hbase简介
hbase定义
hbase是一种分布式、可扩展、支持海量数据存储的NoSql数据库,可以对几十亿条数据进行秒级查询。
hbase数据模型
逻辑上,hbase的数据模型和关系型数据库比较类似,数据存在一张表中,有行有列。但是从hbase的底层物理存储逻辑来看,hbase更像是一个multi-dimensional map,多维度map,因为hbase是通过key-value形式存储数据的。
逻辑结构

我们说,hbase在逻辑上和关系型数据库比较类似,但又不完全一样。我们发现有一个Row Key,这个就类似于数据库里面的主键一样,是hbase自带的,而它的排序则是按位比较字符串来排序的。然后name age等字段则是相当于数据库中的列,但是我们发现上面还有一个personal_info,这个叫做列簇,就是把具有多个列组合在一起。比如name age gender都是与个人信息有关的,所以我们将其组合在一起,起名为personal_info,where phone起名为address_info,表示如何找到某人。
而且我们发现这几部分是没有连在一起的,而是被切割的四分五裂(好吓人),这每一块就是一个store,在底层每一个部分都是单独存储在hdfs中的。而且hdfs中存储的是每一个store,至于name、age这些是属于元信息,就类似于hive一样。为什么这么做,是因为如果一张表很大,那么我们是需要进行切割的。如果是行多,那么这就类似于数据库中的高表,我们需要水平切割,那么在hbase中,水平切割之后的每一个部分就叫做一个region,因此可以把region看成是一张表的切片,而且是横向的切片;如果列多,那么这类似于数据库的宽表,比较胖嘛,我们需要垂直切割,那么在hbase中,就是划分为不同的列簇。之所以这么做是因为可以加速查询的速度,就类似于hive的分区。至于图中的整体,显然就是一张大表啦。
物理结构
尽管逻辑上,可以看成是类似于数据库中的表,但是我们知道底层不是这么存储的,那么在hbase的底层是如何存储数据的呢?

