1.概述
zookeeper是一个开源的、分布式的、为分布式应用提供协调服务的Apache项目
zookeeper的工作机制
zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者,一旦这些数据的状态发生变化,zookeeper就通知已经在zookeeper上注册的那些观察者做出反应
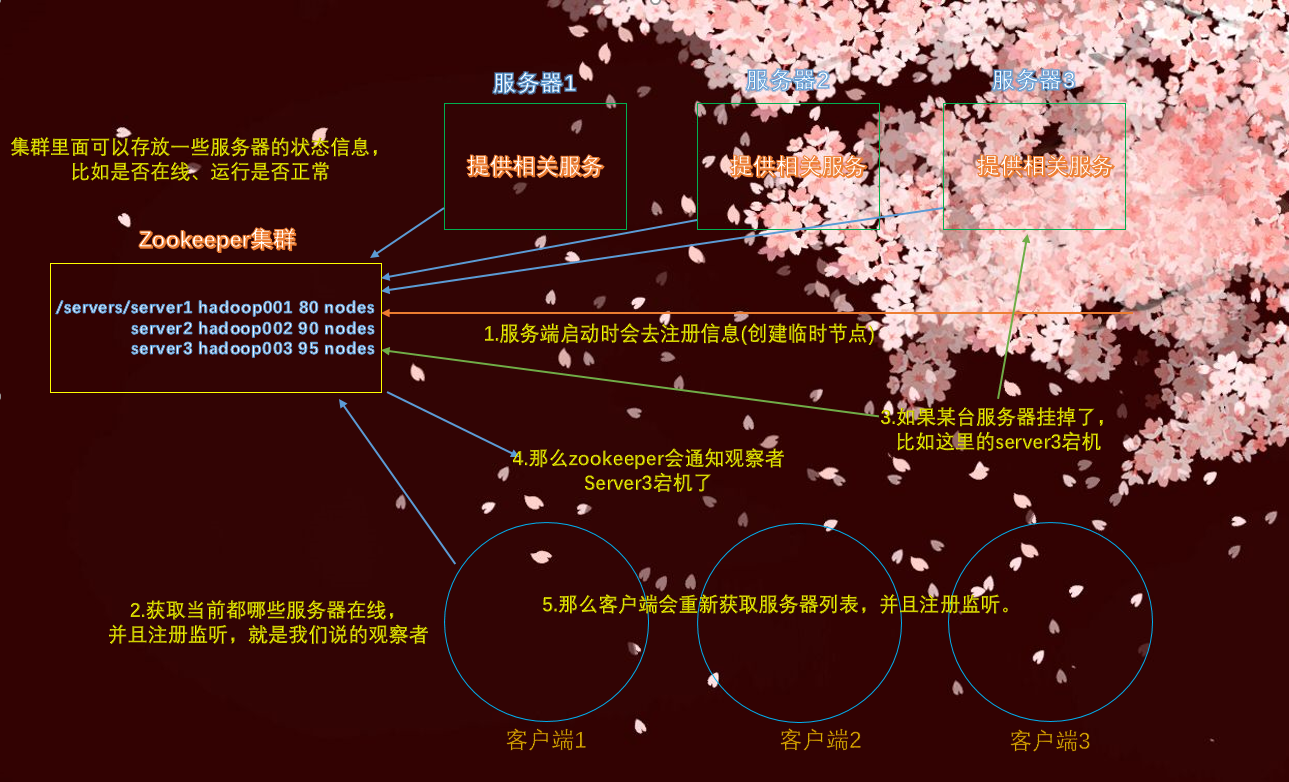
所以zookeeper可以看做是文件系统 + 通知机制。文件系统指的是zookeeper集群可以存储数据,尽管存的数据比较少,但还是像文件一样可以存储的。通知机制指的是当节点有变化,会立即通知观察者
当然zookeeper远没有这么简单,只是先有一个大概的印象即可。
2.特点

- zookeeper:一个领导者
(leader),多个跟随者(follower)组成的集群 - 集群中只要有半数以上的节点存活,zookeeper集群就能正常服务
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪一个server,数据都是一致的。那这样不会浪费空间吗?其实zookeeper里面存的数据量不是很大,那hadoop还是默认以3副本存储的呢。
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。比如一个client发送了3个请求,那么执行顺序按照发送的顺序执行
- 数据更新具有原子性,一次数据更新要么成功,要么失败。
- 实时性,在一定时间范围内,client能读到最新数据。换句话说就是同步的速度非常快,原因是保存的数据量很小。
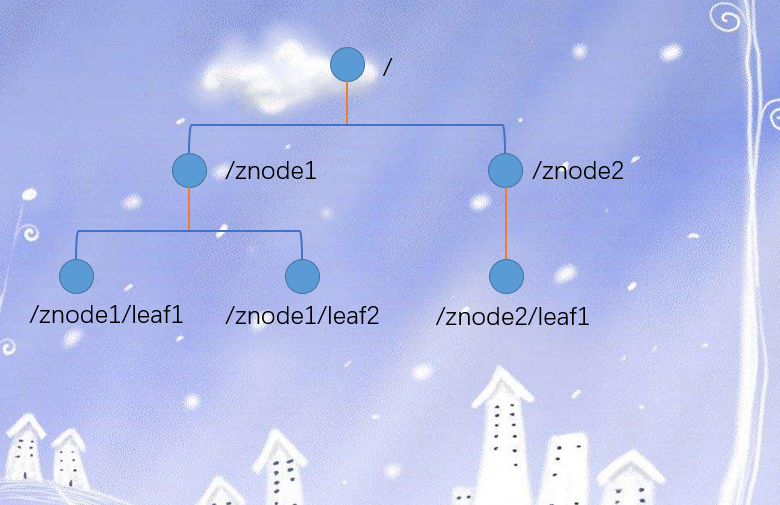
3.数据结构
zookeeper数据模型的结构和unix文件系统很类似,整体上可以看做是一棵树,每个节点称之为一个ZNode。每个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
4.应用场景
在哪些场景下可以使用zookeeper呢?统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等等。下面一个一个介绍。
统一命名服务:
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。例如:IP不容易记住,但是域名容易记住
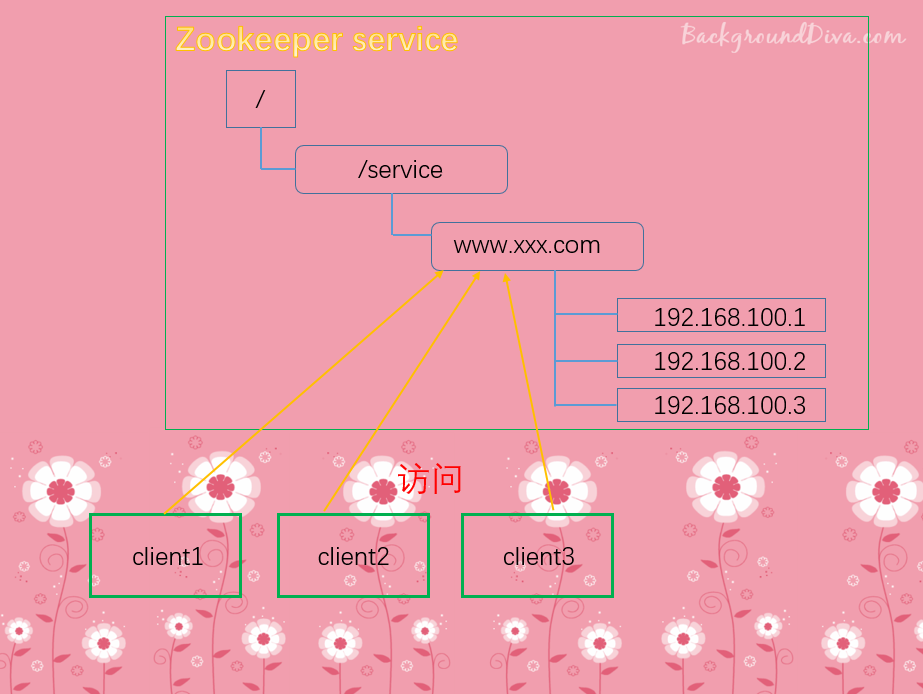
当访问域名的时候,会自动转发到某个服务器当中
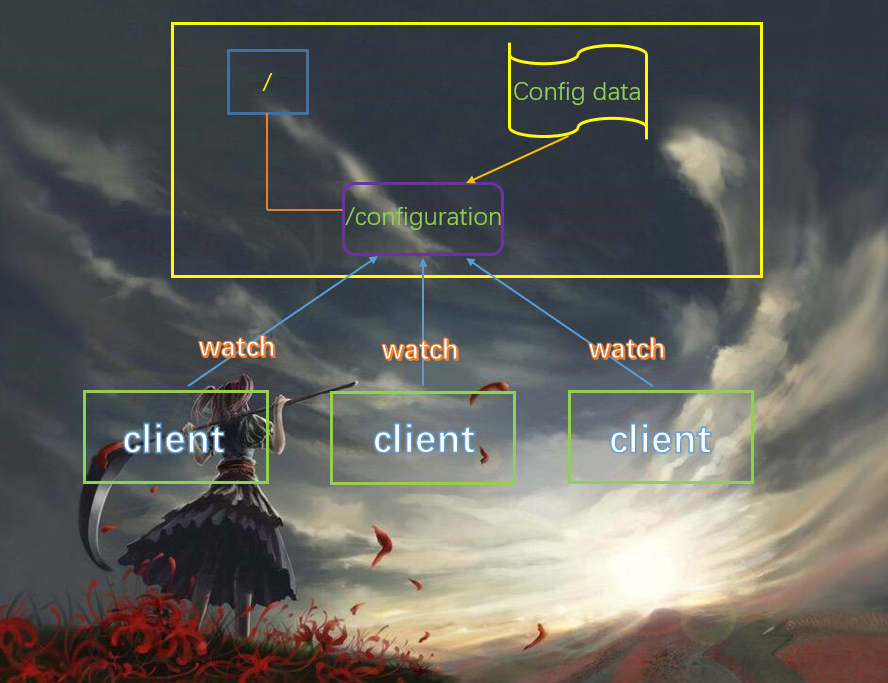
统一配置管理:
- 分布式环境下,配置文件同步非常常见
- 一般要求一个集群中,所有节点的配置信息是一致的。比如kafka集群,当然kafka集群是自带zookeeper的。
- 对配置文件修改之后,希望能够快速同步到各个节点上。
- 配置管理可交由zookeeper实现
- 可将配置信息写入zookeeper上的一个znode
