print函数原型
print这个函数应该是用的最多的一个函数了,但是这个函数的所有用法你都了然于心吗?我们先来看看print函数的结构。
def print(self, *args, sep=' ', end='
', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='
', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
"""
pass
*args:表示我们要打印的内容,是一个可变参数。sep:分隔符,对打印的多个元素进行分隔,默认是空格end:我们print打印的时候,会自动换行,就是因为这里的file:输出位置,默认是输出到sys.stdoutflush:是否及时刷新到缓冲区。
演示
我们来修改一下里面的参数,来看看打印会有什么不同的结果。
sep
# 我们看到打印的三个数字是以空格分开的,就是因为sep=' '
print(1, 2, 3) # 1 2 3
# 我们修改一下,可以看到此时就是我们指定的分割符了
print(1, 2, 3, sep='>>>') # 1>>>2>>>3
end
print(1, 2, 3)
print(4, 5, 6)
"""
1 2 3
4 5 6
"""
# 我们看到上面的两个print打印的时候,是位于不同的行
# 就是因为python中的print在打印之后会自动在结尾加上一个换行符,也就是end='
',使得光标停在下一行
# 像在C语言中,由于printf不会自动加上换行符,所以会需要手动加上
# 我们这里修改一下,也把sep加上去。而我们的end已经被改为了@@@
print(1, 2, 3, sep='>>>', end='@@@')
print(4, 5, 6)
print(7, 8, 9)
"""
1>>>2>>>3@@@4 5 6
7 8 9
"""
# 此时我们看到4 5 6本来应该出现在第二行的,但是第一个print的end不再是
了,而是@@@
# 因此不会再换行了,而是直接在结尾加上一个@@@,光标还是停在当前行,所以第二个print打印就连在一起了
# 但是第二个print我们没有指定end,那么默认还是
,所以第三个print打印还是会在新的行
# 也说明了print之间不会互相影响
file
这里的file表示输出到什么位置,默认是sys.stdout,也就是控制台。
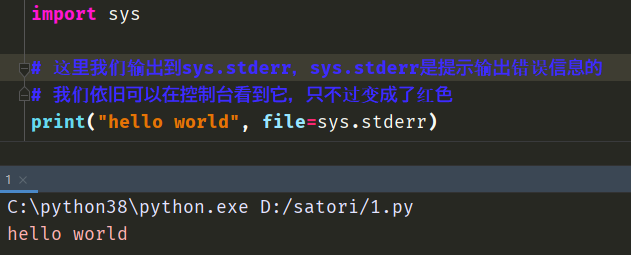
import sys
print("hello1")
print("hello2", file=sys.stderr)
print("hello3")
"""
hello1
hello3
hello2
"""
不过我们看到字符串"hello2"明明是在第二行打印的,但是显示在控制台的时候却出现在了最后。这是因为缓冲区,我们看到里面出现了两个输出位置,一个是默认的sys.stdout,一个是我们单独指定的sys.stderr,不同的输出位置具有不同的缓冲区,所以无法保证哪个先显示。如果多执行即便的话,结果可能还不一样。
import sys
print("hello1")
print("hello2", file=sys.stderr)
print("hello3")
# 此时顺序又变了
"""
hello2
hello1
hello3
"""
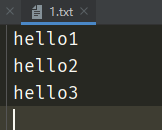
同样的,我们还可以将file指定成文件句柄,那么显然就会把print的内容写到文件里面。注意:因为既然print是写,那么这个文件句柄就必须是可写的。
f = open("1.txt", "a", encoding="utf-8")
print("hello1", file=f)
print("hello2", file=f)
print("hello3", file=f)
# 最后关闭文件
f.close()
此时终端不会有任何输出,但是我们可以看看文件,会发现内容已经写进去了。因此print还可以简单地实现类似于日志的功能。
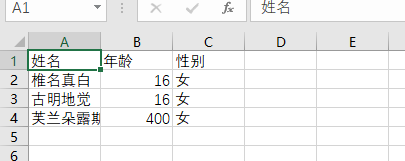
此外我们还可以写成csv文件,csv文件默认是以逗号作为分隔符的。
with open("1.csv", "a", encoding="gbk") as f:
# 字段
print("姓名", "年龄", "性别", sep=",", file=f)
# 内容
print("椎名真白", 16, "女", sep=",", file=f)
print("古明地觉", 16, "女", sep=",", file=f)
print("芙兰朵露斯卡雷特", 400, "女", sep=",", file=f)
flush
flush表示刷新缓冲区,缓冲区不用我介绍了,如果每来一点数据就刷新一次的话,效率会很低。于是会把数据暂时写到缓冲区里面,等缓冲区满了一下子全部刷到终端中。flush默认是False,如果指定为True的话,那么表示不管缓冲区满没满,都强行刷新缓冲区,将里面的内容显示到屏幕上。
print(123)
print(456, flush=True)
print(789)
"""
123
456
789
"""
# 这个不好展示,感受一下即可
