cummax,cummin,cumprod,cumsum
有时候我们需要求出从第一行开始截止到当前行的最大值、最小值,以及实现累乘、累和等等。
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 15, 50, 40]})
# cummax:求出从第一行开始截止到当前行的最大值
# 第1行为10,第2行为20,第3行为15但是比20小所以还是20,第4行为50,同理第5行也是50
print(df["a"].cummax())
"""
0 10
1 20
2 20
3 50
4 50
Name: a, dtype: int64
"""
# 这个不需要解释了
print(df["a"].cummin())
"""
0 10
1 10
2 10
3 10
4 10
Name: a, dtype: int64
"""
# 对每一行实现累乘
print(df["a"].cumprod())
"""
0 10
1 200
2 3000
3 150000
4 6000000
Name: a, dtype: int64
"""
# 对每一行实现累加
print(df["a"].cumsum())
"""
0 10
1 30
2 45
3 95
4 135
Name: a, dtype: int64
"""
shift:垂直方向移动
import pandas as pd
df = pd.DataFrame({"a": range(1, 10)})
print(df)
"""
a
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
"""
df["b"] = df["a"].shift(1)
df["c"] = df["a"].shift(-1)
print(df)
"""
a b c
0 1 NaN 2.0
1 2 1.0 3.0
2 3 2.0 4.0
3 4 3.0 5.0
4 5 4.0 6.0
5 6 5.0 7.0
6 7 6.0 8.0
7 8 7.0 9.0
8 9 8.0 NaN
"""
我们看到,我们某一列使用shift(n),可以使其达到向上或者向下的平移效果。n大于0,表示向上平移n个单位,n小于0表示向下平移n个单位。既然平移了,那么势必就会出现NaN。
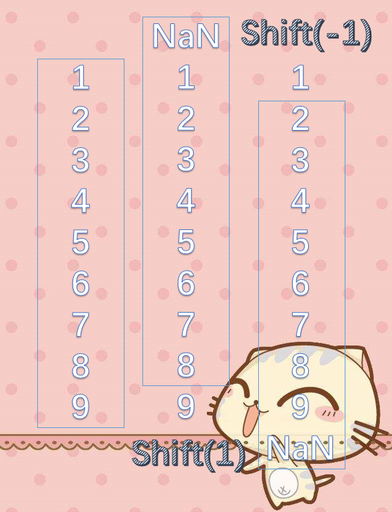
想象一个框,shift(1)表示框向上平移一个长度,那么框住的部分就是新的列。
如果我们有这样一个需求,计算某一列的当前元素和上一个元素的差,该怎么做呢?
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 15, 50, 40]})
print(df["a"] - df["a"].shift(1))
"""
0 NaN
1 10.0
2 -5.0
3 35.0
4 -10.0
Name: a, dtype: float64
"""
diff:垂直方向相减
这个功能我们已经实现了,可以使用shift平移之后手动相减。但是有一个更简便的方法,也就是diff(n),n大于0,表示当前行与前第n行相减,n小于0,表示当前行与后第n行相减。
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 15, 50, 40]})
df["b"] = df["a"].diff(1)
df["c"] = df["a"].diff(-1)
print(df)
"""
a b c
0 10 NaN -10.0
1 20 10.0 5.0
2 15 -5.0 -35.0
3 50 35.0 10.0
4 40 -10.0 NaN
"""
pct_change:垂直方向相减求比例
和diff(n)比较类似,但是在diff(n)基础之上又做了一层操作。就是减完了之后,用差再除以原来减去的值。
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 15, 50, 40]})
df["b"] = df["a"].diff(1)
df["b_pct"] = df["a"].pct_change(1)
df["c"] = df["a"].diff(-1)
df["c_pct"] = df["a"].pct_change(-1)
print(df)
"""
a b b_pct c c_pct
0 10 NaN NaN -10.0 -0.500000
1 20 10.0 1.000000 5.0 0.333333
2 15 -5.0 -0.250000 -35.0 -0.700000
3 50 35.0 2.333333 10.0 0.250000
4 40 -10.0 -0.200000 NaN NaN
"""
cut:分箱技术
有时候,我们需要对数据进行分类。比如考生成绩,凡是小于60的归类为不及格,大于等于60小于80的为不错,大于等于80小于等于100为优秀
import pandas as pd
df = pd.DataFrame({"a": [60, 50, 80, 96, 75]})
# bins:为一个数组,从小到大。
df["b"] = pd.cut(df["a"], bins=[0, 59, 79, 100])
# 还可以指定labels,注意:len(labels) == len(bins) - 1,因为bins如果有n个元素,那么会形成n-1个区间
df["c"] = pd.cut(df["a"], bins=[0, 59, 79, 100], labels=["不及格", "不错", "优秀"])
print(df)
"""
a b c
0 60 (59, 79] 不错
1 50 (0, 59] 不及格
2 80 (79, 100] 优秀
3 96 (79, 100] 优秀
4 75 (59, 79] 不错
"""
我们注意到:区间是左开右闭的,如果需要把右边也改成开区间,那么加上right=False即可,默认是为True
rolling:窗口函数
假设我们有一年的历史数据,我们需要对每8天求一次平均值该怎么做呢?比如:第一行是1~8天的平均值,第二行是2~9天的平均值,第三行是3~10天的平均值。
import pandas as pd
df = pd.DataFrame({"a": [10, 20, 10, 60, 40, 20, 50]})
# 调用rolling(n)方法等于每n行开了一个窗口,然后对相应的窗口里面的数据进行操作。
# 然后就可以使用window求平均值了
# 这个n必须要大于0,否则报错
window = df["a"].rolling(2)
# 我们说n大于0是往上,为2的话表示每一行往上数,加上本身数两行,然后对这两行求平均。所以第一行就是NaN了,因为上面没有了。
print(window.mean())
"""
0 NaN
1 15.0
2 15.0
3 35.0
4 50.0
5 30.0
6 35.0
Name: a, dtype: float64
"""
# 同理n=3,表示往上数3行
# 那么第1行和第2行都会为NaN
print(df["a"].rolling(3).mean())
"""
0 NaN
1 NaN
2 13.333333
3 30.000000
4 36.666667
5 40.000000
6 36.666667
Name: a, dtype: float64
"""
# 当然不光可以求平均值,还可以求最大值,最小值,求和等等
df["b"] = df["a"].rolling(2).max()
df["c"] = df["a"].rolling(2).min()
df["d"] = df["a"].rolling(2).sum()
print(df)
"""
a b c d
0 10 NaN NaN NaN
1 20 20.0 10.0 30.0
2 10 20.0 10.0 30.0
3 60 60.0 10.0 70.0
4 40 60.0 40.0 100.0
5 20 40.0 20.0 60.0
6 50 50.0 20.0 70.0
"""
# 甚至还可以自定义函数
df["e"] = df["a"].rolling(2).sum()
# 每一个窗口可以理解为一个Series,df["a"].rolling(2).sum()等价于df["a"].rolling(2).agg("sum")
# 我们再单独加上一个1
df["f"] = df["a"].rolling(2).agg(lambda x: sum(x) + 1)
print(df[["e", "f"]])
"""
e f
0 NaN NaN
1 30.0 31.0
2 30.0 31.0
3 70.0 71.0
4 100.0 101.0
5 60.0 61.0
6 70.0 71.0
"""
# 如果n=1,那么就是本身了
# 不管调用什么方法,都是它本身, 因为只有窗口大小为1
print((df["a"].rolling(1).sum() == df["a"].rolling(1).min()).all()) # True