- 各个客户端服务器监听这个znode
- 一旦znode中的数据被修改,zookeeper将通知各个客户端服务器
统一集群管理:
- 分布式环境中,实时掌握每个节点的状态是必要的。
- 可根据节点实时状态做出一些调整
- zookeeper可以实现实时监控节点的变化
- 可将节点信息写入zookeeper上的一个znode。
- 监听这个znode可以获取它的实时状态变化
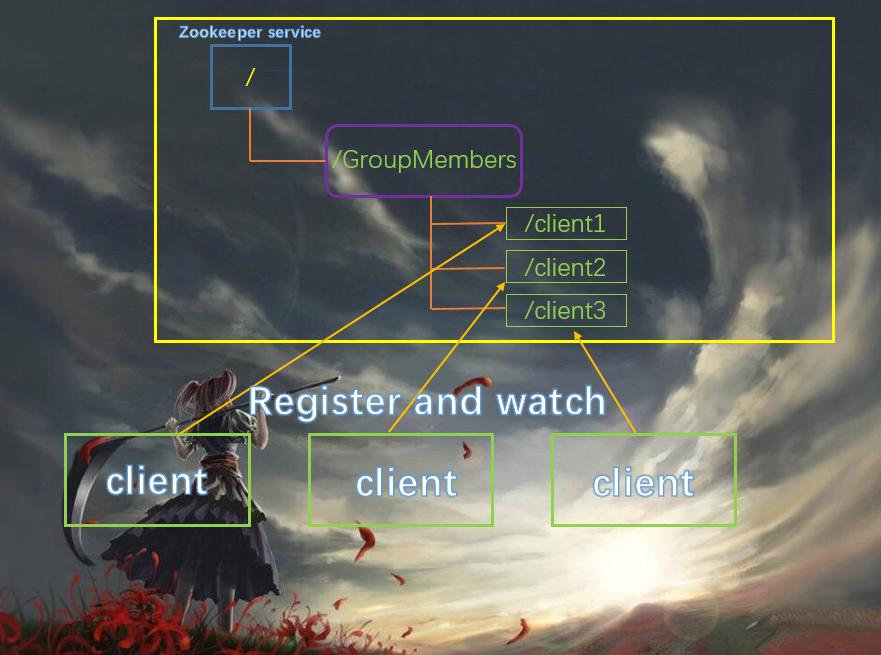
每一个客户端的状态也可以写到节点上面,只要状态发生变化,就会更新节点上客户端的数据,只要数据发生更新,会立刻同步到其他的节点上,从而通知其他的客户端。
服务器动态上下线:
客户端能实时洞察到服务器上线的情况
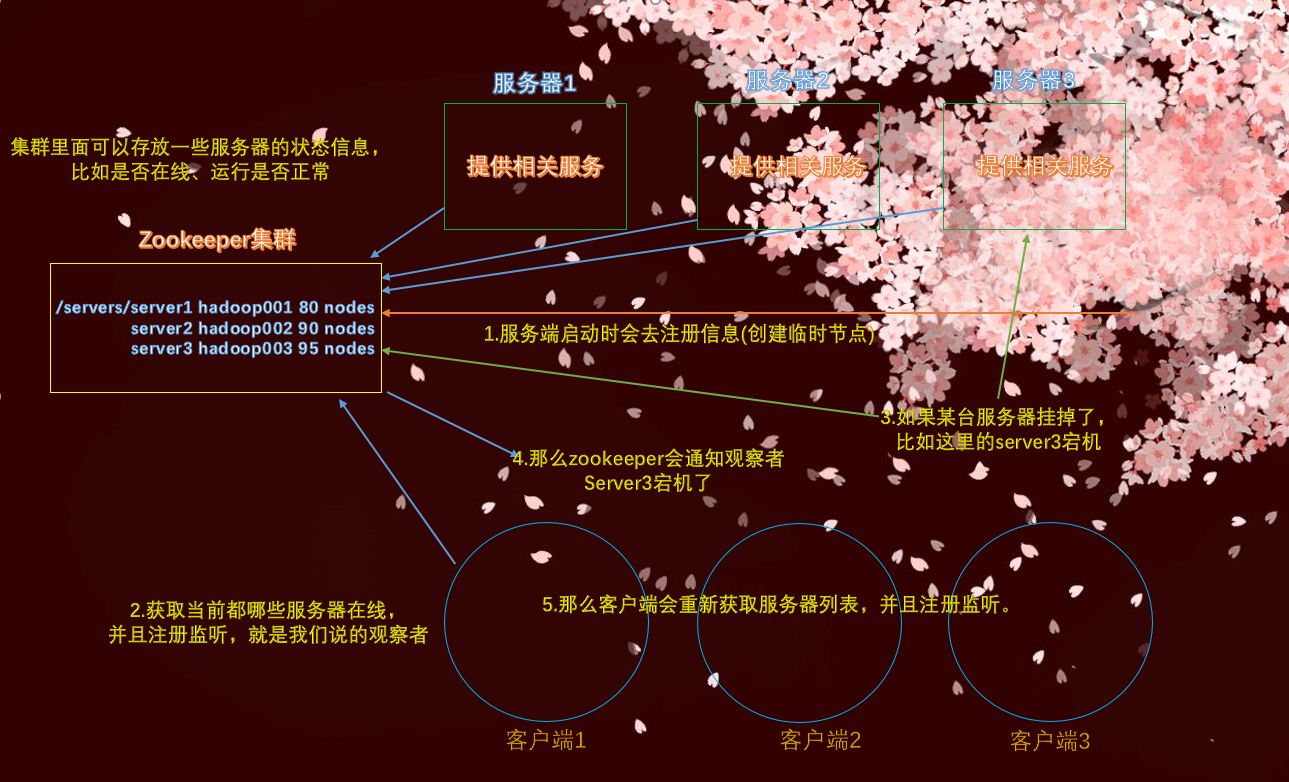
还是最开始的这张图,如果服务器宕机了,比如server3,那么客户端就会被zookeeper通知,那么只会就不会再请求server3了。当然这只是宕机了,如果修好了重新上线呢?那么zookeeper也要通知客户端,再次重新注册监听,会继续访问server3,毕竟修好了嘛
软负载均衡:
在zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求。
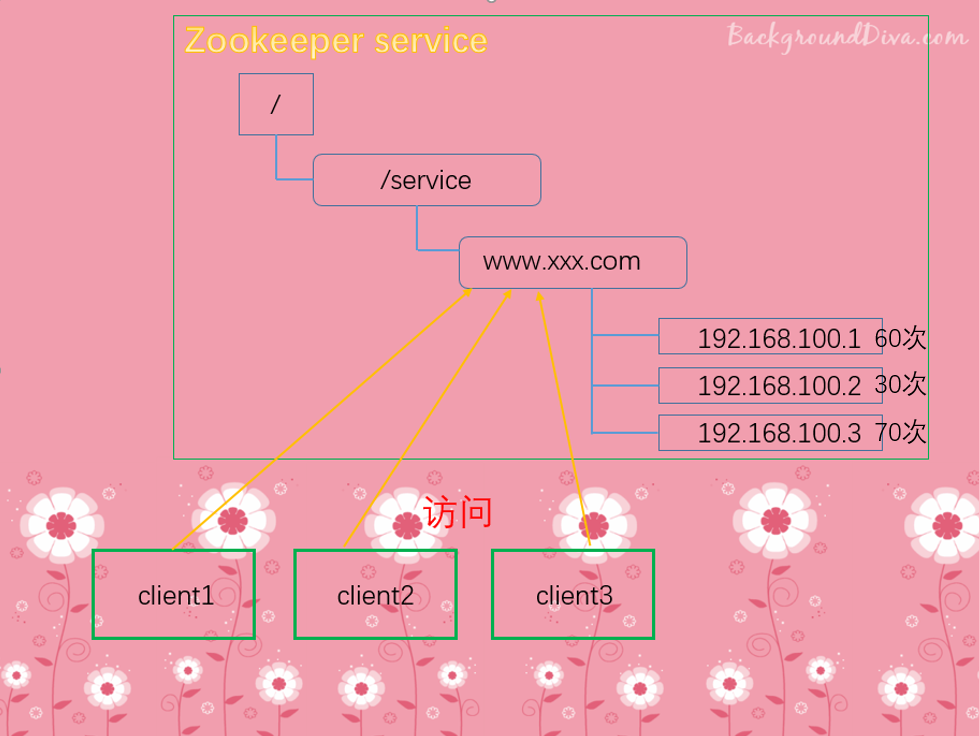
当新的客户端来访问的时候,会自动分发到访问次数比较少的服务器上。也就是类似Nginx的负载均衡的效果,让每一台服务器的压力都不会那么大。
5.下载
zookeeper是Apache的一个顶级项目,所以域名是zookeeper.apache.org,所有Apache的顶级项目的官网都是以项目名.apache.org来命名的,比如hadoop就是hadoop.apache.org,flume就是flume.apache.org
6.本地安装
本地安装,一般都是测试使用,因为实际生产中肯定使用zookeeper集群,目前我们先看看本地怎么安装。
zookeeper是java语言写的,所以需要安装jdk,一般jdk采用1.8版本的即可。我这里已经安装好了

安装zookeeper和安装jdk一样简单,直接解压,然后配置环境变量,source一下即可。我所有的包都安装在了/opt目录下面,当然我现在使用的zookeeper是3.4.14版本的
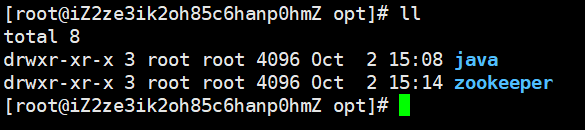
下面配置一下环境变量
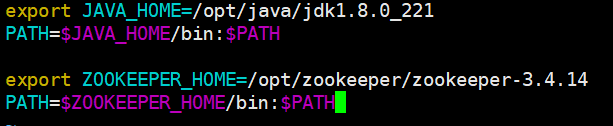
linux上能配置环境变量的地方有很多,我这里选的是~/.bashrc,配置完了之后source一下
修改配置:
我们安装完毕之后不能直接使用,需要修改一下配置。首先将/opt/zookeeper/zookeeper-3.4.14/conf目录下的zoo_sample.cfg修改为zoo.cfg,直接mv zoo_sample.cfg zoo.cfg即可