我们发现逻辑结构中的一行,在物理结构中对应多行。从存储的数据来观察,我们也知道物理结构中的字段代表着什么含义,但是我们发现只是多了两个,一个是timestamp,一个是type。这个timestamp对于hbase来说非常重要,hbase实现对hdfs的随机读写完全依赖这个timestamp,不仅如此,当我们对数据进行修改的时候,实际上是put一条数据,所以我们看到当我们将gender字段对应的女修改为female的时候,并不是将原来的数据给删除掉,而是新增一条数据。可如果这样的话,那当我们返回数据返回哪一个呢?或者说如何返回我们修改之后的数据呢?这时候timestamp就又出场了,因为后修改对应的timestamp肯定会更大,返回的时候直接把timestamp值大的记录返回回去就可以了。之所以这么做的原因就是,如果立即修改,那么hbase的速率肯定不会那么高,所以采用了这种方式,至于修改之前的数据要不要删,肯定是要删除的。
除了timestamp还有一个type,假设我们要删除一条数据,hbase是怎么做的呢?会将type字段中,put改为delete,如果delete的timestamp比put的timestamp大,那么就不返回数据。比如:我们将t2对应的Type修改为Delete,那么t3和t4对应的记录依旧是可以看到的,但是如果在最下面出现了t5,并且Type是Delete,那么数据就看不到了。但还是那句话,hbase并不是立刻就对hdfs上的数据进行删除操作的,只是说你用hbase访问的时候看不到,具体操作后面会继续说。
数据模型
-
name space命名空间,类似于关系型数据库中的database概念,每个命名空间下有多个表。hbase有两个自带的命名空间,分别是hbase和default。hbase空间中存放的是hbase自带的表,default空间则是让用户使用的,可以存放自己定义的表。
-
region类似于关系型数据库表的概念,因为我们刚创建一张表的时候不可能上来就进行切分,只有等数据量大了之后才会进行切分,那么此时一张表就是一个region。但不同的是,hbase定义表的时候只需要声明列簇即可,不需要声明具体指定的列。这意味着,往hbase写入数据时,字段可以动态按需指定。因此和关系型数据库相比,hbase能够轻松应付字段变更的场景。
-
rowhbase表中的每行数据都由一个
RowKey和多个Column组成,数据是按照RowKey的字段顺序进行存储的,并且查询的时候只能根据RowKey进行检索,所以RowKey的设计十分重要, -
columnhbase中的每个列都由
column family,列簇和column qualifier,列限定符进行限定,例如info:name,info:age。建表时,只需要指明列簇,而列限定符则无需预先定义 -
timestamp用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值写入hbase的时间
-
cell由
{rowkey,column family,column qualifier,timestamp}确定的唯一单元,cell中的数据是没有类型的,全部是字节码形式存储。
hbase基础架构
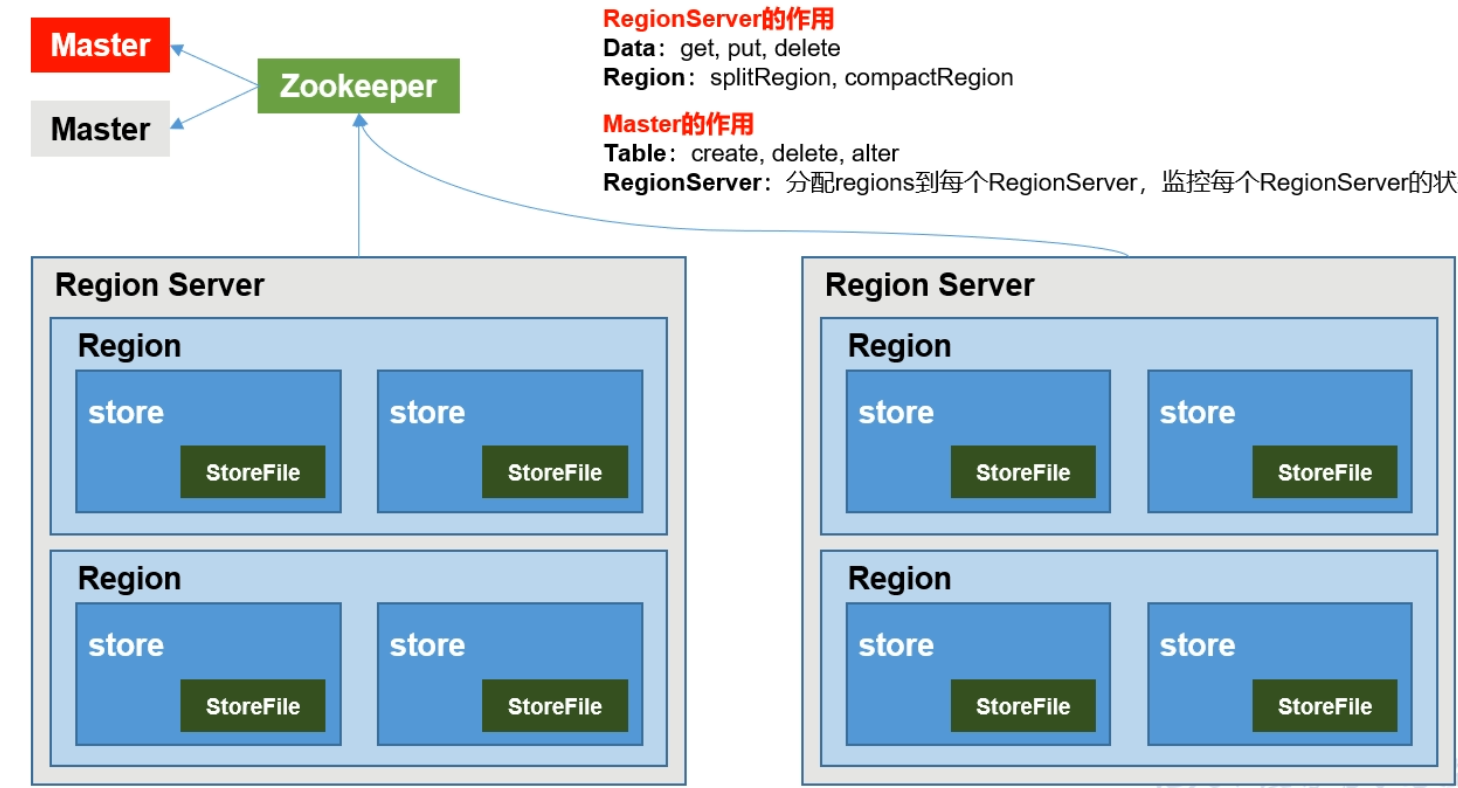
架构角色
-
region serverregion server为region的管理者,主要作用是:1.
对数据的操作:get、put、delete;2.对region的操作:splitRegion(切分),compactRegion(合并)。 -
mastermaster是所有region server的管理者,主要作用是:1.
对于表的操作:create、delete、alter;2.对于region server的操作:分配每个region到每个region server,监控每个region server的状态、负载均衡和故障转移。所以region server是管理每一个region的,控制region的切分和合并。而master是管理region server的,分配region给region server管理。还有就是region server针对的是数据,master针对的是表,可以认为master的级别更高一些。 -
zookeeperhbase是通过zookeeper来做master的高可用、region server监控、元数据的入口以及集群配置的维护工作,这些信息是要写到zookeeper里面的,然后从zookeeper里面读。
-
hdfshdfs为hbase提供最终的底层数据存储服务,同时为hbase提供高可用的支持
hbase安装
我们说hbase依赖于zookeeper、hdfs,那么是不是要先安装这两个呢?当然jdk也是必须的,至于安装的过程我不想多说了,像是zookeeper、hdfs(hadoop),我的其他博客都已经说过了。其实这些大数据组件安装都很简单,直接去官网上下载tar.gz包(官网基本上都是Apache),然后解压将里面的bin目录配置到环境变量即可。所以就不演示了,我的所有大数据组件都安装在/opt目录下,另外希望都在linux上运行,Windows这里就不介绍了。
我们来看一下配置文件,进入到conf目录下面

