归终止的条件可以是遍历完表中的所有数据,不再返回结果;或者是一个 WHERE 终止条件。
WITH RECURSIVE t (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM t
)
SELECT n FROM t;
我们上面没有终止条件,因为没有使用where对n进行限定,那么执行该语句时,Oracle 能够检测到查询语句中的问题并提示错误;MySQL 默认递归 1000 次后提示错误;SQL Server 默认递归 100 次后提示错误;PostgreSQL 没有进行控制,而是进入死循环。
小结
SQL 中的通用表表达式(CTE)相当于定义了一个表的变量,能够将复杂的查询结构化,并且实现结果集的重复利用。CTE 比子查询更易阅读和理解,递归 CTE 则提供了遍历层次数据和树状结构图的编程功能。
数据的多维度交叉分析
正文
我们之前学习了基础的数据分组汇总操作,现在,让我们讨论一些更高级的分组统计分析功能,也就是 GROUP BY 子句的扩展选项。
销售示例数据:
本节我们使用新的数据集,表名叫做sales_data,它包含了 2019 年 1 月 1 日到 2019 年 6 月 30 日三种产品在三个渠道的销售情况。以下是该表中的部分数据:
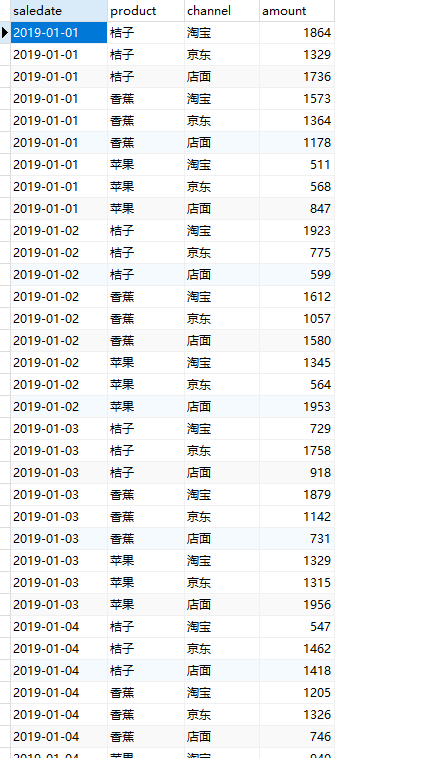
saledate表示销售日期,product表示产品,channel表示平台,amount表示销售金额。
现在就让我们来看看 GROUP BY 支持哪些高级分组选项。
层次化的统计:
这个就比较简单了,就是我们之前使用的group by
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY product, channel;

这是一个简单的分组汇总操作,我们得到了每种产品在每个渠道的销售金额。现在我们来思考一个问题:如何知道每种产品在所有渠道的销售金额合计,以及全部产品的销售金额总计呢?有人肯定觉得,直接按照product进行分组、sum一下不就行了,但这需要单独写一个SQL,我们需要连同上面的内容一起输出,这个时候就需要ROLLUP了。
在 SQL 中可以使用 GROUP BY 子句的扩展选项:ROLLUP。ROLLUP 可以生成按照层级进行汇总的结果,类似于财务报表中的小计、合计和总计。
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup(product, channel);
-- 我们不再group by product, channel,而是GROUP BY rollup(product, channel)
-- 注意:如果是mysql,那么要这样写,group by product, channel with rollup

我们注意到,多了四条数据,上面三条,就是按照product、channel汇总之后,再单独按product汇总,因此,此时就给对应的channel赋值为null了。同理最后一条数据是全量汇总,不需要指定product和channel,所以显示为product和channel都显示为null。我们看到这就相当于按照product单独聚合然后再自动拼接在上面了,排好序,并且自动将channel赋值为null,同理最后一条数据也是如此。当然我们也可以写多个语句,然后通过union也能实现上面的效果,有兴趣可以自己试一下。但是数据库提供了rollup这个非常方便的功能,我们就要利用好它。
所以该查询的结果中多出了 4 条记录,分别表示三种产品在所有渠道的销售金额合计(渠道显示为 NULL)以及全部产品的销售金额总计(产品和渠道都显示为 NULL)。
GROUP BY 子句加上 ROLLUP 选项时,首先按照分组字段进行分组汇总;然后从右至左依次去掉一个分组字段再进行分组汇总,被去掉的字段显示为空;最后,将所有的数据进行一次汇总,所有的分组字段都显示为空。
在上面的示例中,显示为空的字段作用不太明显。我们可以利用空值函数 COALESCE 将结果显示为更易理解的形式:
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup(product, channel);

除了 ROLLUP 之外,GROUP BY 还支持 CUBE 选项
多维度的交叉统计:
CUBE 代表立方体,它用于对分组字段进行各种可能的组合,能够产生多维度的交叉统计结果。CUBE 通常用于数据仓库中的交叉报表分析。
示例数据集 sales_data 中包含了产品、日期和渠道 3 个维度,对应的数据立方体结构如下图所示:

其中,每个个小的方块表示一个产品在特定日期、特定渠道下的销售金额。
以下语句利用 CUBE 选项获得每种产品在每个渠道的销售金额小计,每种产品在所有渠道的销售金额合计,每个渠道全部产品的销售金额合计,以及全部产品在所有渠道的销售金额总计:
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY cube(product, channel);
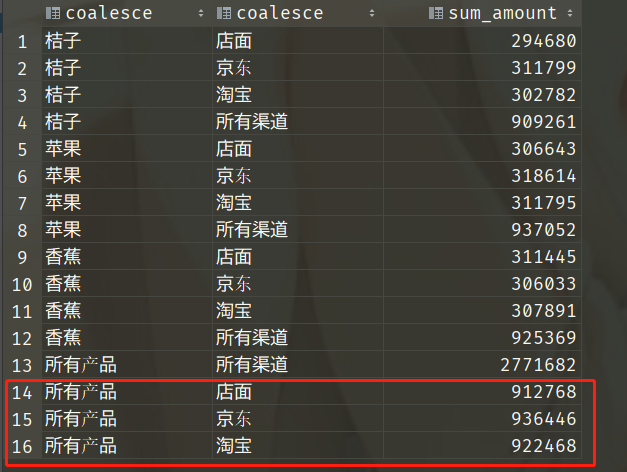
从以上结果可以看出,CUBE 返回了更多的分组数据,其中不仅也包含了 ROLLUP 汇总的结果,还包含了相当于按照channel进行聚合的记录。因此随着分组字段的增加,CUBE 产生的组合将会呈指数级增长。
MySQL 目前还不支持 CUBE 选项。
ROLLUP 和 CUBE 都是按照预定义好的组合方式进行分组;GROUP BY 还支持一种更灵活的统计方式:GROUPING SETS。
自定义分组粒度:
GROUPING SETS 选项可以用于指定自定义的分组集,也就是分组字段的组合方式。实际上,ROLLUP 和 CUBE 都属于特定的分组集。比如:
GROUP BY product, channel;
-- 等价于
GROUP BY GROUPING SETS ((product, channel));
(product, channel) 定义了一个分组集,也就是按照产品和渠道的组合进行分组。注意,括号内的所有字段作为一个分组集,外面再加上一个括号包含所有的分组集。
GROUP BY ROLLUP (product, channel);
-- 相当于
GROUP BY GROUPING SETS ((product, channel),
(product),
()
);
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;最后的括号( () )表示将所有的数据作为整体进行统计。
上文中的 CUBE 选项示例:
GROUP BY CUBE (product, channel);
-- 相当于
GROUP BY GROUPING SETS ((product, channel),
(product),
(channel),
()
);
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;接着按照不同的渠道进行分组;最后将所有的数据作为一个整体。
GROUPING SETS 选项的优势在于可以指定任意的分组方式。以下示例返回不同产品的销售金额合计以及不同渠道的销售金额合计:
-- 分别按照product和channel汇总
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY grouping sets ((product), (channel));
/*
桔子 null 909261
苹果 null 937052
香蕉 null 925369
null 店面 912768
null 京东 936446
null 淘宝 922468
*/
-- 我们使用union也是可以实现的
select product, null as channel, sum(amount) as sum_amount
from sales_data group by product
union
select null as product, channel, sum(amount) as sum_amount
from sales_data group by channel
order by product, channel nulls last
/*
桔子 null 909261
苹果 null 937052
香蕉 null 925369
null 店面 912768
null 京东 936446
null 淘宝 922468
*/
可以看到我们把(product) 和 (channel) 分别指定了一个分组集。通过 GROUPING SETS 选项可以实现任意粒度(维度)的组合分析。
MySQL 目前还不支持 GROUPING SETS 选项。
GROUPING 函数:
在进行分组统计时,如果源数据中存在 NULL 值,查询的结果会产生一些歧义。我们先插入一条模拟数据,它的渠道为空:
-- 只有 Oracle 需要执行以下 alter 语句
-- alter session set nls_date_format = 'YYYY-MM-DD';
INSERT INTO sales_data VALUES ('2019-01-01','桔子', NULL, 1000.00);
再次运行之前的 ROLLUP 示例
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);

我们说尽管null值无法判断是否相等,但是在分组的时候所有为null都会分到同一组,不过我们这里只插入了一条channel为空的记录,无所谓啦。注意看此时的数据:黄色框框的部分出现了两个channel为null的,显然从数据我们能看出来,sum_amount为1000的,是我们在聚合的时候产生的,它并不是“桔子”在所有渠道的销售金额合计,第五行才是“桔子”在所有渠道的销售金额合计(910261)。问题的原因在于 GROUP BY 将空值作为了一个分组,于是有两个null,可能有人觉得使用COALESCE 函数转化一下不就行了,是这样吗?我们来试一下。
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);
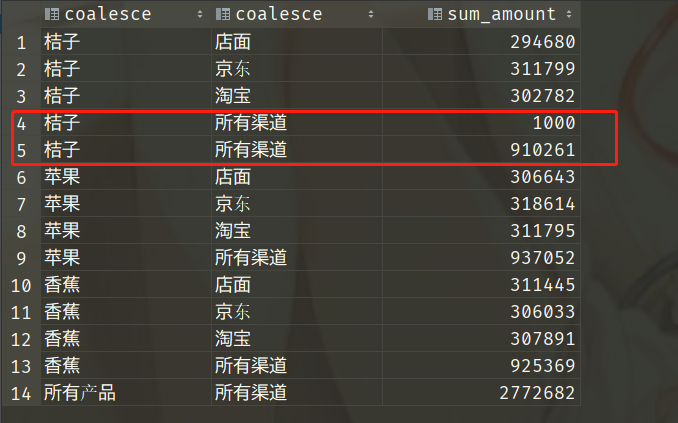
一样的结果,汇总之后channel是为null的,但是我们的select后面是coalesce(channel, '所有渠道'),所以结果也就变成了'所有渠道',因为我们的(COALESCE 函数)无法区分是由汇总产生的 NULL 值还是源数据中存在的 NULL 值。
为了解决这个问题,SQL 提供了一个函数:GROUPING。以下语句演示了 GROUPING 函数的作用:
SELECT product,
grouping(product), -- 多加了一个grouping(product)
channel,
grouping(channel), -- 多加了一个grouping(channel)
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);

其中,GROUPING 函数返回 0 或者 1。如果当前数据是某个字段上的汇总数据,该函数返回 1;否则返回 0。例如,第 4 行数据虽然渠道显示为 NULL,但不是所有渠道的汇总,所以 GROUPING(channel) 的结果为 0;第 5 行数据的渠道同样显示为 NULL,它是“桔子”在所有渠道的销售金额汇总,所以 GROUPING(channel) 的结果为 1。
因此,我们可以利用 GROUPING 函数显示明确的信息:
SELECT case grouping(product) when 1 then '所有商品' else product end as product,
case grouping(channel) when 1 then '所有渠道' else channel end as channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);
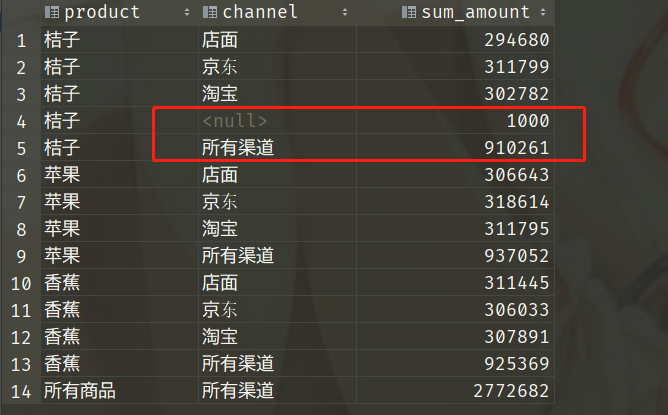
如此一来就变成我们想要的结果了。
通过查询的结果可以清楚地区分出空值和汇总数据。
当然,如果源数据中不存在 NULL 值或者进行了预处理,也可以直接使用 COALESCE 函数进行显示。
小结
在 Excel 中有一个分析功能叫做数据透视表,利用 GROUP BY 的 ROLLUP、CUBE 以及 GROUPING SETS 选项可以非常容易地实现类似的效果,并且使用更加灵活。这些都是在线分析处理系统(OLAP)中的常用技术,能够提供多维度的层次统计和交叉分析功能。
使用窗口函数进行移动分析和累计求和
正文
上一节我们学习了利用 GROUP BY 子句的扩展选项(ROLLUP、CUBE 以及 GROUPING SETS)实现数据的层次统计、交叉汇总以及自定义维度分析等高级功能。
不过,产品和业务对于复杂报表的需求并不仅仅止步于此。例如,如何分析员工在部门内的薪酬排名、计算产品每个月的累计销量以及与去年同期相比的增长率等。这些分析功能通过分组汇总操作通常很难或者无法实现,因此我们需要了解更加强大的 SQL 窗口函数(Window Function)。
窗口函数定义:
与聚合函数类似,窗口函数也是针对一组数据进行分析计算;但窗口函数不是将一组数据汇总成单个结果,而是为每一行数据返回一个分析结果。下图演示了两者之间的区别:
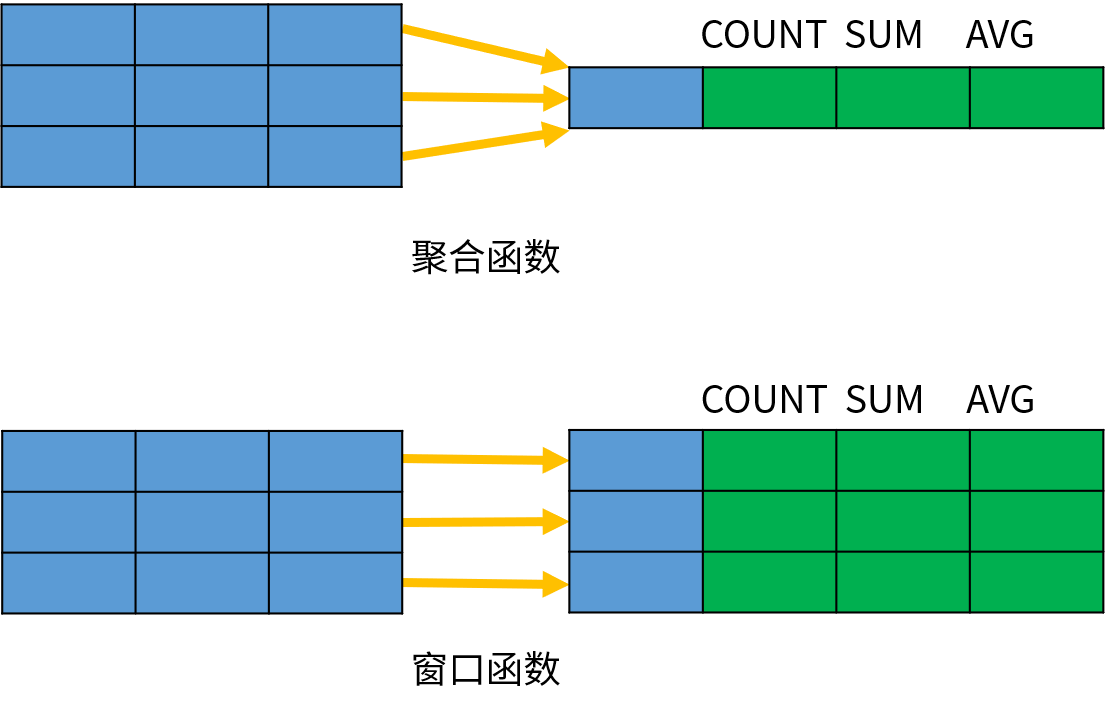
聚合函数会将同一个组内的多条数据汇总成一条数据,但是窗口函数保留了所有的原始数据。
窗口函数也被称为联机分析处理(OLAP)函数,或者分析函数(Analytic Function)。
我们以 SUM 函数为例,比较这两种函数的差异。如果例子不理解的话,继续往下看。
select sum(amount) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
11970
*/
select saledate, product, sum(amount) over() as sum_amount
from sales_data
where saledate = '2019-01-01'
/*
2019-01-01 桔子 11970
2019-01-01 桔子 11970
2019-01-01 桔子 11970
2019-01-01 香蕉 11970
2019-01-01 香蕉 11970
2019-01-01 香蕉 11970
2019-01-01 苹果 11970
2019-01-01 苹果 11970
2019-01-01 苹果 11970
2019-01-01 桔子 11970
*/
OVER 关键字表明 SUM 是一个窗口函数;括号内为空表示将所有数据作为整体进行分析。
查询结果返回了所有的记录,并且 SUM 聚合函数为每条记录都返回了相同的汇总结果。
从上面的示例可以看出,窗口函数与其他函数的不同之处在于它包含了一个 OVER 子句;OVER 子句用于定义一个分析数据的窗口。完整的窗口函数定义如下:
window_function ( expression ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
其中,window_function 是窗口函数的名称;expression 是窗口函数操作的对象,可以是字段或者表达式;OVER 子句包含三个部分:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
接下来我们分别介绍这些选项的作用。
分区(PARTITION BY):
OVER 子句中的 PARTITION BY 选项用于定义分区,作用类似于 GROUP BY 分组;如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析。
select saledate, product, sum(amount) over(partition by product) as sum_amount
from sales_data
where saledate = '2019-01-01'