然后打开zoo.cfg文件,修改为dataDir=/opt/zookeeper/zookeeper-3.4.14/zkData,主要是为了持久化数据,类似于hadoop一样,不然重启之后数据就没了。由于这个目录是我们自己的,是不存在的,所以还要在/opt/zookeeper/zookeeper-3.4.14下mkdir zkData,当然hadoop的话会自动创建,至于zookeeper需要我们手动创建,当然也可以不叫zkData,叫什么都无所谓。
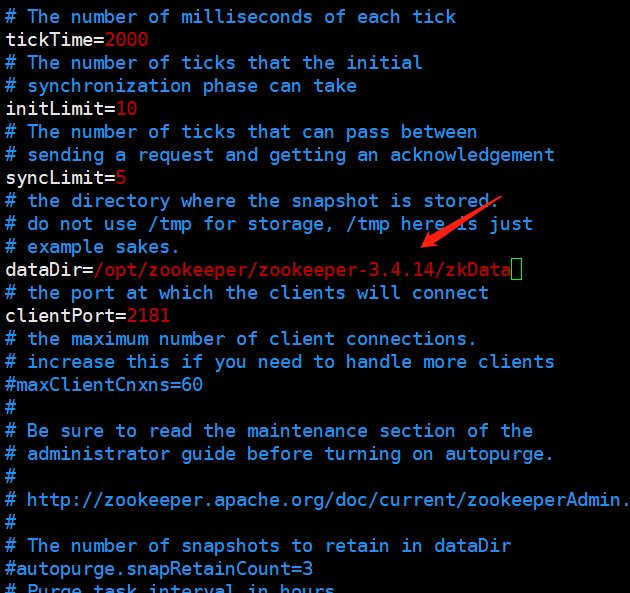
至于配置文件里的其他参数,我们之后会解读,下面启动服务器。
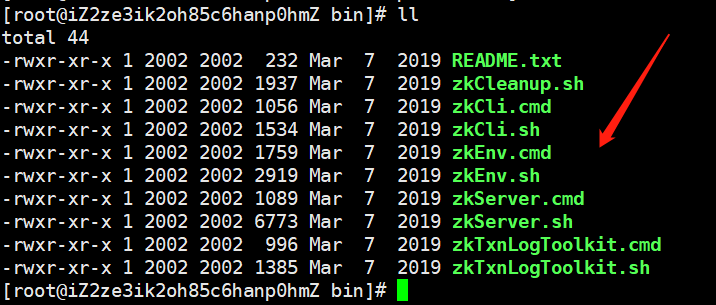
可以看到bin目录下有很多脚本,cmd是在Windows下面用的,我们不用管。我们看到有一个zkServer.sh,这个是启动zookeeper服务的。

启动成功,由于我们已经设置了环境变量,那么在任何地方都可以启动。
调用jps查看进程
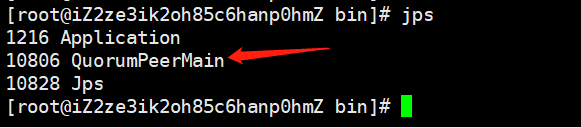
查看状态

此时的模式是standalone模式,表示单机。spark也有standalone模式,但是基本上很少用,使用的都是spark on yarn
既然有了服务端,那么是不是也要有客户端呢,对的,类似于redis,下面启动客户端。直接zkCli.sh即可,不需要start,出现如下表示启动成功
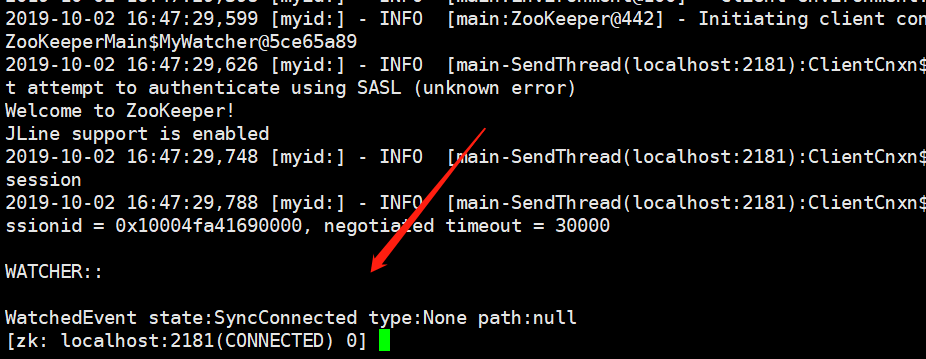

如何退出服务端呢?可以使用zkServer stop
7.配置文件参数解读
这个配置文件就是我们之前的zoo.cfg,里面有几个重要的参数。
tickTime=2000:通信心跳数,zookeeper服务端与客户端的心跳时间,单位为毫秒。initLimit=10:领导者和追随者初始的通信时限,也就是第一次建立连接时能容忍的最大时限。当然这里的10不是10s,而是10个tickTimesyncLimit=5:集群中领导者和追随者之间响应的最大时限(这里是连接建立之后),单位同样是tickTime。如果超过syncLimit * tickTime,那么领导者会认为该追随者已经死掉,从而将该follower从服务器列表中删除掉。dataDir:数据文件目录+数据持久化路径,主要用于保存zookeeper中的数据,我们刚刚已经修改了。clientPort=2181:客户端连接的端口
8.选举机制(面试重点)
我们之前说了,zookeeper服务端是有一个领导者和多个追随者,但是这个领导者是怎么选出来的呢?我们貌似没有在配置文件中看到有关领导者和追随者的参数啊。
在此之前先来看看zookeeper内部的一些机制
- 半数机制:集群中半数以上机器存活,集群可用,所以zookeeper适合安装在奇数台服务器上面。
- zookeeper虽然在配置文件中没有指定leader和follower。但是,zookeeper在工作时,是有一个节点为leader,其他则为follower,leader是通过内部的选举机制临时产生的。