如果熟悉hadoop的话,那么里面的hbase两个配置文件:hbase-env.sh和hbase-site.xml应该不会陌生,一个是修改环境的,一个是修改配置的。最下面还有一个regionservers,这个就类似与hadoop的slaves,是用来配置集群的,直接写上主机名即可。
修改hbase-env.sh
# The java implementation to use. Java 1.7+ required.
# export JAVA_HOME=/usr/java/jdk1.6.0/
将上面的注释取消,并把JAVA_HOME改成你安装的jdk的路径
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
我们通过注释发现,如果的jdk是1.8以上,那么这两行代码可以删除,当然不删除也可以,只是启动的时候会弹出警告,比较不爽
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
# export HBASE_MANAGES_ZK=true
这个就类似于kafka一样,有一个自己自带的zookeeper,但是我们不会使用自带的,而是使用Apache的zookeeper
# 所以我们要把注释取消,并把true改成false,表示禁用自带zookeeper
修改hbase-site.xml
<property>
<name>hbase:rootdir</name>
<!-- 这里我是伪分布式,所以是localhost,如果是真正的分布式,要写主机名 -->
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<!-- 伪分布式,是false。分布式需要改成true -->
<value>false</value>
</property>
<property>
<name>hbase.master.port</name>
<!-- 0.98版本之后提供的,之前是默认端口60000,现在是16000。这个是master的端口 -->
<value>16000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<!-- 类似于hdfs的50070,这是通过web ui来访问的接口,默认是16010。这个和master的端口可以不用配,使用默认的就行 -->
<value>16010</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<!-- zookeeper所在的主机,多个主机之间使用逗号分隔 -->
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<!-- zookeeper端口,默认的2181被占用了,我们改成2182 -->
<value>2182</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<!-- zookeeper存储数据的地方 -->
<value>/opt/zookeeper/apache-zookeeper-3.5.6-bin/zkData</value>
</property>
hbase的启动和关闭
毫无疑问,与启动和关闭有关的文件都在bin目录下,我们来看一看。首先里面既有cmd,又有sh,cmd是与Windows相关的,我们直接删掉,就不用看了。

我们先来看看标记红色箭头的几个sh文件
hbase:启动命令行操作的,直接启动一个shell。hbase-daemon.sh:启动单节点hbase,就类似于hadoop中的hdfs-daemon.shstart-hbase.sh:启动hbase集群stop-hbase.sh:关闭hbase集群
下面来启动单节点hbase

我们看到就连启动之后的日志,和hadoop都是类似的。我们这里启动了master,那么可以直接通过web ui来查看,还记得端口吗?对,是16010,那个16000是服务端口,16010才是web端口