我们看到窗口函数就是针对partition by后面字段进行分区,相同的分为一个区,然后对每个分区里面的值进行计算。我们按照product进行分区,那么所有值为"桔子"的分为一区,那么它的sum_amount就是所有值为"桔子"的amount之和,同理苹果、香蕉也是如此。
我们看到窗口函数,虽然也用到了聚合,但是它并不需要group by,因为字段的数量和原来保持一致。只是针对partition by后面的字段进行分区,然后对每一个区使用聚合得到一个值,然后给该分区的所有记录都添上这么一个值。
现在再回来看开始的例子,saledate='2019-01-01'的记录有10条,那么select sum(amount) from sale_data saledate='2019-01-01'得到的数据只有一条,也就是所有的amount之和。而select sum(amount) over() from sale_data saledate='2019-01-01',我们说由于over()里面是空的,所以相当于整体只有一个分区,这个分区就是整个筛选出来的数据集,那么还是计算所有的amount之和,但是返回的是10条,和原来的数据行数保持一致。
并且窗口函数不需要group by,前面可以直接加上指定的字段,还是那句话,它不改变数据集的大小,而是在聚合之后给原来的每一条记录都添上这么一个值。但是普通的聚合就不行了,如果select指定了其它字段,那么这些字段必须出现在聚合函数、或者group by字句中,并且计算完之后数据行数会减少(除非group by后面的字段都不重复,但如果不重复的话,我们一般也不会用它来group by)
partition by后面可以指定多个字段,比如:
select saledate, product, amount, sum(amount) over(partition by saledate, product) as sum_amount
from sales_data
where saledate < '2019-01-04'
/*
2019-01-01 桔子 1864.00 5929
2019-01-01 桔子 1329.00 5929
2019-01-01 桔子 1736.00 5929
2019-01-01 桔子 1000.00 5929
2019-01-01 苹果 568.00 1926
2019-01-01 苹果 847.00 1926
2019-01-01 苹果 511.00 1926
2019-01-01 香蕉 1364.00 4115
2019-01-01 香蕉 1178.00 4115
2019-01-01 香蕉 1573.00 4115
2019-01-02 桔子 775.00 3297
2019-01-02 桔子 599.00 3297
2019-01-02 桔子 1923.00 3297
2019-01-02 苹果 564.00 3862
2019-01-02 苹果 1953.00 3862
2019-01-02 苹果 1345.00 3862
2019-01-02 香蕉 1057.00 4249
2019-01-02 香蕉 1580.00 4249
2019-01-02 香蕉 1612.00 4249
2019-01-03 桔子 1758.00 3405
2019-01-03 桔子 918.00 3405
2019-01-03 桔子 729.00 3405
2019-01-03 苹果 1329.00 4600
2019-01-03 苹果 1315.00 4600
2019-01-03 苹果 1956.00 4600
2019-01-03 香蕉 1142.00 3752
2019-01-03 香蕉 731.00 3752
2019-01-03 香蕉 1879.00 3752
*/
我们看到,partition by后面指定了saledate、product,那么相当于按照sale、product进行分区,相同的分为一区。然后对每一个分区里面的amount进行求和,然后给该分区里面的所有的行都添上求和之后的值。所以2019-01-01 桔子对应的sum_amount是5929,因为所有2019-01-01 桔子 对应的amount加起来是5929,然后给这个分区对应的每条记录都添上5929这个值。同理对于其它的记录也是同样的道理。
在窗口函数中指定 PARTITION BY 选项之后,不需要 GROUP BY 子句也能获得分组统计信息。如果不指定 PARTITION BY 选项,所有的数据作为一个整体进行分析。
排序(ORDER BY):
OVER 子句中的 ORDER BY 选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似;排序选项通常用于数据的排名分析。
partition by ... order by ... [asc|desc]
排序也是可以指定多个字段进行排序的,多个字段逗号分隔,order by要在partition by的后面。并且排序也是针对自身所在的分区来的,每个分区的内部进行排序。
对于 Oracle 和 PostgreSQL,OVER 子句中的 ORDER BY 选项也可以使用 NULLS FIRST 指定空值排在最前,或者 NULLS LAST 指定空值排在最后。这一点与 ORDER BY 子句相同。
我们现在知道了,partition by是根据指定字段分区,然后对每个分区使用前面的函数忘记说了,over()前面必须是函数,比如:sum(amount) over(),不可以是amount over()。然后order by是根据指定字段,对分区里面的记录进行排序。可以只指定partition by不指定order by,如果不考虑窗口内部记录的顺序的话。也可以只指定order by,不指定partition by。我们先来看看只指定order by,不指定partition by的话,会是什么结果。
select amount, sum(amount) over(order by amount) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
511.00 511
568.00 1079
847.00 1926
1000.00 2926
1178.00 4104
1329.00 5433
1364.00 6797
1573.00 8370
1736.00 10106
1864.00 11970
*/
select amount, sum(amount) over(order by amount desc) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
1864.00 1864
1736.00 3600
1573.00 5173
1364.00 6537
1329.00 7866
1178.00 9044
1000.00 10044
847.00 10891
568.00 11459
511.00 11970
*/
我们看到实现了累加的效果,我们知道指定partition by,那么根据哪些字段分区是由partition by后面的字段决定的。但如果在不指定partition by、只指定order by的情况下,那么就只有一个分区,这个分区就是全部记录,然后会根据order by后面的字段对全部记录进行排序,然后再进行累和(假设是对于sum而言,其它的函数也是类似的),所以第2行的值等于原来第1行的值加上原来第2行的值(后面举例说明)。
当然我们这里说的先干什么、然后干什么,只是为了方便理解,但是SQL在执行的时候,不一定是我们说的这样。但是逻辑是可以这样来理解的,按照这个逻辑来分析是可以完全吻合返回的结果的。
回到上面的例子,我们说是先排序,然后逐行累加。这是因为我们这里的amount没有重复的,所以是逐行累加。第1行:1864,第二行:1864+1736=3600,第3行:1864+1736+1573=5173
如果我们是根据product进行order by的话,product有重复的
select product, amount, sum(amount) over(order by product) as sum_amount
from sales_data where saledate = '2019-01-01';
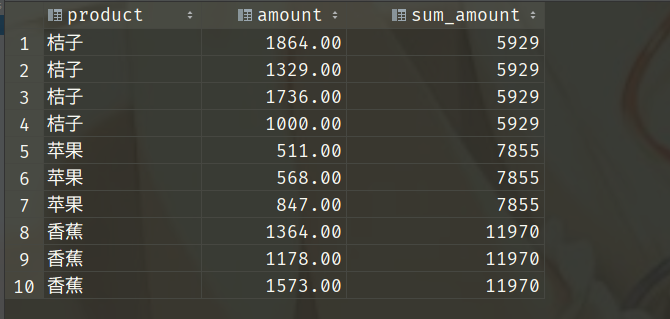
我们说order by是先排序,这是按照product排序,显然是按照其拼音首字符的ascii码进行排序。当然排序不重要,重点是后面的累加。我们看到并没有逐行累加,而是把product相同的先分别加在一起,得到的结果是:桔子:5929 苹果: 1926 香蕉:4115,然后再对整体进行累加,所以苹果的值应该是:5929+1926=7855,同理香蕉的值:5929+1926+4115=11970。
所以这个累加并不是针对每一行来的,而是先把product相同的amount都加在一起,然后对加在一起的值进行累加。并且累加之后,再将累加的的结果添加到对应product的每一条记录上。而我们上面第一个例子之所以是逐行累加,是因为我们order by指定的是amount,而amount都不重复。
但是问题来了,单独指定partition by和单独指定order by我们已经知道了,但如果partition by和order by同时指定的话会怎么样呢?
select product, amount, sum(amount) over (partition by product order by amount desc) as sum_amount
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1864
桔子 1736.00 3600
桔子 1329.00 4929
桔子 1000.00 5929
苹果 847.00 847
苹果 568.00 1415
苹果 511.00 1926
香蕉 1573.00 1573
香蕉 1364.00 2937
香蕉 1178.00 4115
*/
我们看到是按照product分区,按照amount排序,但此时依旧出现了累和(假设前面的聚合是sum),但显然它是在分区内部进行累和。我们知道如果不指定partition by的话,那么order by amount会对整个数据集进行排序,然后进行累和。但是现在指定partition by了,那么会先根据partition by进行分区,然后order by的逻辑还是跟之前一样,可以认为是在各自的分区内部分别执行了order by。我们再来看个栗子
select product, saledate, amount, sum(amount) over (partition by product order by saledate) as sum_amount
from sales_data
where saledate < '2019-01-04';
/*
桔子 2019-01-01 1864.00 5929
桔子 2019-01-01 1329.00 5929
桔子 2019-01-01 1736.00 5929
桔子 2019-01-01 1000.00 5929
桔子 2019-01-02 775.00 9226
桔子 2019-01-02 1923.00 9226
桔子 2019-01-02 599.00 9226
桔子 2019-01-03 729.00 12631
桔子 2019-01-03 918.00 12631
桔子 2019-01-03 1758.00 12631
苹果 2019-01-01 568.00 1926
苹果 2019-01-01 511.00 1926
苹果 2019-01-01 847.00 1926
苹果 2019-01-02 1345.00 5788
苹果 2019-01-02 564.00 5788
苹果 2019-01-02 1953.00 5788
苹果 2019-01-03 1315.00 10388
苹果 2019-01-03 1329.00 10388
苹果 2019-01-03 1956.00 10388
香蕉 2019-01-01 1573.00 4115
香蕉 2019-01-01 1178.00 4115
香蕉 2019-01-01 1364.00 4115
香蕉 2019-01-02 1580.00 8364
香蕉 2019-01-02 1057.00 8364
香蕉 2019-01-02 1612.00 8364
香蕉 2019-01-03 1142.00 12116
香蕉 2019-01-03 731.00 12116
香蕉 2019-01-03 1879.00 12116
*/
以桔子为例,这个结果像不像我们单独使用order by的时候所得到的结果呢?我们是按照product分区的,相同的product归为一个区。然后在各自的分区里面,先通过order by saledate进行排序,再把saledate相同的amount先进行求和,以桔子为例:2019-01-01的amount总和是5929,2019-01-02的amount总和是3297,然后累加,2019-01-02的amount总和就是5929+3297=9226,同理3号、4号的逻辑也是如此。所以我们看到order by的逻辑不变,如果没有partition by,那么它的作用范围就是整个数据集、因为此时整体是一个分区;如果有partition by,那么在分区之后,order by的作用范围就是一个个的分区,就把每一个分区想象成独立的数据集就行,在各自的分区内部执行order by的逻辑。同理下面的苹果和香蕉也是一样的逻辑。
可能我说的有点绕,但是操作一下还是很好理解的。
指定窗口大小:
指定窗口大小稍微有点复杂,可能需要花点时间来理解,与其说复杂,倒不如说东西有点多。可能开始不理解,但是坚持看完,你肯定会明白的,不要看到一半就放弃了,一定要看完,因为通过后面的例子、以及解释会对开始的内容进行补充和呼应。
OVER 子句中的 frame_clause 选项用于指定一个移动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,函数不再基于分区进行计算,而是基于窗口内的数据进行计算。窗口选项可以实现许多复杂的计算。例如,累计到当前日期为止的销量总计,每个月份及其前后各一月(3 个月)的平均销量等。
窗口大小的具体选项如下:
ROWS frame_start
-- 或者
ROWS BETWEEN frame_start AND frame_end
其中,ROWS 表示以行为单位计算窗口的偏移量。frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
- UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值;
- N PRECEDING,窗口从当前行之前的第 N 行开始;
- CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
- CURRENT ROW,窗口到当前行结束,默认值;
- N FOLLOWING,窗口到当前行之后的第 N 行结束。
- UNBOUNDED FOLLOWING,窗口到分区的最后一行结束;
下图演示了这些窗口选项的作用:
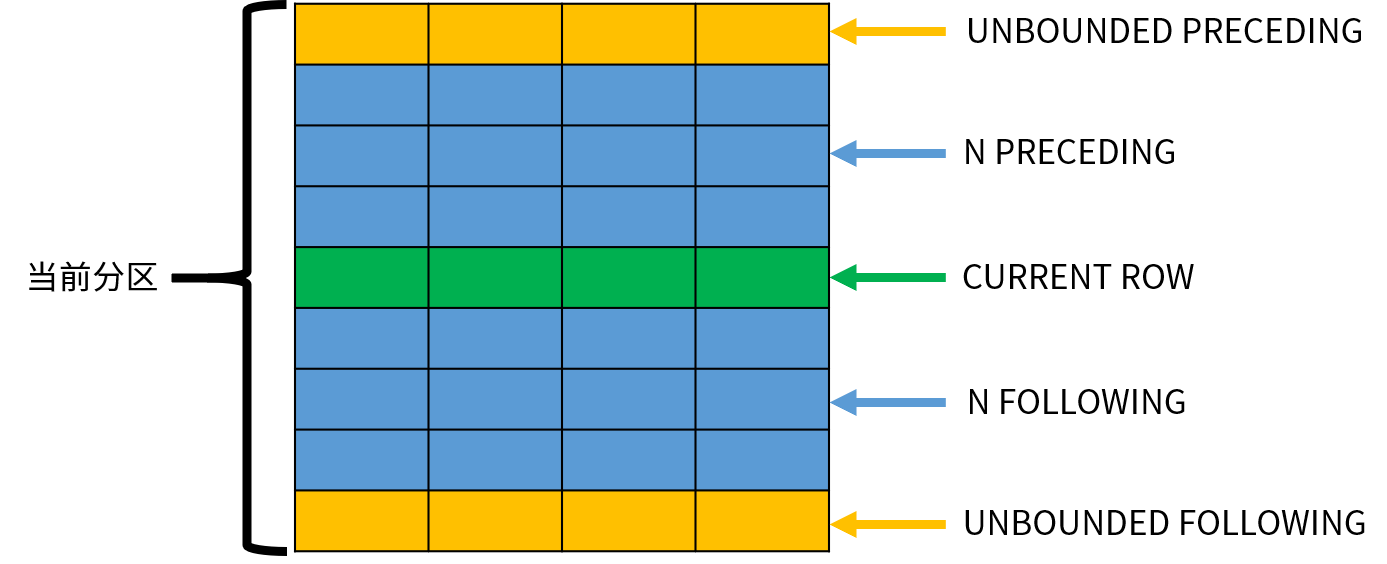
窗口函数依次处理每一行数据,CURRENT ROW 表示当前正在处理的数据;其他的行可以使用相对当前行的位置表示。需要注意的是,窗口的大小不会超出分区的范围。
窗口函数的选项比较复杂,我们通过一些常见的窗口函数示例来理解它们的作用。常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
许多聚合函数也可以作为窗口函数使用,包括 AVG、SUM、COUNT、MAX 以及 MIN 等。
-- 本来order by amount是按对每个分区内部的记录进行累加的,当然这里的累加并不是逐行累加,是我们上面说的那样
-- 只是为了方便,我们就直接说累加了,或者累和也是一样,因为我们这里是以sum函数为例子
-- 但是我们指定了窗口大小,那么怎么加就由我们指定的窗口大小来决定了,而不是整个分区
select product, amount,
sum(amount) over(partition by product order by amount rows unbounded preceding) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000
桔子 1329.00 2329
桔子 1736.00 4065
桔子 1864.00 5929
苹果 511.00 511
苹果 568.00 1079
苹果 847.00 1926
香蕉 1178.00 1178
香蕉 1364.00 2542
香蕉 1573.00 4115
*/
OVER 子句中的 PARTITION BY 选项表示按照product进行分区,ORDER BY 选项表示按照amount进行排序。窗口子句 ROWS UNBOUNDED PRECEDING 指定窗口从分区的第一行开始,默认到当前行结束;也就是分区的第一行从上往下一直加到当前行结束,因为前面的聚合是sum。
同理,N PRECEDING 则是从当前行的上N行开始、加到当前行结束,如果是2 PRECEDING ,那么第5行就是,第3行+第4行、再加上当前的第5行
select product, amount,
sum(amount) over(partition by product order by amount rows 2 preceding) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000 -- 其本身
桔子 1329.00 2329 -- 上面只有1行,没有两行,那么有多少加多少 1000+1329
桔子 1736.00 4065
桔子 1864.00 4929 -- 上两行加上当前行,1329 + 1736 + 1864
苹果 511.00 511
苹果 568.00 1079
苹果 847.00 1926
香蕉 1178.00 1178
香蕉 1364.00 2542
香蕉 1573.00 4115
*/
最后再来看看CURRENT ROW,它是最简单的了
select product, amount,
sum(amount) over(partition by product order by amount rows current row ) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000
桔子 1329.00 1329
桔子 1736.00 1736
桔子 1864.00 1864
苹果 511.00 511
苹果 568.00 568
苹果 847.00 847
香蕉 1178.00 1178
香蕉 1364.00 1364
香蕉 1573.00 1573
*/
我们看到没有变化,因为这表示从当前行开始、到当前行,所以就是其本身。所以它单独使用没有太大意义,而是和结束位置一起使用。
select product, amount,
sum(amount) over(
-- 从当前行加到窗口的结尾
partition by product order by amount rows between current row and unbounded following
) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 5929 -- 1000 + 1329 + 1736 + 1864
桔子 1329.00 4929 -- 1329 + 1726 + 1864
桔子 1736.00 3600 -- 1726 + 1864
桔子 1864.00 1864 -- 1864
苹果 511.00 1926 -- 其它依次类推
苹果 568.00 1415
苹果 847.00 847
香蕉 1178.00 4115
香蕉 1364.00 2937
香蕉 1573.00 1573
*/
我们指定其它的范围
select product, amount,
-- 计算平均值
avg(amount) over(
-- 表示从当前行的上1行开始,到当前行的下1行结束。当然我们这里数据集比较少,具体指定为多少由你自己决定
-- 然后计算这三行的平均值
partition by product order by amount rows between 1 preceding and 1 following
) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1164.5 -- 1000上面没有值,下面有一个1329,所以直接是(1000+1329) / 2,因为只有两个值,所是除以2
桔子 1329.00 1355 -- 上面的1000 + 当前的1329 + 下面的1736,然后总和除以3,等于1355
桔子 1736.00 1643 -- 上面的1329 + 当前的1736 + 下面的1864,然后总和除以3,等于1800
桔子 1864.00 1800 -- 上面的1736 + 当前的1864,因为下面没值了,准确的说是该窗口中下面已经没值了,所以总和加起来除以2,等于1800
苹果 511.00 539.5 -- 其它的以此类推
苹果 568.00 642
苹果 847.00 707.5
香蕉 1178.00 1271
香蕉 1364.00 1371.6666666666666667
香蕉 1573.00 1468.5
*/
所以我们看到可以在窗口中指定大小,方式为:rows frame_start或者rows between frame_start and frame_end,如果出现了frame_end那么必须要有frame_start,并且是通过between and的形式
frame_start的取值为:没有frame_end的情况下,unbounded preceding(从窗口的第一行到当前行),n preceding(从当前行的上n行到当前行),current now(从当前行到当前行)。
frame_end的取值为:current now(从frame_start到当前行),n following(从frame_start到当前行的下n行),unbounded following(从frame_start到窗口的最后一行)
具体怎么使用,由你当前业务决定。另外我们目前都是通过rows frame_start和rows between frame_start and between_end,其实这个rows也可以换成range,具体这两者什么区别这里不细说了,可以去网上搜索。但是基本上我们使用rows即可。
小结
窗口函数是一类能够提供复杂统计报表的强大函数,这些功能通常很难使用一般的聚合函数和分组操作来实现。本节介绍了窗口函数的定义和选项,以及如何将聚合函数作为窗口函数使用,实现数据的累计求和与移动分析。
使用窗口函数进行分类排名和环比、同比分析
正文
上一节我们介绍了窗口函数的概念和语法,以及聚合窗口函数的使用。下面我们继续讨论 SQL 中的排名窗口函数和取值窗口函数,它们分别可以用于统计产品的分类排名和数据的环比/同比分析
排名窗口函数:
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
- ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
- RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。
- PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST,计算每行数据在其分区内的累积分布。
- NTILE,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以整个分区(PARTITION BY)作为分析的窗口。接下来我们通过示例了解一下这些函数的作用。
按照分类进行排名:
select product, amount, row_number() over (partition by product order by amount) as sum_amount
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1864.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1178.00 1
香蕉 1364.00 2
香蕉 1573.00 3
*/
我们使用order by进行排序的时候,除了进行累和之外,很多时候也会通过SQL提供的排名窗口函数为其加上一个排名。比如row_numer(),它是针对每个窗口、然后给里面的记录生成1 2 3...这样的序列号。我们先按照amount排个序,然后此时的序列号不就相当于名次了吗。当然如果没有partition by,那么就是针对整个数据集进行排名,因为此时只有一个窗口,也就是整个数据集。
当然如果不排序的话,也是可以使用row_number(),只不过此时的序号就不能代表什么了。
select product, amount, row_number() over (partition by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1000.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1364.00 1
香蕉 1178.00 2
香蕉 1573.00 3
*/
-- 如果不指定order by也是可以使用row_number()生成序列号,但还是那句话,此时的序列号只是单纯的1 2 3...
-- 它不能代表什么。如果还按照amount排序了,那么我们说此时的row_number()则是对应窗口内部的amount的排名。
再来看看rank()
-- rank()就是排名了, 功能和row_number()类似
select product, amount, rank() over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1864.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1178.00 1
香蕉 1364.00 2
香蕉 1573.00 3
*/
-- 如果不指定order by,那么使用rank()会得到什么结果呢?
select product, amount, rank() over (partition by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1
桔子 1329.00 1
桔子 1736.00 1
桔子 1000.00 1
苹果 511.00 1
苹果 568.00 1
苹果 847.00 1
香蕉 1364.00 1
香蕉 1178.00 1
香蕉 1573.00 1
*/
-- 我们看到全部是1,都是第一名
我们看到除了rank,还有dense_rank,那么它们有什么区别呢?假设A和B考了100分,那么A和B都是第一。但如果是rank()的话,紧接着考了99分的C只能是第3名,因为前面已经有两人了,可以认为是按照人数算的;但如果是dense_rank()的话,考了99分的C则是第二名,也就是并列第一看做是一个人,可以认为是按照名次的顺序算的,因为A和B都是第一,那么C就该第二了。
所以两者的区别就在于此。
select product, amount, percent_rank() over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 0
桔子 1329.00 0.3333333333333333
桔子 1736.00 0.6666666666666666
桔子 1864.00 1
苹果 511.00 0
苹果 568.00 0.5
苹果 847.00 1
香蕉 1178.00 0
香蕉 1364.00 0.5
香蕉 1573.00 1
*/
至于percent_rank()则是按照排名计算百分比,区间是[0, 1],也就是位于这个区间的什么位置。
select product,
amount,
rank() over (partition by product order by amount) as rank,
dense_rank() over (partition by product order by amount) as dense_rank,
percent_rank() over (partition by product order by amount) as percent_rank
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1 1 0
桔子 1329.00 2 2 0.3333333333333333
桔子 1736.00 3 3 0.6666666666666666
桔子 1864.00 4 4 1
苹果 511.00 1 1 0
苹果 568.00 2 2 0.5
苹果 847.00 3 3 1
香蕉 1178.00 1 1 0
香蕉 1364.00 2 2 0.5
香蕉 1573.00 3 3 1
*/
-- 关于窗口函数的写法,我们也可以按照如下方式
-- 由于我们这里的窗口都是(partition by product order by amount),如果是多个窗口
-- 那么就是 window r1 as (...), r2 as (...)
select product,
amount,
rank() over r as rank,
dense_rank() over r as dense_rank,
percent_rank() over r as percent_rank
from sales_data
where saledate = '2019-01-01'
window r as (partition by product order by amount)
;
-- 得到的结果和上面是一样的
我们在查询的最后定义了一个窗口(WINDOW)变量 r,然后在窗口函数的 OVER 子句中使用了该变量;这样可以简化函数的输入。不过,Oracle 和 SQL Server 目前还不支持这种写法。
另外,利用排名窗口函数可以获得每个类别中的 Top-N 排行榜。
select * from
(select product,
amount,
rank() over (partition by product order by amount) as rank
from sales_data
where saledate = '2019-01-01') as tmp -- 我们说select from也可以当成一张表来用,tmp就是表名
-- 获取tmp.rank <= 2的,就拿出了每个product对应amount的前两名,当然我们这里是升序排序的
where tmp.rank <= 2;
/*
桔子 1000.00 1
桔子 1329.00 2
苹果 511.00 1
苹果 568.00 2
香蕉 1178.00 1
香蕉 1364.00 2
*/
-- 倒序排序
select * from
(select product,
amount,
rank() over (partition by product order by amount desc) as rank
from sales_data
where saledate = '2019-01-01') as tmp
where tmp.rank <= 2
/*
桔子 1864.00 1
桔子 1736.00 2
苹果 847.00 1
苹果 568.00 2
香蕉 1573.00 1
香蕉 1364.00 2
*/
累积分布与分片位置:
CUME_DIST 函数计算数据对应的累积分布,也就是排在该行数据之前的所有数据所占的比率;取值范围为大于 0 并且小于等于 1。
select product,
amount,
cume_dist() over (order by amount),
percent_rank() over (order by amount)
from sales_data
where saledate < '2019-01-03'
/*
苹果 511.00 0.05263157894736842 0
苹果 564.00 0.10526315789473684 0.05555555555555555
苹果 568.00 0.15789473684210525 0.1111111111111111
桔子 599.00 0.21052631578947367 0.16666666666666666
桔子 775.00 0.2631578947368421 0.2222222222222222
苹果 847.00 0.3157894736842105 0.2777777777777778
桔子 1000.00 0.3684210526315789 0.3333333333333333
香蕉 1057.00 0.42105263157894735 0.3888888888888889
香蕉 1178.00 0.47368421052631576 0.4444444444444444
桔子 1329.00 0.5263157894736842 0.5
苹果 1345.00 0.5789473684210527 0.5555555555555556
香蕉 1364.00 0.631578947368421 0.6111111111111112
香蕉 1573.00 0.6842105263157895 0.6666666666666666
香蕉 1580.00 0.7368421052631579 0.7222222222222222
香蕉 1612.00 0.7894736842105263 0.7777777777777778
桔子 1736.00 0.8421052631578947 0.8333333333333334
桔子 1864.00 0.8947368421052632 0.8888888888888888
桔子 1923.00 0.9473684210526315 0.9444444444444444
苹果 1953.00 1 1
*/
这个cume_dist和percent_rank有点像,但是percent_rank类似于排名,根据记录数将[0, 1]等分,然后计算该值在区间中所占的位置。我们以桔子 1329.00 0.5263157894736842 0.5为例,0.5percent_rank表示该值正好排在中间的位置。0.5263157894736842cume_dist表示有大概百分之52.63的amount小于等于1329。
最后再来看看NTILE,NTILE 函数将分区内的数据分为 N 等份,并计算数据所在的分片位置。
select product,
amount,
ntile(5) over (order by amount)
from sales_data
where saledate = '2019-01-01'
/*
苹果 511.00 1
苹果 568.00 1
苹果 847.00 2
桔子 1000.00 2
香蕉 1178.00 3
桔子 1329.00 3
香蕉 1364.00 4
香蕉 1573.00 4
桔子 1736.00 5
桔子 1864.00 5
*/
-- 为1的表示对应的amount(销售额)最低的百分之20的水果
取值窗口函数:
取值窗口函数用于返回指定位置上的数据。常见的取值窗口函数包括:
- FIRST_VALUE,返回窗口内第一行的数据。
- LAG,返回分区中当前行之前的第 N 行的数据。
- LAST_VALUE,返回窗口内最后一行的数据。
- LEAD,返回分区中当前行之后第 N 行的数据。
- NTH_VALUE,返回窗口内第 N 行的数据。
其中,LAG 和 LEAD 函数不支持动态的窗口大小(frame_clause),而是以分区(PARTITION BY)作为分析的窗口。
我们先来看看lag,lag比较重要,它可以用来计算差值。
select product,
amount,
-- lag是返回当前行的第n行数据,我们这里1
-- 所以第2行,返回第1行,第3行返回第2行,依次类推,至于第1行,由于上面没有东西,所以返回null
lag(amount, 1) over (order by amount)
from sales_data
where saledate = '2019-01-01';
-- 我们这里没有指定分区,所以是整个数据集。如果指定了分区,那么就是每一个窗口
/*
苹果 511.00 null
苹果 568.00 511
苹果 847.00 568
桔子 1000.00 847
香蕉 1178.00 1000
桔子 1329.00 1178
香蕉 1364.00 1329
香蕉 1573.00 1364
桔子 1736.00 1573
桔子 1864.00 1736
*/
-- 如果一来,我们就可以计算amount的增长值,这里还是针对整个数据集
-- 如果想看每一天的增长值,那么就针对日期进行开窗即可。
select product,
amount,
concat(amount, ' - ', lag(amount, 1) over (order by amount), ' = ',
amount - (lag(amount, 1) over (order by amount))
) as incr
from sales_data
where saledate = '2019-01-01';
/*
苹果 511.00 511.00 - =
苹果 568.00 568.00 - 511.00 = 57.00
苹果 847.00 847.00 - 568.00 = 279.00
桔子 1000.00 1000.00 - 847.00 = 153.00
香蕉 1178.00 1178.00 - 1000.00 = 178.00
桔子 1329.00 1329.00 - 1178.00 = 151.00
香蕉 1364.00 1364.00 - 1329.00 = 35.00
香蕉 1573.00 1573.00 - 1364.00 = 209.00
桔子 1736.00 1736.00 - 1573.00 = 163.00
桔子 1864.00 1864.00 - 1736.00 = 128.00
*/
当然计算差值之后,我们还可以用来计算比率。
LEAD 函数与 LAG 函数类似,但它返回的是当前行之后的第 N 行数据。
再来看看first_value、last_value
select product,
amount,
-- 返回每个窗口的第一个排序之后的amount的值
first_value(amount) over (partition by product order by amount),
-- 返回每个窗口的最后一个排序之后的amount的值
last_value(amount) over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1000 1000
桔子 1329.00 1000 1329
桔子 1736.00 1000 1736
桔子 1864.00 1000 1864
苹果 511.00 511 511
苹果 568.00 511 568
苹果 847.00 511 847
香蕉 1178.00 1178 1178
香蕉 1364.00 1178 1364
香蕉 1573.00 1178 1573
*/
-- 我们看到last_value对应的值貌似不太正常,以桔子为例,难道不应该都是1864吗?
-- 其实还是我们之前说的,order by排序之后,会有一个累计的效果,比如前面的窗口函数,如果是sum,那么就会累加
-- 比如第一行1000,那么first_value就是1000,last_value也是1000。
-- 但是到了第二行,显然last_value就是1329了,因为1329是排好序的最后一行(对于当前位置来说),至于first_value在该窗口内部永远是1000,因为1000是第一个值
-- 所以order by让人不容易理解的地方就在于,一旦它被指定,那么就不再是对分区进行整体计算了,而是对窗口内部的记录进行排序、并且进行累计
-- 还是sum,此时不是对整个分区求和、把值添加到分区对应记录中,而是对分区的记录的值进行累加
-- 对应到这里的last_value也是一样的,一开始是1000,但是order by具有累计的效果,至于怎么累计就取决于前面的函数是什么
-- 如果sum就是和下一条记录的值(amount)1329累加,这里是last_value,那么累计在一起就表现在1329取代1000变成了新的最后一行。
-- 当然我们这里以amount进行的order by,而amount都是不一样的
-- 如果按照product就不一样了
select product,
amount,
first_value(amount) over (partition by product order by product),
last_value(amount) over (partition by product order by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1864 1000
桔子 1329.00 1864 1000
桔子 1736.00 1864 1000
桔子 1000.00 1864 1000
苹果 511.00 511 847
苹果 568.00 511 847
苹果 847.00 511 847
香蕉 1364.00 1364 1573
香蕉 1178.00 1364 1573
香蕉 1573.00 1364 1573
*/
-- 每个分区里面的product都是一样的, 而我们按照product进行order by的话
-- 那么相同的product应该作为一个整体,所以结果就是上面的那样
-- 至于first_value和last_value的关系,桔子对应的是first_value大于last_value
-- 苹果对应的是first_value小于last_value,这是由amount的顺序决定的
-- 总之first_value是整个分区的第一条记录,last_value是整个分区的最后一条记录
-- 因为order by指定的是product,而product在每个分区里面都是一样的,而它们是一个整体
-- 有点不好理解,但如果是作用整个分区,order by发挥作用,就是我们上一节说的逻辑
-- 但是像我们通过rows指定窗口大小、以及刚才的leg等等,如果是它们的话,那么就不用考虑order by了
-- 此时的order by只负责排序,计算的话也不是先聚合再累加,而是我们对指定的窗口内的数据进行聚合。
-- 如果是lag,那么order by也只负责排序,怎么计算由lag决定,lag是要求当前数据的上N行的数据。
最后再来看看nth_value,返回窗口内第n行数据
select product,
amount,
-- 返回每个窗口的第2个排序之后的amount的值
nth_value(amount, 2) over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 null
桔子 1329.00 1329
桔子 1736.00 1329
桔子 1864.00 1329
苹果 511.00 null
苹果 568.00 568
苹果 847.00 568
香蕉 1178.00 null
香蕉 1364.00 1364
香蕉 1573.00 1364
*/
-- 这个也是一样,order by也是具有累计的效果
-- 以第一个分区为例,第1行记录是1000,它没有第2个元素,所以是null
-- 第2行记录是1329,那么第2个就是1329
-- 同理第3、第4,第2个也是1329,我们说order by具有累计的效果
SQL Server 目前不支持 NTH_VALUE 函数。
小结
本节我们学习了另外两类窗口函数:用于计算分类排名的排名窗口函数,以及获取指定位置数据的取值窗口函数。SQL 分析函数为数据仓库和在线分析系统(OLAP)提供了强大易用的分析和报表功能,并且在各种数据库中可以通用。
行模式识别(可以跳过)
上节我们学习了如何利用排名窗口函数实现产品的分类排名,以及利用取值窗口函数进行销量的环比/同比分析。
本节我们介绍 SQL:2016 标准新增的一个功能:行模式识别(Row Pattern Recognition)。
行模式识别:
行模式识别用于查找多行数据之间的规律。行模式识别通过指定一个模式(正则表达式),找到匹配该模式的一组数据行;并且可以对这些匹配的一组数据进行过滤、分组和聚合操作。行模式识别可以用于分析各种时间序列数据,例如股票行情数据分析、金融欺诈检测或者系统事件日志分析等。
行模式识别用于查找多行数据之间的规律,与查询条件中的 LIKE 模式匹配是不同的概念。
目前只有 Oracle 12c 实现了该功能,个人觉得难度比较大,有兴趣可以自己去搜索,这里只是提一下,有这么个东西。
什么是 ER 图,如何进行数据库规范化设计?
在进阶篇中我们学习了许多 SQL 高级功能,包括空值的处理、连接查询、子查询、集合运算、通用表表达式、高级分组选项、窗口函数以及上一节的行模式识别(雾)。这些特性可以帮助我们实现各种复杂的数据分析和报表功能。
从今天开始我们将会进入开发篇的学习,了解如何设计数据库的模式、管理表和操作表中的数据、理解数据库事务、索引、视图以及编写服务器端程序。首先,让我们来看看如何设计数据库的结构。
数据库设计流程
数据库设计是对数据进行组织和结构化的过程,关键问题是数据模型的设计。一个良好的设计对于数据库系统至关重要,它可以减少系统中的数据冗余、确保数据的一致性和完整性,同时易于维护和扩展。
常见的数据库设计流程主要包括以下几个步骤:

- 需求分析,收集和分析用户对系统的数据存储和处理需求,记录需要存储的数据对象。
- 概念设计,根据需求创建数据库的概念模型。也就是找出其中的实体、实体的属性以及实体之间的关系,结果通常是实体关系图(Entity-Relationship Diagram)。
- 逻辑设计,设计数据库的关系模式,包括定义表的主键和外键。另外,还需要通过规范化的流程对关系模式进行优化,减少数据的冗余,维护数据的一致性和完整性。
- 物理设计,结合具体使用的数据库管理系统,确定物理数据的存储结构,包括索引的优化等。
- 实施运行,根据设计结果建立实际的数据库环境,进行测试和上线运行。同时,还包含运行环境的维护、调整和优化。
以上流程之间并不是简单的顺序关系,有可能需要反复迭代;但对于简单的应用系统,也有可能跳过一些步骤进行快速设计。
接下来我们介绍数据库设计过程中使用的两种常用技术:实体关系图和规范化。
实体关系图
实体关系图(Entity-Relationship Diagram)是一种用于数据库设计的结构图,它描述了数据库中的实体以及这些实体之间的关系。ERD 包括实体、属性以及关系三个部分。
实体代表了一种对象或者概念。例如,员工、部门和职位都可以称为实体。实体在 ERD 中通常使用长方体来表示。
属性表示实体的某种特性,例如员工拥有姓名、性别、工资、所在部门等属性。属性在 ERD 中通常使用椭圆来表示。
关系则用于表示两个实体之间的相互联系,在 ERD 中通常使用菱形来表示。三种主要的关系类型是一对一、一对多和多对多关系。例如,一夫一妻制是一种典型的一对一的关系;一个员工只能属于一个部门,一个部门可以有多个员工,部门和员工是一对多的关系;一个学生可以选修多门课程,一门课程可以被多个学生选择,学生和课程是多对多的关系。
比如主要包括部门、职位以及员工信息的数据库模型,它们的 ERD 图如下所示:

其中,部门和员工的关系是一对多的关系;职位和员工的关系也是一对多的关系。
进一步来说,ERD 可以按照抽象层次分为三种:
- 概念 ERD,即概念数据模型。描述系统中存在的业务对象以及它们之间的联系,一般给业务分析人员使用。上图就是一个概念 ERD。
- 逻辑 ERD,即逻辑数据模型。对概念数据模型进一步的分解和细化,转换为关系模型。同时,还需要引入规范化过程,对关系模式进行优化。
- 物理 ERD,即物理数据模型。物理 ERD 是针对具体数据库的设计描述,需要为每列指定类型、长度、可否为空等属性,为表增加主键、外键以及索引等。
规范化设计
规范化(Normalization)是数据库设计的一系列原理和技术,主要用于减少表中数据的冗余,增加完整性和一致性。
为什么需要规范化?
假设我们先不考虑规范化,将员工信息、所在部门以及职位信息存储到一个表中,如下图所示:

这种设计存在以下各种问题:
- 数据冗余。同一个部门的信息存储了多份,需要占用更多的磁盘空间;数据冗余有时候也可能是在不同的表中存储了重复的数据;
- 插入异常。如果想要成立一个新的部门,由于还没有增加新的员工,因此无法录入这个部门的信息;
- 删除异常。如果某个部门的所有员工都被删除,该部门的信息也将不复存在;
- 更新异常。如果需要修改部门信息,需要更新多行数据,效率低下;不小心忽略了某些记录的话,将会导致数据不一致。
为了解决这些问题,数据库引入了规范化过程。规范化使用范式来定义和衡量,关系模式的创始人 Edgar Codd 最早提出了第一范式(1NF)、第二范式(2NF)以及第三范式(3NF)。随后又出现了更高级别的范式,包括 BC 范式(BCNF)、第四范式(4NF)等。每个范式都基于前面的范式,例如第二范式需要先满足第一范式。它们之间的关系如下图所示:

下面我们对范式进行具体的分析。对于大多数的数据库系统而言,到达第三范式就已经足够了。
第一范式:
第一范式要求满足以下条件:
- 表中的字段都是不可再分的单一属性;
- 表需要定义主键(PRIMARY KEY)。
简单来说,首先就是每个属性要有单独的字段。在上面的不规范设计中,员工的个人电话和工作电话存储在一个字段中,破坏了原子性。另外,还需要为表定义一个主键,用于唯一识别表中的每一行数据;假设每个部门中的员工不会同名,可以使用部门名称加员工姓名作为主键。
将上面的示例修改成以下结构就可以满足第一范式:
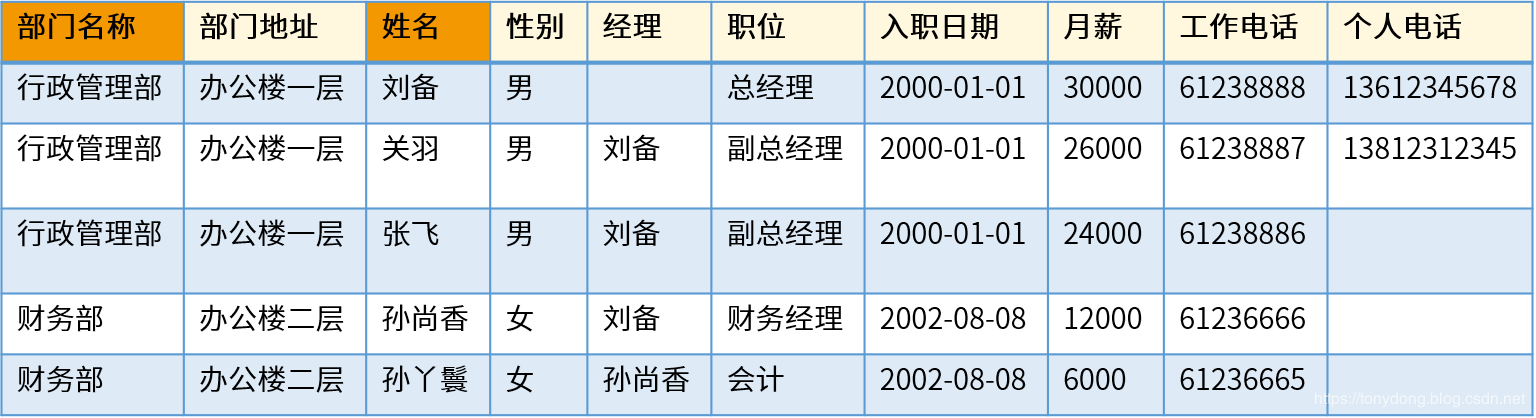
第二范式:
第二范式要求满足以下条件:
- 满足第一范式;
- 非主键字段必须完全依赖于主键,不能只依赖于主键的一部分。
示例中的“部门地址”取决于“部门名称”,也就是主键的一部分;这种依赖关系称为部分函数依赖。显然,此时部门信息存在冗余,可能带来各种操作异常。
此时,可以将部门信息单独存储到一张部门表中,并且在部门表和员工表之间维护一对多的关系。我们继续将表的结构修改如下:

第三范式:
第三范式要求满足以下条件:
- 满足第二范式;
- 属性不依赖于其它的非主属性。
当主键决定字段 A,字段 A 又决定字段 B 时,称为传递函数依赖。例如员工编号决定了部门编号,部门编号决定了部门名称;如果将部门信息和员工信息放在一张表中,就存在这种依赖。在上面的表结构中不存在这种问题,因此满足第三范式。
对于前三个范式而言,只需要将不同的实体/对象单独存储到一张表中,并且通过外键建立它们之间的联系即可满足。
此时,我们再来看看非规范化设计时的几个问题:
- 部门、员工以及职位信息分别存储一份,通过外键保持它们之间的联系。因此,不存在数据冗余的问题;
- 如果想要成立一个新的部门,直接录入部门信息即可,解决了插入异常的问题;
- 如果某个部门的所有员工都被删除,该部门的信息不会受到影响,不存在删除异常;
- 如果需要修改部门信息,直接更新部门表即可,不会导致数据不一致。
反规范化:
简单来说,规范化就是将大表拆分成多个小表,并且通过外键建立它们之间的联系。但是,规范化可能导致连接查询(JOIN)过多,从而降低数据库的性能。因此,有时候为了提高某些查询或者应用的性能而故意降低规范反的程度,也就是反规范化(denormalization)。
常用的反规范化方法包括增加冗余字段、增加计算列、将小表合成大表等。例如想要知道每个部门的员工数量的话,需要同时连接部门表和员工表;可以在部门表中增加一个字段(emp_numbers),查询时就不需要再连接员工表,但是每次增加或者删除员工时需要更新该字段。
反规范化可能带来数据完整性的问题;因此,通常我们应该先进行规范化设计,再根据实际情况考虑是否需要反规范化。一般来说,数据仓库(Data Warehouse)和在线分析系统(OLAP)会使用到反规范化的技术,因为它们以复杂查询和报表分析为主。
关于外键:
在数据库结构设计时,还有一个经常争论的问题就是需不需要使用外键。
外键(FOREIGN KEY)是数据库用于实现参照完整型的约束。利用数据库的外键可以保证数据的完整性和一致性;级联操作可以方便数据的自动处理,减少了程序出错的可能性。
例如,员工属于部门,员工的部门字段上可以创建一个外键引用部门表的主键。此时,我们必须先创建部门,然后才能为该部门创建员工;不会出现员工属于一个不存在的部门的情况,保证了数据的完整性。另一方面,如果要删除一个部门的话,必须同时处理该部门下的员工;可以选择级联删除员工或者将员工的部门修改为其他部门等操作。
既然外键拥有这么多好处,为什么我们还要讨论是否需要使用外键呢?主要是性能问题。因为任何事情都是有代价的,数据库为了维护外键需要牺牲一定的性能,尤其是在大数据量高并发的情况下。因此出现了另一种解决方案,就是将完整性检查放到应用层去实现,而应用程序相对比较容易扩展。
不过,在应用端实现约束也可能导致一些问题。首先,无法百分之百保证不会出现问题,尤其是多个应用同时共享一个数据库时。缺失外键可能导致数据库的结构不明确,需要依赖相应的文档进行说明。
总之,在系统的设计之初应该尽量使用外键确保完整性。如果随着业务增长出现性能问题,可以考虑在应用中实现约束。
小结
合理的设计是数据库有效运行和易于扩展的前提,数据库设计本质上一个多方面因素权衡的过程。利用 ERD 和规范化技术设计数据库的结构,可以提高数据库的存储效率、完整性和可扩展性。
SQL 支持哪些数据类型,使用时如何进行选择?
上节我们讨论了如何进行数据库的结构设计,并具体介绍了实体关系图和规范化的技术。
在设计 ERD 时,首先需要定义实体以及实体的属性,也就是定义表的结构。定义表结构时,首先需要确认表中包含哪些字段以及字段的数据类型。今天我们就来了解一下如何为表中的字段选择合适的数据类型。
常见数据类型
字段的数据类型定义了该字段能够存储的数据值,以及允许执行的操作。
字符串类型:
字符串类型用于存储字符和字符串数据,主要包含三种具体的类型:定长字符串、变长字符串以及字符串大对象。各种数据库对于字符串类型的支持如下:
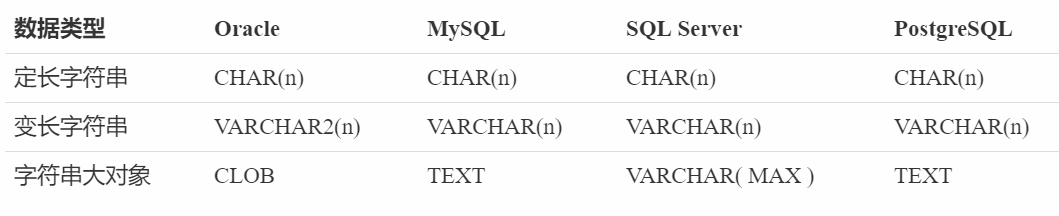
CHAR(n) 表示长度固定的字符串,其中 n 表示字符串的长度。常见的定义方式包括:
- CHAR,长度为 1 的字符串,只能存储 1 个字符;
- CHAR(5),长度为 5 的字符串。
对于定长字符串,如果输入的字符串长度不够,将会使用空格进行填充。例如类型为 CHAR(5) 的字段,如果输入值为“A”,实际存储的内容为“A####”;# 代表空格,也就是一个字符“A”加上 4 个空格。
CHARACTER 和 CHAR 是同义词,可以通用。
通常来说,只有存储固定长度的数据时,才会考虑使用定长字符串类型。例如 18 位身份证,6 位邮政编码等。
VARCHAR(n) 表示长度不固定的字符串,其中 n 表示允许存储的最大长度。
对于变长字符串,如果输入的字符串长度不够,存储实际的内容。例如类型为 VARCHAR(5) 的字段,如果输入值为“A”,实际存储的内容为“A”。
CHAR VARYING 和 CHARACTER VARYING 是 VARCHAR 的同义词,可以通用。 Oracle 中使用 VARCHAR2 表示变长字符串类型。
变长字符串类型一般用于存储长度不固定的内容,例如名字、电子邮箱、产品描述等。
CLOB 表示字符串大对象,通常用于存储普通字符串类型无法支持的更长的字符串数据。例如整篇文章、备注、评论等。
Oracle 使用 CLOB 类型存储大型字符串;MySQL 提供了 TINYTEXT、TEXT、MEDIUMTEXT 以及 LONGTEXT 分别用于存储不同长度的文本数据;SQL Server 使用 VARCHAR( MAX ) 存储大文本数据;PostgreSQL 提供了 TEXT 类型存储任意长度的字符串。
CHARACTER LARGE OBJECT 和 CHAR LARGE OBJECT 是 CLOB 的同义词,可以通用。
在 SQL 中,输入字符串类型的常量和数据时,需要使用单引号引用:
'S001'
'张飞'
'13512345678'
数字类型:
数字类型主要分为两类:精确数字和近似数字。
精确数字类型用于存储整数或者包含固定小数位的数字。
其中,SMALLINT、INTEGER 和 BIGINT 都可以表示整数。对于 MySQL、SQL Server 以及 PostgreSQL,SMALLINT 支持 -32768 ~ 32767;INTEGER 支持 -2147483648 ~ 2147483647;BIGINT 支持 -2^63^ ~ 2^63^-1。Oracle 中的 SMALLINT 和 INTEGER 都是NUMBER(38,0) 的同义词;Oracle 不支持 BIGINT 关键字。
INT 是 INTEGER 的同义词,可以通用。 MySQL 中还提供了 TINYINT,支持 -128 ~ 127;MEDIUMINT 支持 -8388608 ~ 8388607。另外,MySQL 中的所有整型分为有符号类型(例如 INTEGER、INTEGER SIGNED)和无符号类型(例如 INTEGER UNSIGNED),无符号整型支持的正整数范围扩大了一倍。
NUMERIC(p, s) 和 DECIMAL(p, s) 可以看作相同的类型,用于存储包含小数的精确数字。
其中,精度 p 表示总的有效位数,刻度 s 表示小数点后允许的位数。例如,123.04 的精度为 5,刻度为 2。p 和 s 是可选的,s 为 0 表示整数。SQL 标准要求 p ≥ s ≥ 0 并且 p > 0。
DEC 是 DECIMAL 的同义词,可以通用。 Oracle中的 NUMERIC 和 DECIMAL 都是 NUMBER 的同义词
整数类型通常用于存储数字 id、产品数量、课程得分等数字;NUMERIC 用于存储产品价格、销售金额等包含小数并且准确度要求高的数据。
近似数字也称为浮点型数字,一般使用较少,主要用于科学计算领域。
REAL 表示单精度浮点数,通常精确到小数点后 6 位;DOUBLE PRECISION 表示双精度浮点数,通常精确到小数点后 15 位。浮点数运算更快,但是可能丢失精度;浮点数的比较运算可能会导致非预期的结果。
Oracle 使用 BINARY_FLOAT 和 BINARY_DOUBLE 表示浮点数。 MySQL 使用 FLOAT 表示单精度浮点数,同时区分有符号和无符号的浮点数。
日期时间类型:
DATE 存储年、月、日;TIME 存储时、分、秒,以及秒的小数部分;TIMESTAMP 同时包含年、月、日、时、分、秒,以及秒的小数部分。
Oracle 中的 DATE 类型包含了额外的时、分、秒,不支持 TIME 类型。 SQL Server 使用 DATETIME2 和 DATETIMEOFFSET 表示时间戳。 MySQL 还支持 DATETIME 表示时间戳。
如果存储日期信息,例如生日,可以使用 DATE 类型;如果需要更高的时间精度,例如订单时间、发车时间等,可以使用 TIMESTAMP 类型;TIME 类型使用较少。
在 SQL 中,输入日期时间类型的常量和数据时,常见的方法如下:
'2019-12-25'
DATE '2019-12-25'
'13:30:15'
TIME '13:30:15'
'2019-12-25 13:30:15'
TIMESTAMP '2019-12-25 13:30:15'
二进制类型:
二进制类型用于存储二进制数据,例如文档、图片,视频等。二进制类型具体包含以下三种:
- BINARY(n),固定长度的二进制数据,n 表示二进制字符数量;
- VARBINARY(n),可变长度的二进制数据,n 表示支持的最大二进制字符数量;
- BLOB,二进制大对象。
Oracle 支持 BLOB 二进制类型;MySQL 支持 BINARY、VARBINARY 以及 TINYBLOB、BLOB、MEDIUMBLOB、LONGBLOB 二进制类型;SQL Server 支持 BINARY、VARBINARY 以及 VARBINARY ( MAX ) 二进制类型;PostgreSQL 支持 BYTEA 二进制类型。
选择合适的数据类型:
最后我们来看看如何选择合适的数据类型。首先,应该满足存储业务数据的需求;其次,还需要考虑性能和使用方便。一般来说,先确定基本的类型:
- 文本数据,只能使用字符串类型;
- 数值数据,尤其是需要进行数学运算的数据,选择数字类型;
- 日期和时间信息,最好使用原生的日期时间类型;
- 文档、图片、音频和视频等,使用二进制类型;或者可以考虑存储在文件服务器上,然后在数据库中存储文件的路径。
接下来需要进一步确定具体的数据类型。在满足数据存储和扩展的前提下,尽量使用更小的数据类型,可以节省一些存储,通常性能也会更好。例如,对于一个小型公司而言,员工编号通常不会超过几百,使用 SMALLINT 已经足够。对于 MySQL 而言,不需要支持负数的话可以考虑 UNSIGNED 类型。
如果需要存储精确的数字,不要使用浮点数类型。对于金额,可以使用 NUMERIC(p, s);或者将数据乘以 10 的 N 次方,例如将 10.35 元存储为整数 103500,然后在应用程序中进行处理和前端显示转换。
对于字符数据,一般使用 VARCHAR 类型;如果数据长度能够确保一致,可以使用 CHAR;指定最大长度时,满足存储需求的前提下尽量使用更小的值。只有在普通字符串类型长度无法满足时才考虑大字段类型。
不要使用字符串存储日期时间数据,它们无法支持数据的运算。例如获得两个日期之间的间隔,需要依赖应用程序进行转换和处理。最好也不要使用整数类型存储当前时间距离 1970 年 1 月 1 日的毫秒数来表示时间,这种方式在显示时需要进行转换,不是很方便。
另外,如果一个字段同时出现在多个表中,使用相同的数据类型。例如,员工表中的部门编号(dept_id)字段与部门表的编号(dept_id)字段保持类型一致。
小结
今天我们介绍了 SQL 中的基本数据类型以及它们在各种数据库中的实现,同时分析了选择数据类型时的一些通用的原则。需要注意的是,同一数据类型在不同数据库中支持的范围大小和精确度可能不同;因此,使用任何数据类型之前都应该查看相关的数据库文档。
使用 DDL 管理数据库中的对象
正文
上节我们讨论了如何为字段选择合适的数据类型。选定了字段的数据类型之后,我们就可以开始创建和管理数据库中的表了。
数据库对象:
数据库(Database)由一组相关的对象组成,主要包括表、索引、视图、存储过程等。为了方便对象的管理和访问,数据库通常使用模式(Schema)来组织这些对象;模式是一个逻辑单元,或者一个存储对象的容器;它们之间的关系如下图所示:
一个数据库由多个模式组成,一个模式由许多对象组成;在不同模式中可以创建同名的对象。
MySQL 中的模式和数据库是相同的概念,一个数据库对应一个同名的模式。
管理数据库:
当我们连接到数据库服务器时,需要指定一个目标数据库。如果需要创建一个新的数据库,可以使用 CREATE DATABASE 语句:
CREATE DATABASE mydb;
以上语句将会创建一个名为 mydb 的数据库。对于 Oracle 而言,通常只有一个数据库;因此很少手动创建数据库。
我们可以使用命令或语句查看已有的数据库
-- MySQL 实现
SHOW DATABASES;
SELECT schema_name AS database_name
FROM information_schema.schemata;
-- information_schema 系统数据库存储了 MySQL 服务器中所有数据库的信息,例如数据库名称、表的结构以及访问权限等。
-- SQL Server 实现
SELECT name AS database_name
FROM sys.databases;
-- sys.databases 是 SQL Server 中的一个系统表,存储了关于数据库的信息。
-- PostgreSQL 实现
SELECT datname AS database_name
FROM pg_database;
-- pg_database 是 PostgreSQL 中的一个系统表,存储了关于数据库的信息。
-- Oracle 实现
SELECT name AS database_name
FROM v$database;
-- v$database 是 Oracle 中的一个系统视图,提供了关于数据库的信息。
如果确认不再需要,可以使用 DROP DATABASE 语句删除数据库:
DROP DATABASE mydb;
DROP DATABASE 命令将会删除该数据库中的所有对象,而且操作无法恢复,使用时千万小心!
如果有用户正在连接,无法删除数据库;可以等待用户断开连接,或者强制断开连接后删除。
管理模式:
CREATE SCHEMA 命令用于创建一个新的模式:
-- SQL Server 以及 PostgreSQL 实现
create schema xxx [AUTHORIZATION some_user]
以上语句创建一个名为 xxx 的模式,可选的 AUTHORIZATION 表示为该模式指定一个拥有者 some_user,拥有者是一个已经存在的数据库用户。
SQL Server 创建数据库时会自动创建一个名为 dbo 的模式,PostgreSQL 创建数据库时会自动创建一个名为 public 的模式。
MySQL 中的模式等价于数据库,因此 CREATE SCHEMA 等价于 CREATE DATABASE。
Oracle 中的模式等价于用户,因此使用 CREATE USER 命令创建用户时就相当于创建一个同名的模式:
CREATE USER some_user
IDENTIFIED BY xxx;
Oracle 也提供了 CREATE SCHEMA 命令,但不是用于创建模式,而是用于在模式中创建表、视图以及执行授权操作。
不需要的模式可以使用 DROP SCHEMA 命令删除:
-- SQL Server 以及 PostgreSQL 实现
DROP SCHEMA xxx;
MySQL 中的模式等价于数据库,因此 DROP SCHEMA 等价于 DROP DATABASE。
Oracle 中的模式等价于用户,因此使用 DROP USER 命令创建用户时就相当于创建一个同名的模式:
-- Oracle 实现
DROP USER hr;
如果模式中存在对象,则无法删除该模式;可以先删除其中的对象,再删除模式。某些数据库支持级联删除:
-- PostgreSQL 实现
DROP SCHEMA xxx CASCADE;
-- Oracle 实现
DROP USER some_user CASCADE;
复制表:
像创建表、添加记录、修改记录等等比较简单,我们这里就不提了,可以去菜鸟教程上面搜索,非常简单,
除了手动创建表之外,也可以基于其他表或者查询的结果创建一个表:
CREATE TABLE table_name
AS
SELECT ...;
修改表:
对于已经存在的表,可能会由于业务变更或者代码重构需要修改它的结构。因此,SQL 定义了修改表的语句:
其中的 action 表示执行的操作,常见的操作包括增加列,修改列,删除列;增加约束,修改约束,删除约束等。以下语句用于增加一个新的字段:
ALTER TABLE table_name
ADD 列名 类型 [约束];
-- 添加字段的内容和创建表时类似,包括字段名、数据类型以及可选的列约束
如果某个字段不再需要,可以使用 DROP COLUMN 操作删除:
ALTER TABLE table_name drop 列名
删除表:
-- DROP TABLE 语句用于删除一个表。
DROP TABLE table_name
截断表:
SQL 还提供了一种特殊的操作:截断表(TRUNCATE),可以用于快速删除表中的所有数据。
TRUNCATE TABLE table_name
TRUNCATE 用于快速删除数据,回收表占用的空间,但会保留表的结构。MySQL 和 PostgreSQL 可以省略 TABLE 关键字。
小结
数据定义语言(Data Definition Language)用于定义数据库中各种对象的结构,例如表、视图、索引等。常见的 DDL 语句包括创建(CREATE)、修改(ALTER)和删除(DROP)。虽然各种对象的具体语法细节不同,但都遵循相同的模式;例如,创建索引可以使用 CREATE INDEX 语句;
为什么数据库事务如此重要?
正文
当我们在操作数据的同时,其他人或者应用程序可能也在操作相同的数据;此时数据库必须保证多个用户之间不会产生影响,数据不会出现不一致性。这就涉及到一个重要的概念:数据库事务(Transaction)。
什么是数据库事务:
在企业应用中,数据库通常需要支持多用户并发访问;并且保证多个用户并发访问相同的数据时,不会造成数据的不一致性和不完整性。同时,在用户执行操作的过程中,可能会遇到系统崩溃、介质失效等故障,数据库也必须能够从失败的状态恢复到一致状态。这些核心功能在数据库中都是通过事务来实现的。
在数据库中,事务是指一组相关的 SQL 语句,它们在业务逻辑上组成一个原子单元。数据库必须保证事务中的所有操作全部成功,或者全部撤销。
最常见的数据库事务就是银行账户之间的转账操作;例如从 A 账户转出 1000 元到 B 账户,就是一个事务,该事务主要包括以下步骤:
- 查询 A 账户的余额是否足够;
- 从 A 账户减去 1000 元;
- 往 B 账户增加 1000 元;
- 记录本次转账流水。
显然,数据库必须保证所有的操作要么全部成功,要么全部失败。如果从 A 账户减去 1000 元成功执行,但是没有往 B 账户增加 1000 元,意味着客户将会损失 1000 元。用数据库中的术语来说,这种情况导致了数据库的不一致性。
事务控制语句:
SQL 定义了用于管理数据库事务的事务控制语句(Transaction Control Language)。MySQL 实现了以下语句:
- BEGIN 或者 START TRANSACTION,开始一个事务;
- COMMIT,提交事务;
- ROLLBACK,撤销事务;
- SAVEPOINT,事务保存点,用于撤销部分事务;
- SET autocommit = {0 | 1},设置事务是否自动提交。
事务的 ACID 属性:
SQL 标准定义了数据库事务的四种特性:ACID。
原子性
原子性(Atomic)是指一个事务包含的所有 SQL 语句要么全部成功,要么全部失败。例如,某个事务需要更新 100 条记录;但是在更新到一半时系统出现故障,数据库必须保证能够回滚已经修改过的数据,就像没有执行过任何修改一样。
一致性
一致性(Consistency)意味着事务开始之前,数据库位于一致性的状态;事务完成之后,数据库仍然位于一致性的状态。例如,银行转账事务中;如果一个账户扣款成功,但是另一个账户加钱失败,就会出现数据不一致(此时需要回滚已经执行的扣款操作)。另外,数据库还必须保证满足完整性约束,比如账户扣款之后不能出现余额为负数(在余额字段上添加检查约束)。
隔离性
隔离性(Isolation)与并发事务有关,一个事务的影响在提交之前对其他事务不可见,多个并发的事务之间相互隔离。例如,账户 A 向账户 B 转账的过程中,账户 B 查询的余额应该是转账之前的数目;如果多人同时向账户 B 转账,结果也应该保持一致性,和依次进行转账的结果一样。SQL 标准定义了 4 种不同的事务隔离级别,我们将会在下文进行介绍。
持久性
持久性(Durability)表示已经提交的事务必须永久生效,即使发生断电、系统崩溃等故障,数据库都不会丢失数据。数据库系统通常使用重做日志(REDO)或者预写式日志(WAL)实现事务的持久性。简单来说,它们都是在提交之前将数据的修改操作记录到日志文件中;当数据库出现崩溃时,可以利用这些日志重做之前的修改,从而避免数据的丢失。
对于我们开发者而言,重点需要注意的是隔离级别,而隔离级别又与并发访问有关。
并发与隔离级别:
数据库的并发意味着多个用户同时访问相同的数据,例如 A 和 C 同时给 B 转账。数据库的并发访问可能带来以下问题:
- 脏读(Dirty Read)。当一个事务允许读取另一个事务修改但未提交的数据时,就可能发生脏读。例如,B 的初始余额为 0;A 向 B 转账 1000 元但没有提交;此时 B 能够看到 A 转过来的 1000 元,并且成功取款 1000 元;然后 A 取消了转账;银行损失了 1000 元。很显然,银行不会允许这种事情发生。
- 不可重复读(Nonrepeatable Read)。一个事务读取某一记录后,该数据被另一个事务修改提交,再次读取该记录时结果发生了改变。例如,B 查询初始余额为 0;此时 A 向 B 转账 1000 元并且提交;B 再次查询发现余额变成了 1000 元,以为天上掉馅饼了。
- 幻读(Phantom Read)。一个事务第一次读取数据后,另一个事务增加或者删除了某些数据,再次读取时结果的数量发生了变化。幻读和非重复读有点类似,都是由于其他事务修改数据导致的结果变化。
- 更新丢失(Lost Update)。第一类:当两个事务更新相同的数据时,如果第一个事务被提交,然后第二个事务被撤销;那么第一个事务的更新也会被撤销。第二类:当两个事务同时读取某一记录,然后分别进行修改提交;就会造成先提交的事务的修改丢失。
为了解决并发访问可能导致的各种问题,SQL标准定义了 4 种不同的事务隔离级别(从低到高):
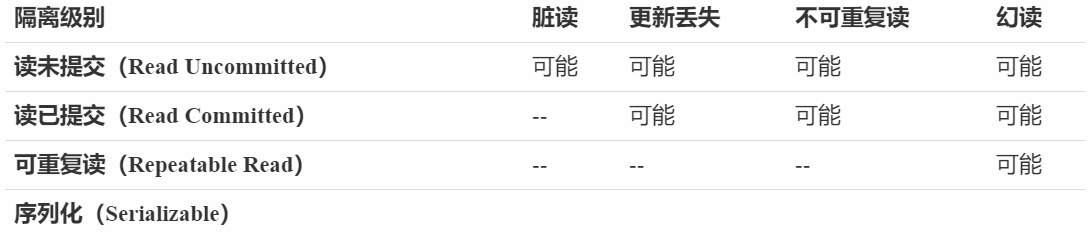
读未提交隔离级别最低,一个事务可以看到其他事务未提交的修改。该级别可能产生各种并发异常;如果一个事务已经修改某个数据,则另一个事务不允许同时修改该数据,写操作一定是按照顺序执行。PostgreSQL 消除了读未提交级别时的脏读。读已提交只能看到其他事务已经提交的数据,不会出现脏读。可重复读可能出现幻读。MySQL 中的 Innodb 存储引擎和 PostgreSQL 在可重复读级别消除了幻读。序列化提供最高级别的事务隔离。它要求事务只能一个接着一个地执行,不支持并发访问。
事务的隔离级别越高,越能保证数据的一致性;但同时会对并发带来更大的影响。不同数据库默认使用的隔离级别如下:
- Oracle、SQL Server 以及 PostgreSQL 默认使用读已提交隔离级别;
- MySQL InnoDB 存储引擎默认使用可重复读隔离级别。
一般情况下,大多数数据库的默认隔离级别为读已提交;此时,可以避免脏读,同时拥有不错的并发性能。尽管可能会导致不可重复度、幻读以及丢失更新,但是可以通过应用程序加锁进行处理。
小结
数据库事务是指多个相关操作组成一个原子单元,所有操作全部成功,或者全部失败。事务具有 ACID 属性,能够确保数据库的完整性和一致性。数据库通过隔离来实现对并发事务的支持,隔离级别与并发性能不可兼得,在开发应用程序时需要进行权衡和选择;一般情况下,我们使用数据库的默认隔离级别。
索引一定能提高性能吗?
正文
上节我们介绍了数据库事务的概念和重要性、事务的 ACID 属性,以及并发事务的控制与隔离级别。
本节我们讨论与性能相关的一个重要对象:索引(Index)。你一定听说过:索引可以提高查询的性能。那么,索引的原理是什么呢?有了索引就一定可以查询的更快吗?索引只是为了优化查询速度吗?接下来我们就一一进行解答。
索引的原理:
以下是一个简单的查询,查找工号为 5 的员工:
SELECT *
FROM employee
WHERE emp_id = 5;
数据库如何找到我们需要的数据呢?如果没有索引,那就只能扫描整个 employee 表,然后使用工号依次判断并返回满足条件的数据。这种方式一个最大的问题就是当数据量逐渐增加时,全表扫描的性能也就随之明显下降。
为了解决查询的性能问题,数据库引入了一个新的数据结构:索引。索引就像书籍中的关键字索引,按照关键字进行排序,并且提供了指向具体内容的页码。如果我们在 email 字段上创建了索引(例如 B-树索引),数据库查找的过程大概如下图所示:

B-树(Balanced Tree)索引就像是一棵倒立的树,其中的节点按照顺序进行组织;节点左侧的数据都小于该节点的值,节点右侧的数据都大于节点的值。数据库首先通过索引查找到工号为 5 的节点,再通过该节点上的指针(通常是数据的物理地址)访问数据所在的磁盘位置。
举例来说,假设每个索引分支节点可以存储 100 个记录,100 万(100^3)条记录只需要 3 层 B-树即可完成索引。通过索引查找数据时需要读取 3 次索引数据(每次磁盘 IO 读取整个分支节点),加上 1 次磁盘 IO 读取数据即可得到查询结果。
如果采用全表扫描,需要执行的磁盘 IO 可能高出几个数量级。当数据量增加到 1 亿时,B-树索引只需要再增加一次索引 IO 即可;而全表扫描需要再增加几个数量级的 IO。
以上只是一个简化的 B-树索引原型,实际的数据库索引还会在索引节点之间增加互相连接的指针(B+树),能够提供更好的查询性能。该网站提供了一个可视化的 B+树模拟程序,可以直观地了解索引的维护和查找过程。
索引的类型:
虽然各种数据库支持的索引不完全相同,对于相同的索引也可能存在实现上的一些差异;但它们都实现了许多通用的索引类型。
B-树索引与 Hash 索引
B-树索引,使用平衡树或者扩展的平衡树(B+树、B*树)结构创建索引。这是最常见的一种索引,主流的数据库默认都采用 B-树索引。这种索引通常用于优化 =、<、<=、>、BETWEEN、IN 以及字符串的前向匹配('abc%')查询。
Hash 索引,使用数据的哈希值创建索引。使用哈希索引查找数据的过程如下:
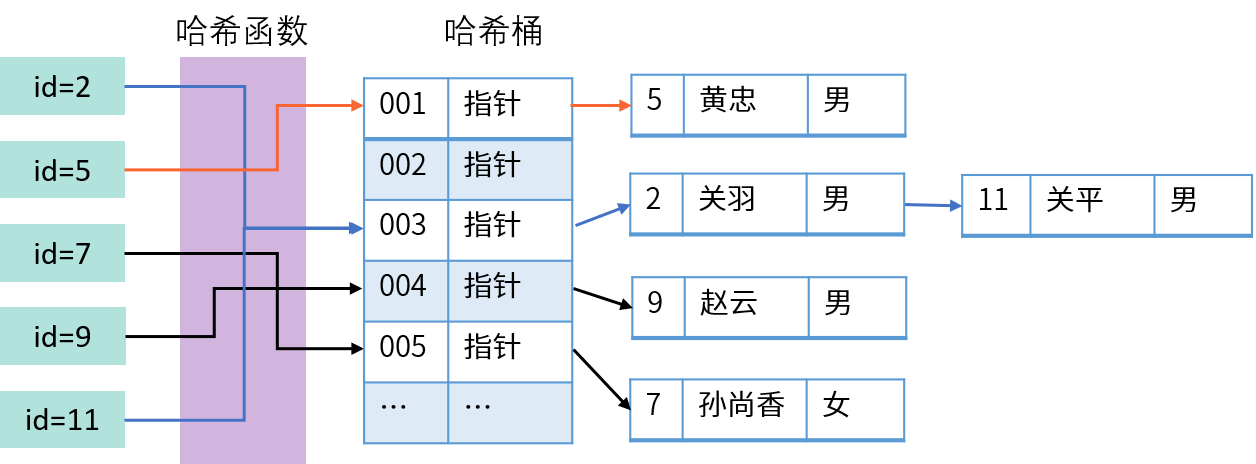
查询时通过检索条件(例如 id=5)的哈希值直接进行匹配,从而找到数据所在的位置。哈希索引主要用于等值(=)查询,速度更快;但是哈希函数的结果没有顺序,因此不适合范围查询,也不能用于优化 ORDER BY 排序。
聚集索引与非聚集索引:
聚集索引(Clustered index)将表中的数据按照索引的结构(通常是主键)进行存储。也就是说,索引的叶子节点中存储了表的数据。
严格来说,聚集索引其实是一种特殊的表。MySQL(InnoDB 存储引擎)和 SQL Server 将这种结构的表称为聚集索引,Oracle 中称为索引组织表(IOT)。这种存储数据的方式适合使用主键进行查询的应用,类似于 key-value 系统。
非聚集索引就是普通的索引,索引的叶子节点中存储了指向数据所在磁盘位置的指针,数据在磁盘上随机分布。MySQL(InnoDB 存储引擎)称之为二级索引(Secondary index),叶子节点存储的是聚集索引的键值(通常是主键);通过二级索引查找时需要先找到相应的主键值,再通过主键索引查找数据。因此,创建聚集索引的主键字段越小,索引就越小;一般采用自增长的数字作为主键。
SQL Server 如果使用聚集索引创建表,非聚集索引的叶子节点存储的也是聚集索引的键值;否则,非聚集索引的叶子节点存储的是指向数据行的地址。
唯一索引与非唯一索引:
唯一索引(UNIQUE)中的索引值必须唯一,可以确保被索引的数据不会重复,从而实现数据的唯一性约束。
非唯一索引允许被索引的字段存在重复值,仅仅用于提高查询的性能。
单列索引与多列索引:
单列索引是基于单个字段创建的索引。例如,员工表的主键使用 emp_id 字段创建,就是一个单列索引。
多列索引是基于多个字段创建的索引,也叫复合索引。创建多列索引的时候需要注意字段的顺序,查询条件中最常出现的字段放在最前面,这样可以最大限度地利用索引优化查询的性能。
其他索引类型:
全文索引(Full-text),用于支持全文搜索,类似于 Google 和百度这种搜索引擎。
函数索引,基于函数或者表达式的值创建的索引。例如,员工的 email 不区分大小写并且唯一,可以基于 UPPER(email) 创建一个唯一的函数索引。
有了索引的概念之后,我们来看一下如何创建和管理索引。
维护索引:
使用 CREATE INDEX 语句创建索引,默认情况下创建的是 B+ 树索引:
CREATE [UNIQUE] INDEX index_name
ON table_name(col1 [ASC | DESC], ...);
其中,UNIQUE 表示创建唯一索引;ASC 表示索引按照升序排列,DESC 表示索引按照降序排列,默认为 ASC。
定义主键和唯一约束时,数据库自动创建相应的索引。MySQL InnoDB 存储引擎也会自动为外键约束创建索引。
DROP INDEX 语句用于删除一个索引:
-- Oracle 和 PostgreSQL 实现
DROP INDEX idx_emp_devp_name;
-- MySQL 和 SQL Server 实现
DROP INDEX idx_emp_devp_name ON emp_devp; -- 对于 MySQL 和 SQL Server 而言,删除索引时需要指定表名:
索引不是约束:
在数据库中,索引还用于实现另一个功能:主键约束和唯一约束。因此,很多人存在一个概念上的误解,认为索引就是约束。唯一约束是指字段的值不能重复,但是可以为 NULL;例如,员工的邮箱需要创建唯一约束,确保不会重复。
理论上可以编写一个程序,在每次新增或修改邮箱时检查是否与其他数据重复,来实现唯一约束;但是这种方式的性能很差,并且无法解决并发时的冲突问题。但是,如果在该字段上增加一个唯一索引,就很方便地满足了唯一性的要求,而且能够提高以邮箱作为条件时的查询性能。
索引注意事项:
既然索引可以优化查询的性能,那么我们是不是应该将所有字段都进行索引?显然并非如此,因为索引在提高查询速度的同时也需要付出一定的代价。
首先,索引需要占用磁盘空间。索引独立于数据而存在,过多的索引会导致占用大量的空间,甚至超过数据文件的大小。
其次,对数据进行 DML 操作时,同时也需要对索引进行维护;维护索引有时候比修改数据更加耗时。
索引是优化查询的一个有效手段,但是过渡的索引可能给系统带来负面的影响。我们将会在第 34 篇中讨论如何创建合适的索引,利用索引优化 SQL 语句,以及检查索引是否被有效利用等。
小结
SQL 语句的声明性使得我们不需要关心具体的操作实现,但同时也可能因此导致数据库的性能问题。索引可以提高数据检索的速度,也可以用于实现唯一约束;但同时索引也需要占用一定的磁盘空间,索引的维护需要付出一定的代价。
视图有哪些优缺点,什么时候使用视图?
正文
上节我们介绍了索引的概念、索引提高查询性能的原理,以及索引需要付出的代价。
这节我们来讨论另一个重要的数据库对象:视图(View),学习如何利用视图简化查询语句、实现业务规则以及提高数据的安全性。
视图不是表:
简单来说,视图就是一个预定义的查询语句。视图在许多情况下可以当作表来使用,因此也被称为虚拟表(Virtual Table)。视图与表最大的区别在于它不包含数据,数据库中只存储视图的定义语句。以下是一个视图的示意图:

知道了什么是视图,那为什么需要视图呢?因为它可以给我们带来许多好处:
- 替代复杂查询,减少复杂性。将复杂的查询语句定义为视图,然后使用视图进行查询,可以隐藏具体的实现;
- 提供一致性接口,实现业务规则。在视图的定义中增加业务逻辑,对外提供统一的接口;当底层表结构发生变化时,只需要修改视图接口,而不需要修改外部应用,可以简化代码的维护并减少错误;
- 控制对于表的访问,提高安全性。通过视图为用户提供数据访问,而不是直接访问表;同时可以限制允许访问某些敏感信息,例如身份证号、工资等。
不过,视图也可能带来一些问题:
- 不当的使用可能会导致性能问题。视图的定义中可能包含了复杂的查询,例如嵌套的子查询和多个表的连接查询,可能导致使用视图进行查询时性能不佳;
- 视图通常用于查询操作,可更新视图(Updatable View)需要满足许多限制条件。可更新视图可以支持通过视图对底层表进行增删改的操作。
接下来我们介绍如何创建、修改、删除和使用视图。
创建视图:
-- 我们可以使用 CREATE VIEW 语句创建一个新的视图:
CREATE VIEW view_name
AS select_statement;
其中,view_name 是视图的名称;select_statement 是视图的定义,也就是一个 SELECT 语句。视图可以基于一个或多个表定义,也可以基于其他视图进行定义。创建视图之后,可以像普通表一样将视图作为查询的数据源。
视图定义中的 SELECT 语句与普通的查询一样,可以包含任意复杂的选项。例如子查询、集合操作、分组聚合等。但有一个需要注意的选项就是 ORDER BY 子句。许多数据库都支持在视图定义中使用 ORDER BY 子句;但是 SQL 标准并不支持这种写法,因为视图并不存储数据。所以建议最好不要在视图的定义中使用 ORDER BY,因为这种排序并不能保证最终结果的顺序;而且可能由于不必要的排序降低查询的性能。
修改视图:
如果需要修改视图的定义,可以删除并重新创建视图。除此之外,各种数据库也提供了直接替换视图定义的命令:
-- Oracle、MySQL 以及 PostgreSQL 实现
CREATE OR REPLACE VIEW view_name
AS select_statement;
-- SQL Server 实现
CREATE OR ALTER VIEW view_name
AS select_statement;
其中 CREATE OR REPLACE VIEW 表示如果视图不存在,创建视图;如果视图已经存在,替换视图。SQL Server 使用 CREATE OR ALTER VIEW 实现相同的功能。
MySQL 和 SQL Server 还支持使用 ALTER VIEW view_name AS select_statement; 命令修改视图的定义。 Oracle 和 PostgreSQL 中的 ALTER VIEW 命令用于修改视图的其他属性。
删除视图:
-- 使用 DROP VIEW 命令可以删除一个视图:
DROP VIEW [IF EXISTS] view_name;
指定 IF EXISTS 选项后,删除一个不存在的视图时也不会产生错误。Oracle 不支持 IF EXISTS 选项。
通常来说,视图主要用于查询数据;但是某些视图也可以用于修改数据,这种视图被称为可更新视图(Updatable View)。
可更新视图:
可更新视图是指通过视图更新底层表,对于视图的 INSERT、UPDATE、DELETE 等操作最终会转换为针对底层基础表的相应操作。可更新视图的定义需要满足许多限制条件,包括:
- 不能使用聚合函数或窗口函数,例如 AVG、SUM、COUNT 等;
- 不能使用 DISTINCT、GROUP BY、HAVING 子句;
- 不能使用集合运算符,例如 UNION、INTERSECT 等;
- 修改操作只能涉及单个表中的字段,不能同时修改多个表;
- 不同数据库实现的其他限制条件。
总之,对视图的修改只有在能够映射为对基础表的修改时,数据库才能执行视图的修改操作。
小结
视图与子查询和通用表表达式有类似之处,都可以作为查询的数据源;但是视图是存储在数据库中的对象,可以被重复使用。合理的使用视图可以实现底层数据表的隐藏,对外提供一致接口,提高数据访问的安全性。不过,复杂的视图可能导致维护和性能问题;在实际应用之前最好进行相关的性能测试。
存储过程以及触发器
存储过程和触发器是两个不同的部分,之所以放在同一节里面,是因为这两个东西我们这里都不会说,有兴趣可以自己搜索。
执行计划
正文
下面我们开始扩展篇的学习。首先,让我们深入到数据库服务器的内部,探索一下 SQL 查询的执行过程。
SQL 查询执行过程:
不同数据库对于 SQL 语句的执行过程采用了各自的实现方式;我们虽然不能通过一篇文章涵盖这些实现细节,但是可以尝试概括其中的关键过程和差异之处。简单来说,一个 SQL 查询语句从客户端的提交开始直到服务器返回最终的结果,整个过程大致如下图所示:

第一步:客户端提交 SQL 语句。当然,在此之前客户端必须连接到数据库服务器。在上图中的连接器就是负责建立和管理客户端的连接。
第二步:分析器/解析器。分析器首先解析 SQL 语句,识别出各个组成部分;然后进行语法分析,检查 SQL 语句的语法是否符合规范。例如,以下语句中的 FROM 写成了 FORM:
SELECT *
FORM people
WHERE pk = 1;
-- Oracle
SQL Error [923] [42000]: ORA-00923: FROM keyword not found where expected
-- MySQL
SQL Error [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FORM people
WHERE pk = 1' at line 2
-- SQL Server
SQL Error [102] [S0001]: Incorrect syntax near 'FORM'.
-- PostgreSQL
SQL Error [42601]: ERROR: syntax error at or near "FORM"
Position: 13
数据库返回了一个语法错误。
接下来是语义检查,确认查询中的表或者字段等对象是否存在,用户是否拥有访问权限等。例如,以下语句写错了表名:
SELECT *
FROM ppeople
WHERE pk = 1;
-- Oracle
SQL Error [942] [42000]: ORA-00942: table or view does not exist
-- MySQL
SQL Error [1146] [42S02]: Table 'my_db.ppeople' doesn't exist
-- SQL Server
SQL Error [208] [S0002]: Invalid object name 'ppeople'.
-- PostgreSQL
SQL Error [42P01]: ERROR: relation "ppeople" does not exist
Position: 18
数据库显示对象不存在或者无效。这一步还包括处理语句中的表达式,视图转换等。
第三步:优化器。利用数据库收集到的统计信息决定 SQL 语句的最佳执行方式。例如,使用索引还是全表扫描的方式访问单个表,使用什么顺序连接多个表。优化器是决定查询性能的关键组件,而数据库的统计信息是优化器判断的基础。
第四步:执行器。根据优化之后的执行计划,调用相应的执行模块获取数据,并返回给客户端。对于 MySQL 而言,会根据表的存储引擎调用不同的接口获取数据。PostgreSQL 12 版本开始引入类似的插件存储引擎功能。
以上流程在各种数据库中大体相同,但还有一些重要的组件就是缓存:
- 查询缓存 。MySQL 5.7 之前的版本有一个查询缓存模块,以 key-value 的形式缓存了执行过的查询语句和结果集。但是查询缓存的失效频率非常高;因为只要有任何更新,表上所有的查询缓存都会被清空。因此,MySQL 8.0 版本删除了查询缓存的模块。
- 查询计划缓存。对于完全相同的 SQL 语句,利用已经缓存的执行计划,从而跳过解析和生成执行计划的过程。Oracle 和 SQL Server 都提供了查询计划缓存;MySQL 和 PostgreSQL 的查询计划在使用预编译语句(Prepared Statement )时被缓存,但只在当前会话中有效。
- 数据缓存。对于已经访问过的磁盘数据(表和索引),在缓冲区中进行缓存;下次访问时可以直接读取内存中的数据。数据缓存可以明显提高数据访问的速度,已经成为了各种数据库的标配。
从以上流程可以看出,执行计划是决定查询性能的关键;如果想查看一条语句的执行情况,可以通过explain
小结
一个查询语句大概需要经过分析器、优化器、执行器的处理并返回最终结果,同时还可能利用各种缓存功能提高查询的性能。决定查询性能的主要因素就是执行计划,大多数数据库可以通过 EXPLAIN 命令查看执行计划。理解执行计划是进行查询优化的关键。
了解常见 SQL 查询优化技巧
正文
下面我们来介绍一些常见的查询优化方法和技巧。
首先一点:优化规则千万条,执行计划第一条。不要盲目相信什么规则,包括本文列出的规则;因为数据库优化器在不断改进,许多规则已经或者将来不再适用。不过另一方面,通过执行计划找出性能问题并进行优化的方法不会改变。
一般来说,对于 OLTP 应用减少数据库磁盘 IO 是 SQL 优化需要考虑的首要因素,因为磁盘通常是性能的瓶颈所在。除此之外,还需要考虑降低 CPU 和内存的消耗;DISTINCT、GROUP BY、ORDER BY 等操作都需要涉及大量 CPU 运算,而且还会占用大量内存或者使用临时文件。
创建合适的索引:
索引是优化查询性能的主要方法,因此首先需要考虑创建有效的索引。我们在前面介绍了索引的原理,现在来看看哪些字段适合创建索引:
- 经常出现在 WHERE 条件或者 ORDER BY 中的字段创建索引,可以避免全表扫描和额外的排序操作;
- 多表连接查询的关联字段,外键涉及的字段;
- 查询中的分组操作字段;
创建索引时还有一些注意事项。首先,尽量选择区分度高的列作为索引,例如各种编号;而性别这种重复性高的字段不适合单独创建索引。其次,对于组合索引,查询条件中最常出现的列放在最左边,这个称为组合索引最左前缀原则。
另外,还需要注意有些情况不适合创建索引。例如,频繁更新的字段不适合创建索引,因为更新索引也需要付出代价;表中记录较少时不需要创建索引,直接通过全表扫描可能更快;大文本数据考虑使用全文索引。
避免使用 SELECT *:
SELECT * 表示查询表中的所有字段,这种写法可能返回了不必要的信息,导致性能的下降。因为数据库需要读取更多的数据,同时网络需要传输更多的数据,而且客户端可能并不需要这些信息。
我们在学习过程中为了方便,可以使用星号编写查询语句;但是在实际开发中应该严格控制只返回业务需要的字段
优化查询条件:
虽然我们已经为查询条件中的字段创建了合适的索引,但是如果 WHERE 子句编写不当,同样会导致数据库无法使用索引。
首先,在 WHERE 子句中对索引字段进行表达式运算或者使用函数都会导致索引失效。
比如:我们将email字段作为索引,但是在查询的时候,使用upper(email),那么该索引就会失效
其次,使用 LIKE 匹配时,如果通配符出现在左侧无法使用索引,因为不确定左边的起始字符是什么、以及有多少个。
另外,如果 WHERE 条件中的字段上创建了索引,尽量设置为 NOT NULL。不是所有数据库使用 IS [NOT] NULL 判断时都可以利用索引
多表连接实现:
连接查询首先需要避免缺少连接条件导致的笛卡尔积,这是非常消耗资源的操作。对于 JOIN 查询使用的关联字段,应该确保数据类型和字符集相同,并且创建了合适的索引。
对于多表连接查询,数据库底层的实现方式通常有三种:
- 嵌套循环连接(Nested Loop Join),针对驱动表(外表)中的每条记录,遍历另一个表找到匹配的数据,相当于两层 for 循环。
- 哈希连接(Hash Join),将一个表的连接字段计算出一个哈希表,然后从另一个表中一次获取记录并计算哈希值,根据两个哈希值来匹配符合条件的记录。
- 排序合并连接( Sort Merge Join),先将两个表中的数据基于连接字段分别进行排序,然后合并排序后的结果。
数据库优化器选择哪种方式取决于许多因素,例如表中的数据量、关联字段是否已经排序或者创建索引等:
- Nested Loop Join 适用于驱动表数据比较少,并且连接表中有索引的时候;
- Hash Join 对于数据量大,且没有索引的情况下可能性能更好;
- Sort Merge Join 通常用于没有索引,并且数据已经排序的情况。
一般连接查询的表较少时,优化器可以自行选择合适的实现方法;当复杂查询性能不够理想时,我们可以通过执行计划查看是否缺少索引、调整多表连接的顺序等方式进行优化。
另外,还有一种减少连接查询的方法,就是增加冗余字段,利用空间换时间。
除此之外还可以优化子查询、优化union、优化分页查询等等。
小结
SQL 优化本质上是了解优化器的的工作原理,并且为此创建合适的索引和正确的语句。当优化器由于自身的限制无法进一步优化时,我们可以人为进行查询的重写,共同实现查询的优化。另外我们还需要知道,SQL 优化只是数据库性能优化的一部分;相关的技术还包括表结构优化、配置参数优化、操作系统和硬件调整,甚至架构优化(分库分表、读写分离等)。
全文总结
如果你看到了这里,那么恭喜你完成了从初级查询到高级分析功能、从增删改查到数据库设计、从性能优化到应用开发等相关知识的学习。我们最后再总结一些
再谈关系:
最开始我们介绍了 SQL 编程中的一个最重要思想:一切都是关系。关系在数据库中实现为二维表,由数量固定的列和任意数量的行组成;所以,关系表可以看作是一个由元素(数据行)构成的集合。而 SQL 语言本质上是为关系表提供的各种操作,我们可以将以上内容汇总如下:
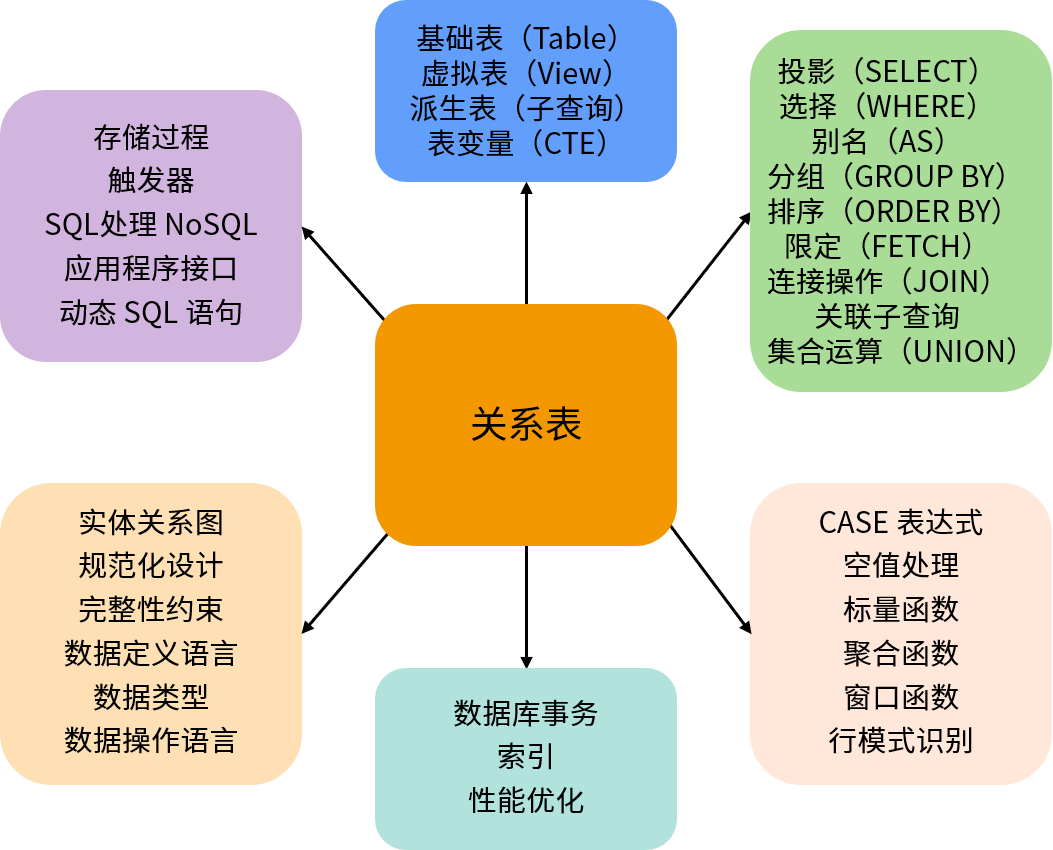
首先,关系表在数据库中存在几种不同的表现形式:
- 基础表(Table)是数据库中存储数据的主要对象;
- 视图(View)是一个命名的查询语句。视图不存储数据,但是经常当作表来使用,因此被称为虚拟表;
- 查询的结果集被称为派生表(Derived Table);
- 通用表表达式(CTE)是语句级别的临时表,也称为表变量。
数据库中还有一种表叫做临时表(temporary table)。根据定义的不同,临时表会在事务结束或者会话终止时被自动清空或者删除。
接下来就是主要内容,也就是实现了各种关系操作的 SQL 语言。SQL 是一种面向集合(关系表)的声明式语言,操作的对象和结果都是集合。我们来看一个 PostgreSQL 中的示例:
-- PostgreSQL
SELECT * FROM abs(-1); -- 1
学习了 SQL 之后,我们应该都知道 FROM 子句指定的是一个表;而 abs 是求绝对值的函数,所以在 PostgreSQL 中甚至函数的结果都是一个表。
伟大的设计通常都体现了简单的哲学思想,就像在 Unix/Linux 中一切皆文件一样,在 SQL 中一切皆关系。
除此之外,我们还详细介绍了关系操作中的投影(SELECT)、选择(WHERE)、别名(AS)、分组(GROUP BY)、排序(ORDER BY)、限定(FETCH/LIMIT)、集合操作(UNION、INTERSECT 和 EXCEPT)、连接操作(INNER/LEFT/RIGHT/FULL JOIN、CROSS JOIN)以及子查询等。当我们使用这些操作组合成一个复杂的 SQL 语句时,需要注意它们的编写顺序和逻辑执行顺序。
SQL 执行顺序:
回顾一下我们学习过的 SQL 查询语句:
(6)SELECT [DISTINCT | ALL] col1, col2, agg_func(col3) AS alias
(1) FROM t1 JOIN t2
(2) ON (join_conditions)
(3) WHERE where_conditions
(4) GROUP BY col1, col2
(5)HAVING having_condition
(7) UNION [ALL]
...
(8) ORDER BY col1 ASC,col2 DESC
(9)OFFSET m LIMIT N;
以上是 SQL 中各种关键字的编写顺序,前面括号内的数字代表了它们的逻辑执行顺序。也就是说,SQL 并不是按照编写顺序先执行 SELECT,然后再执行 FROM 子句。从逻辑上讲,SQL 语句的执行顺序如下:
- 首先,FROM 和 JOIN 是 SQL 语句执行的第一步。它们的逻辑结果是一个笛卡尔积,决定了接下来要操作的数据集。注意逻辑执行顺序并不代表物理执行顺序,实际上数据库在获取表中的数据之前会使用 ON 和 WHERE 过滤条件进行优化访问;
- 其次,应用 ON 条件对上一步的结果进行过滤并生成新的数据集;
- 然后,执行 WHERE 子句对上一步的数据集再次进行过滤。WHERE 和 ON 大多数情况下的效果相同,但是外连接查询有所区别,我们将会在下文给出示例;
- 接着,基于 GROUP BY 子句指定的表达式进行分组;同时,对于每个分组计算聚合函数 agg_func 的结果。经过 GROUP BY 处理之后,数据集的结构就发生了变化,只保留了分组字段和聚合函数的结果;
- 如果存在 GROUP BY 子句,可以利用 HAVING 针对分组后的结果进一步进行过滤,通常是针对聚合函数的结果进行过滤;
- 接下来,SELECT 可以指定要返回的列;如果指定了 DISTINCT 关键字,需要对结果集进行去重操作。另外还会为指定了 AS 的字段生成别名;
- 如果还有集合操作符(UNION、INTERSECT、EXCEPT)和其他的 SELECT 语句,执行该查询并且合并两个结果集。对于集合操作中的多个 SELECT 语句,数据库通常可以支持并发执行;
- 然后,应用 ORDER BY 子句对结果进行排序。如果存在 GROUP BY 子句或者 DISTINCT 关键字,只能使用分组字段和聚合函数进行排序;否则,可以使用 FROM 和 JOIN 表中的任何字段排序;
- 最后,OFFSET 和 FETCH(LIMIT、TOP)限定了最终返回的行数。
理解 SQL 的逻辑执行顺序可以帮助我们避免一些常见的错误,例如以下语句:
-- 错误示例
SELECT emp_name AS empname
FROM employee
WHERE empname ='张飞';
该语句的错误在于 WHERE 条件中引用了列别名;从上面的逻辑顺序可以看出,执行 WHERE 条件时还没有执行 SELECT 子句,也就没有生成字段的别名。
另外一个需要注意的操作就是 GROUP BY
-- GROUP BY 错误示例
select saledate, product, sum(amount)
from sales_data group by saledate
由于经过 GROUP BY 处理之后结果集只保留了分组字段和聚合函数的结果,示例中的 product 字段已经不存在;如果需要同时显示product和saledate,可以使用窗口函数。
如果使用了 GROUP BY 分组,之后的 SELECT、ORDER BY 等只能引用分组字段或者聚合函数;不分组,则可以引用 FROM 和 JOIN 表中的任何字段。
还有一些逻辑问题可能不会直接导致查询出错,但是会返回不正确的结果;例如外连接查询中的 ON 和 WHERE 条件。以下是一个左外连接查询的示例:
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id)
WHERE e.emp_name ='张飞';
/*
张飞 行政管理部
*/
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id AND e.emp_name ='张飞');
/*
刘备 NULL
关羽 NULL
张飞 行政管理部
诸葛亮 NULL
*/
第一个查询在 ON 子句中指定了连接的条件,同时通过 WHERE 子句找出了“张飞”的信息。
第二个查询将所有的过滤条件都放在 ON 子句中,结果返回了所有的员工信息。这是因为左外连接会返回左表中的全部数据,即使 ON 子句中指定了员工姓名也不会生效;而 WHERE 条件在逻辑上是对连接操作之后的结果进行过滤。
除此之外,了解 SQL 逻辑执行顺序也可以帮助我们进行 SQL 优化。例如 WHERE 子句在 HAVING 子句之前执行,因此我们应该尽量使用 WHERE 进行数据过滤,避免无谓的操作;除非业务需要针对聚合函数的结果进行过滤。
数据分析功能:
SQL 作为一种数据领域的专用语言,必然支持数据分析所需的各种功能:
- CASE 表达式可以为 SQL 语句提供逻辑处理的能力,理论上来说可以实现任意复杂的处理逻辑;
- 空值(NULL)代表了缺失的数据,空值处理是数据分析中的常见问题;
- 函数通常为我们提供了某种功能, SQL 中的各种内置标量函数提高了我们处理数据的效率;
- 聚合函数与分组操作相结合可以实现数据的汇总和多维度分析报表;
- 窗口函数可以进一步完成累计分析、移动分析以及分类排名等复杂的报表需求;
- 行模式识别(MATCH_RECOGNIZE)可以用于分析各种数据流,例如股票行情数据分析、金融欺诈检测等。
数据库设计与应用开发:
数据库设计通常遵循一定的流程,其中 ER 图和规范化是两种常用的技术。设计关系模式时需要考虑字段类型的选择和完整性约束问题,最终我们可以使用 DDL 语句创建表和索引等对象,同时利用 DML 语句对表中的数据执行增删改合操作。
数据库事务是一组业务逻辑上的操作单元,具有 ACID 属性。隔离可以确保数据的一致性,但是会影响并发处理的能力。与数据库性能相关的一个重要对象是索引,合理利用索引和一些查询技巧通常可以优化 SQL 语句的性能,与此相关的一个重要的概念就是执行计划。
除了声明式的 SQL 语句之外,数据库还提供了服务器端的编程功能,例如存储过程和触发器。应用程序也可以通过驱动连接数据库,执行各种数据操作;为了防止动态语句可能带来的 SQL 注入问题,我们应该使用参数化或者带绑定变量的预编译语句。
另外,关系数据库对 JSON 文档的支持使得我们可以同时获得SQL 的强大功能和事务支持(ACID)以及 NoSQL 的灵活性和高性能。
到这里就结束了,当然还有不少本文没有说的,但是对于日常工作来说应该是差不多了。至于更高深的内容,可以工作中慢慢积累,或者网上搜索、寻找其他的教程。总而言之,SQL是很强大的,不要觉得SQL没什么东西,如果把SQL学好了,其实是件非常了不起的事情。加油,老铁们。
最后以我女神的照片作为结束吧