那么领导者到底是怎么选出来的,很简单,服务器按照id(这里的id后面再说)从小到大的顺序数数,当超过半数的时候,就被选为领导者。比如有五台服务器,server1、2、3、4、5,那么领导者就是server3
9.节点类型
zookeeper集群有很多个节点,那么节点的类型是什么样子的呢?首先,节点类型有两种
持久(persistent):客户端和服务端断开连接之后,创建的节点不删除,也就意味着节点上的数据会保留短暂(ephemeral):客户端和服务端断开连接之后,创建的节点会自己删除,数据不会被保留。
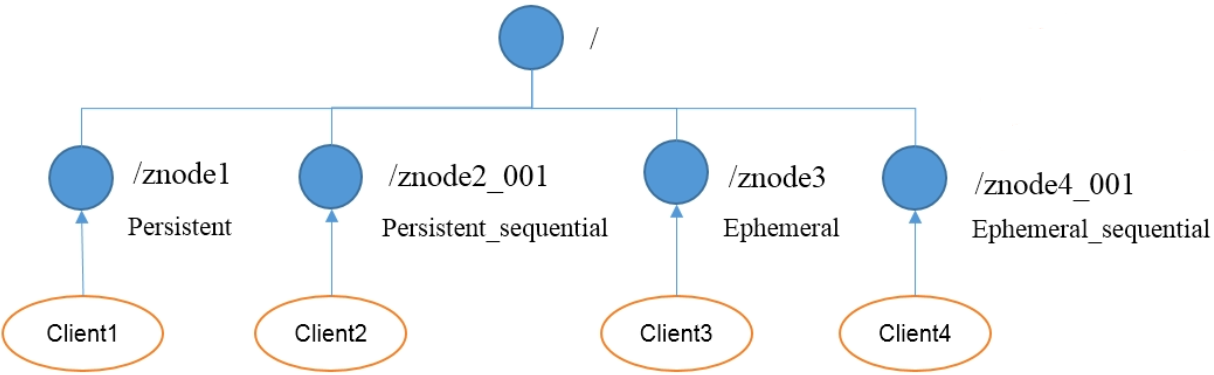
(1)持久化目录节点,客户端与zookeeper断开连接之后,该节点依旧存在
(2)持久化顺序编号目录节点,客户端与zookeeper断开连接之后,该节点依旧存在,只是zookeeper会给该节点名称进行顺序编号
(3)临时目录节点,客户端与zookeeper断开连接后,该节点被删除
(4)客户端与zookeeper断开连接后,该节点被删除,只是zookeeper会给该节点名称进行顺序编号
说明:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护。
在分布式系统中,顺序号可以被用于为所有事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序。
10.分布式集群搭建
我们使用zookeeper集群的胡,一台服务器肯定是不够的。那么需要多台机器,但是我阿里云上面只有一台服务器,所以只介绍方法,就不演示了。
假设我们有三台服务器,主机名分别是mashiro、satori、koishi。那么在zoo.cfg配置文件中增加如下内容,注意:三个主机的配置文件都是如下。
server.1=mashiro:2888:3888
server.2=satori:2888:3888
server.3=koishi:2888:3888
解释一下,从等号右边开始,我们看到两个:把等号右边分成了三部分,第一部分就不用说了,主机名,用于定位你是哪台主机的。2888,是leader和follower交换信息的端口,副本要进行同步啊,3888是交换选举信息的端口。至于等号左边的部分server.是固定的,关键后面的数字是啥,数字表示的是这是第几个服务器,所以我们还要进行配置,不然我们凭什么告诉zookeeper,mashiro就是第一个、satori是第二个、koishi是第三个服务器呢?配置的方法也很简单,还记得我们之前指定的dataDir吗?你指定了哪个目录就切换到哪个目录,然后在该目录下新建一个myid文件,没有后缀名。然后各自写上数字即可,mashiro主机,就在自己的myid文件里面写个1、satori主机在自己的myid文件里面写个2、koishi主机在自己的myid文件里面写个3,这样就可以了。
然后启动集群,三台机器,每台机器都要启动。当我们在mashiro主机上面,zkServer.sh start的时候,是可以启动成功的,但是zkServer.sh status的时候,是会报错的。因为三台机器我们只启动了一台,没有到达半数以上。然后再启动satori上的zookeeper,此时到达半数以上,zookeeper集群正常启动。然后按照id从小到大,因此satori主机上的zookeeper是leader,输入zkServer.sh status的时候,会有一个mode,之前单机的话是standalone,集群的时候则是leader,同理mashiro主机上的mode则是follower。那么当我们再启动koishi的时候,mode肯定是follower了,因为leader已经被选出来了。
关于领导者和追随者怎么选的,这里再解释一下。我们刚才说了在myid文件里面定义了id,就是一个数字。假设我们有9台服务器,说明只要启动5台就能够选出leader了。我们按照顺序启动了id分别为5、7、1、8、2的机器,显然会选出leader,那么leader是谁呢?对,显然是9,因为是按照id从小到大。更具体一点的说,每一个zookeeper集群启动的时候都会把票投给自己,希望自己成为leader,比如我们启动id为5的zookeeper,但是呢票数不够,于是又启动了id=7的zookeeper,但是也不够,此时id=5的zookeeper就会把票给id=7的zookeeper,因为7比5大。当继续启动id=1的zookeeper,由于也不够,所以id=1的zookeeper就会把自己的票也给id等于7的zookeeper。当启动了id=8的zookeeper,那么由于也只有一票,因此id=7的zookeeper会将自己的3票都给id=8的zookeeper,最后id=2的zookeeper也是同理。那么此时超过半数,leader就选出来了,即便后面出现id=9的,也没用了,因为leader已经选出来了。所以我们之前说,就相当于从小到大数id,超过一半就选出leader。
11.shell命令操作
和hadoop有shell操作一样,zookeeper也有shell命令行操作,也就是zkCli.sh,下面我们就一个一个介绍
-
显示所有操作命令:help
-
查看当前znode中所包含的内容:ls
-
查看当前节点详细的数据:ls2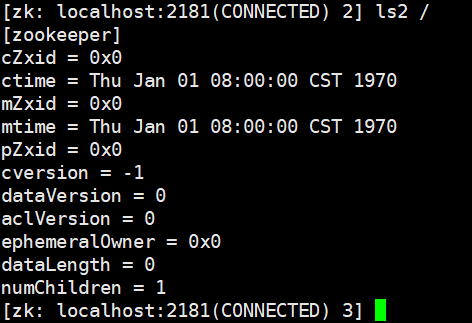
至于这些输出分别代表什么,我们后面介绍 -
创建节点:createcreate /overwatch,这样可以创建一个节点吗?理论上是可以的,但实际上不行,因为创建节点必须要有数据,因此要在创建节点的时候就指定数据,否则不让你创建。比如:
create /overwatch genji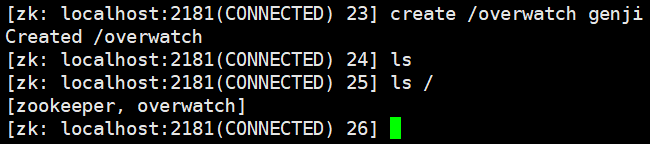
-
创建多级节点:create
-
获取节点内容:get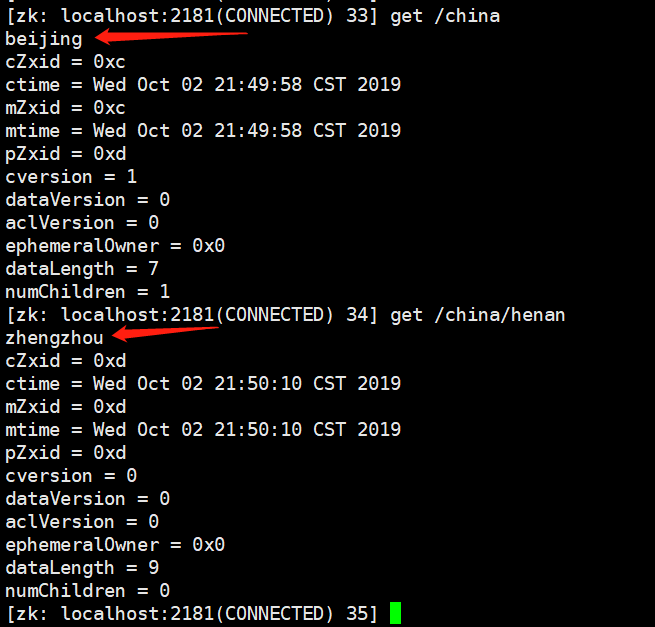
在/china这个节点下存放了beijing,在/china/henan这个节点下存放了zhengzhou
-
创建短暂的节点:create -e
如果我此时断开客户端,重新连接的话。

会发现shanghai这个节点没了,因为我们创建的是临时节点。
-
创建带有序号的节点:create -s
-
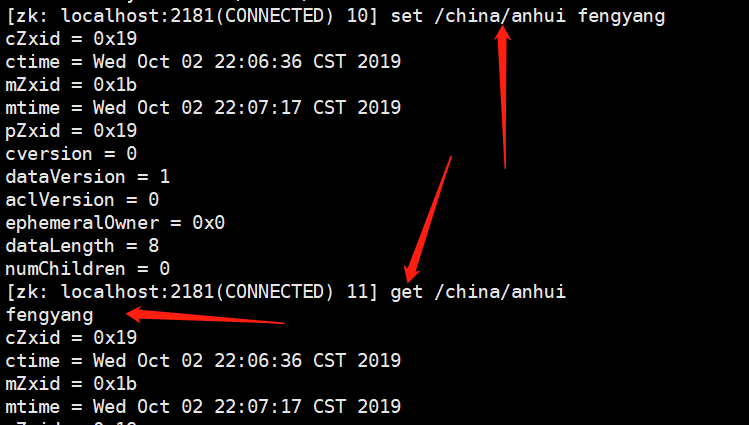
修改节点的值:set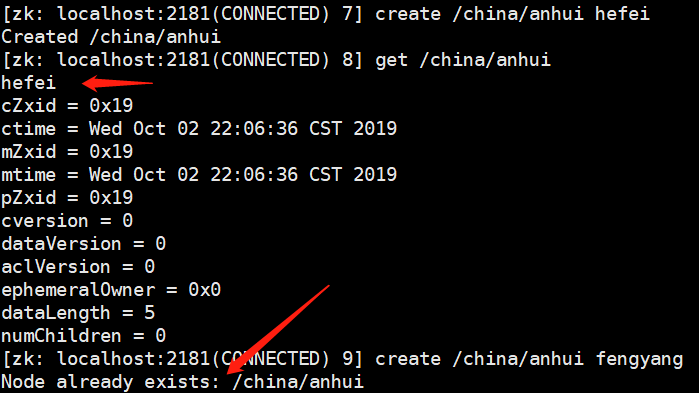
每一个节点存一个值,当我们create /china/anhui hefei的时候,get /china/anhui的时候也是hefei,如果我们想修改的话,能不能直接create /china/anhui fengyang呢?显然是不行的,因为节点重复了,需要使用set /china/anhui fengyang
-
监听某个节点的变化:get 节点 watch这个需要使用集群,假设我现在在A机器上,我在B机器上面也启动了zookeeper客户端,此时B上面的数据和A是一样的,因为数据是同步的。那么此时我在B机器上输入
get /china/anhui watch就表示监听/china/anhui这个节点,然后我在A机器上对/china/anhui这个节点进行set,那么B机器上就会收到提示,提示我们监听的节点被修改了。注意:监听是一次性的,如果再次set的话,那么B机器就不会再提示了,除非再次watch。 -
监听某个节点的子节点的变化:ls 节点 watch
此时/china里面有多个子节点,
ls /china watch就表示监视这个节点内字节的变化,如果里面某个字节点被删除了、或者创建了新的子节点,那么就会收到提示。这个同样是一次性的 -
删除节点:delete
-
递归删除节点:rmr我们先看看使用delete删除 /china

提示我们节点不为空

使用rmr删除,删除成功,节点已经没了
-
查看节点状态:stat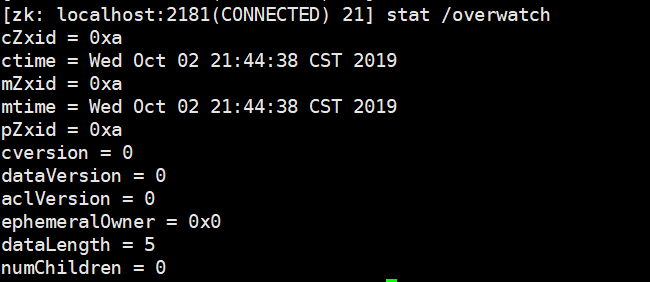
12.stat结构体
我们已经看到很多便类似如下的信息了,实际上在开发过程中这个意义不大,了解一下就可以了。
cZxid = 0xa
ctime = Wed Oct 02 21:44:38 CST 2019
mZxid = 0xa
mtime = Wed Oct 02 21:44:38 CST 2019
pZxid = 0xa
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
cZxid:创建节点的事务zxid,每次修改zookeeper状态都会收到一个zxid形式的时间戳,也就是zookeeper事务ID。事务ID是zookeeper中所有修改的次序,每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。ctime:znode被创建的时间(时间戳形式,单位为毫秒)mZxid:znode最后更新的事务zxidmtime:znode最后修改的时间(时间戳形式,单位为毫秒)pZxid:znode最后更新的子节点zxidcversion:znode子节点变化号,znode子节点修改次数dataVersion:znode数据变化号aclVersion:znode访问控制列表的变化号ephemeralOwner:如果是临时节点,这个是znode所拥有的session id。如果不是临时节点,则为0dataLength:znode的数据长度numChildren:znode的子节点数量
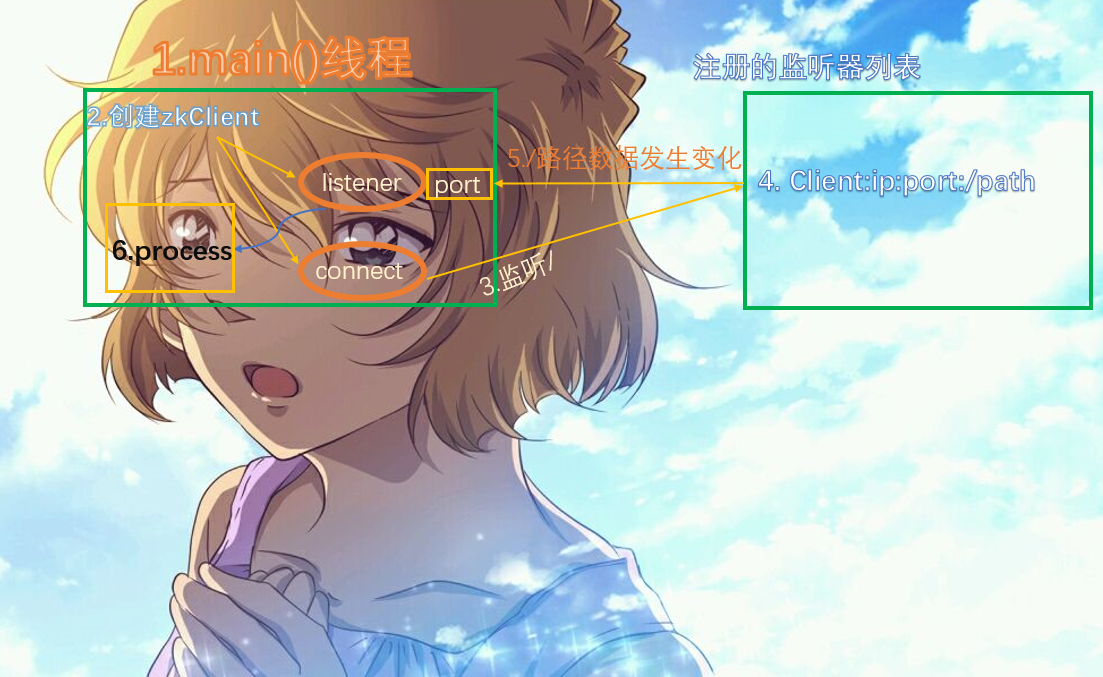
13.监听原理(面试重点)
还记得我们之前说的监听吗?有两种:一个是监听节点数据的变化get 节点 watch,另一个是ls 节点 watch,那么它们的原理是什么呢?
- 首先要有一个main()线程
- 在main线程中创建zookeeper客户端,然后会新创建两个线程,一个负责网络连接通信(connect),一个负责监听(listener)
- 通过connect将注册的监听事件发送给zookeeper服务端
- 在zookeeper的注册监听器列表中将注册的监听事件添加进去
- zookeeper监听到有数据或者路径变化,就会将这个消息发送给listener线程
- 然后在执行listener线程里面执行我们自己定义的逻辑,比如process函数
14.写数据流程

15.python连接zookeeper
为什么是python连接zookeeper,因为笔者是python系的,不是java系的,像zookeeper、hadoop、spark都有python的接口,下面我们就来介绍如何使用python连接zookeeper
使用python连接zookeeper的话,需要安装第三方模块,模块名叫kazoo,直接pip install kazoo即可,其实连接zookeeper还有一个模块,也叫zookeeper。但是个人更推荐kazoo,因为它是纯Python实现的,使用起来比较方便。
# 导入KazooClient
from kazoo.client import KazooClient
# 输入ip:port,创建zookeeper客户端
zk = KazooClient("47.94.174.89:2181")
# 连接zookeeper,注意这一步不是启动服务器上的zookeeper
# 服务器上的zookeeper必须已经启动才可以,这一步是与zookeeper建立连接
zk.start()
"""
start函数里面接收一个timeout,默认是15秒
如果服务没有启动(目标计算机积极拒绝),那么会不断地尝试连接,直到超时
"""
并且连接一旦建立,无论是连接丢失、还是会话过期,KazooClient都会不断尝试连接
我们还可以使用stop显式地中断连接
from kazoo.client import KazooClient
zk = KazooClient("47.94.174.89:2181")
zk.start()
# todo:
...
...
...
...
...
...
# 程序结束关闭连接
zk.stop()
kazoo状态监听。为什么会有状态监听,是因为客户端与服务端的会话状态一旦发生连接中断、连接恢复、或者会话过期等情景时,我们能及时作出相应的处理。那么首先会话都有哪些状态呢?
LOSTCONNECTEDSUSPENDED
我们的KazooClient就相当于是zkCli,当与服务端建立连接时,状态为LOST,连接建立成功,状态为CONNECTED。如果在整个会话的生命周期里,伴随着网络闪断、服务端异常或者其他什么原因导致客户端和服务端连接断开的情况,那么KazooClient的状态就会切换到SUSPENDED。与此同时,KazooClient会不断尝试与服务端建立连接,直至超时,如果连接建立成功了,那么状态会再次切换到CONNECTED
from kazoo.client import KazooClient
zk = KazooClient("xx.xx.xx.xx:2181")
zk.start()
def connection_listener(state):
if state == "LOST":
# todo:
...
elif state == "SUSPENDED":
# todo:
...
else:
...
zk.add_listener(connection_listener)
zk.stop()
下面就是重头戏,也不知道谁的头这么重哈,就是节点的增删改查
-
查看当前节点有哪些子节点# 返回一个列表 print(zk.get_children("/")) # ['zookeeper', 'overwatch'] -
获取某个节点的acl(access control list)# 返回一个元组 print(zk.get_acls("/")) """ ( [ACL(perms=31, acl_list=['ALL'], id=Id(scheme='world', id='anyone'))], ZnodeStat(czxid=0, mzxid=0, ctime=0, mtime=0, version=0, cversion=6, aversion=0, ephemeralOwner=0, dataLength=0, numChildren=2, pzxid=33) ) """ -
查询某个节点是否存在# 不存在返回None,存在返回节点的信息,相当于ls2 print(zk.exists("/china")) # None print(zk.exists("/overwatch")) # ZnodeStat(czxid=10, mzxid=10, ctime=1570023878072, mtime=1570023878072, version=0, cversion=0, aversion=0, ephemeralOwner=0, dataLength=5, numChildren=0, pzxid=10) -
创建多级节点print(zk.get_children("/")) # ['zookeeper', 'overwatch'] # 创建多级节点/china/henan/zhengzhou zk.ensure_path("/china/henan/zhengzhou") print(zk.get_children("/")) # ['zookeeper', 'overwatch', 'china'] print(zk.get_children("/china")) # ['henan'] print(zk.get_children("/china/henan")) # ['zhengzhou']这····,感觉这比zkCli客户端强多了。注意:ensure_path只能创建节点,不能添加数据,如果想添加数据,只能后续使用set修改。
-
修改与获取节点的值# 使用set修改,get获取,这个zookeeper客户端的api是一致的 # 但是有有一点需要注意,set的值,必须是bytes类型 zk.set("/china", b"CHINA") zk.set("/china/henan", b"HENAN") zk.set("/china/henan/zhengzhou", b"ZHENGZHOU") print(zk.get("/china")) print(zk.get("/china/henan")) print(zk.get("/china/henan/zhengzhou")) """ (b'CHINA', ZnodeStat(czxid=57, mzxid=64, ctime=1570087652802, mtime=1570088077404, version=1, cversion=1, aversion=0, ephemeralOwner=0, dataLength=5, numChildren=1, pzxid=58)) (b'HENAN', ZnodeStat(czxid=58, mzxid=65, ctime=1570087652810, mtime=1570088077413, version=1, cversion=1, aversion=0, ephemeralOwner=0, dataLength=5, numChildren=1, pzxid=59)) (b'ZHENGZHOU', ZnodeStat(czxid=59, mzxid=66, ctime=1570087652818, mtime=1570088077422, version=1, cversion=0, aversion=0, ephemeralOwner=0, dataLength=9, numChildren=0, pzxid=59)) """ -
创建节点# ensure_path可以创建多级,并且不要求上一级必须存在,会递归创建 # 但是create创建多级,必须要求前面的级必须存在,实际上还是只能创建一级 # ensure_path不可以指定数据,只能后续set修改,但是create必须在创建节点的可以指定数据,也可以不指定 zk.create("/china/shanghai") print(zk.get_children("/china")) # ['shanghai', 'henan'] zk.create("/china/beijing") print(zk.get("/china/beijing")) # (b'', ZnodeStat(czxid=82, mzxid=82, ctime=1570088550845, mtime=1570088550845, version=0, cversion=0, aversion=0, ephemeralOwner=0, dataLength=0, numChildren=0, pzxid=82)) # 可以看到,不指定的话默认是'' # 创建的时候,指定数据,同样是bytes类型 zk.create("/china/anhui", b"ANHUI") print(zk.get("/china/anhui")) # (b'ANHUI', ZnodeStat(czxid=83, mzxid=83, ctime=1570088550858, mtime=1570088550858, version=0, cversion=0, aversion=0, ephemeralOwner=0, dataLength=5, numChildren=0, pzxid=83)) -
删除节点print(zk.get_children("/china")) # ['shanghai', 'beijing', 'anhui', 'henan'] zk.delete("/china/anhui") print(zk.get_children("/china")) # ['shanghai', 'beijing', 'henan'] # 能不能递归删除呢? try: zk.delete("/china") except Exception: import sys exec_type, _, _ = sys.exc_info() # 提示我们节点不为空 print(exec_type) # <class 'kazoo.exceptions.NotEmptyError'> # 如果想递归删除,当然没有rmr,但是可以再delete里面加上一个参数,recursive=True,默认是False,表示是否允许递归删除 print(zk.get_children("/")) # ['zookeeper', 'overwatch', 'china'] zk.delete("/china", recursive=True) print(zk.get_children("/")) # ['zookeeper', 'overwatch'] -
监听器def watch(event): print("观察者发现变化了") zk.get_children("/overwatch", watch=watch)还可以通过装饰器的方法实现
ChildrenWatch:当该节点的子节点个数发生变化时触发DataWatch:当该节点数据发生变化时触发@zk.ChildrenWatch("/overwatch") def watch_children(children): print(f"----{children}----") @zk.DataWatch("/overwatch") def watch_data(data, state): print(f"node is {data}") -
事务自v3.4以后,zookeeper支持一次发送多个命令,这些命令作为一个原子进行提交,要么全部执行成功,要么全部失败
transaction = zk.transaction() transaction.create("/satori") # 因为没有提交,所以获取不到 print(zk.get_children("/")) # ['zookeeper', 'overwatch'] transaction.delete("/overwatch") # 调用commit,表示将之前的操作提交上去 transaction.commit() # 可以看到,不仅/satori节点有了,而且/overwatch节点也没了 print(zk.get_children("/")) # ['satori', 'zookeeper']
16.企业面试题
question:请简述zookeeper的选举机制
详情见8.选举机制(面试重点),就是半数机制,只要启动的服务端超过半数,就会选择myid中数值最大的成为leader
question:zookeeper的监听原理是什么?
详情见13.监听原理(面试重点),有一个main线程,创建客户端,然后再创建两个线程,一个是connect一个listener。listener监听,connect负责将监听的事件发送给服务端,服务端将事件注册到事件列表里面,如果有变化,那么服务端就会告知一直在监听的listener。然后执行我们自己定义的逻辑。
question:zookeeper的部署方式有哪几种?集群中的角色有哪些?集群最少需要几台机器?
部署方式有单机模式和集群模式集群中的角色有领导者(leader)和追随者(follower)因为投票是半数机制,所以最少需要三台机器
question:zookeeper的常用命令有哪些?
ls create get create set delete等等