莫队学习笔记
莫队是啥?(怎么每篇都在问这个问题?)
莫队,是一种与分块齐名的(O(Nlog{N}))的暴力美学算法,常用来骗分和伪装正解
如何实现莫队?
我们来一道经典题看下莫队的表现吧:
[ ext{[SDOI2009]HH的项链} ]题目描述
HH有一串由各种漂亮的贝壳组成的项链。HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义。HH 不断地收集新的贝壳,因此,他的项链变得越来越长。有一天,他突然提出了一个问题:某一段贝壳中,包含了多少种不同的贝壳?这个问题很难回答……因为项链实在是太长了。于是,他只好求助睿智的你,来解决这个问题。
大概就是给出一个序列,每次询问区间中元素种类数...
教练我会暴力!
我打了一个暴力程序,看看就好
#include<bits/stdc++.h>
using namespace std;
int n,m,l,r,ans;
int a[500005];
bool cnt[1000005];
template<class T>inline void read(T &res)
{
T flag=1;char c;
while((c=getchar())<'0'||c>'9')if(c=='-')flag=-1;res=c-'0';
while((c=getchar())>='0'&&c<='9')res=(res<<1)+(res<<3)+c-'0';res*=flag;
}
int main()
{
read(n);
for(register int i=1;i<=n;++i) read(a[i]);
read(m);
for(register int i=1;i<=m;++i)
{
read(l);read(r);ans=0;
for(register int j=l;j<=r;++j) cnt[a[j]]=1;
for(register int j=0;j<=1000005;++j)
{
if(cnt[j]) ++ans;
cnt[j]=0;
}
printf("%d
",ans);
}
return 0;
}
20分,开不开心?

我们需要优化!
很快地,我们想到了一个优化:当遍历到一个数的时候,如果这个数还没出现过,ans+1,去除一个数的时候,如果再也没有这个数了,ans-1!
并没有什么用……
继续优化!
考虑到每个区间可能会有重叠,我们不立即枚举区间了!我们通过指针调整区间位置来统计答案!

如上图,通过指针的移动,统计指到的每一个数,便可以得出答案
于是我们改出了以下的代码:
#include<bits/stdc++.h>
using namespace std;
int n,m,ql,qr,a[500005];
int l=1,r=0,now=0,cnt[1000005],aa[500005];
inline void add(int pos)
{
if(!cnt[aa[pos]]) ++now;
++cnt[aa[pos]];
}
inline void del(int pos)
{
--cnt[aa[pos]];
if(!cnt[aa[pos]]) --now;
}
template<class T>inline void read(T &res)
{
T flag=1;char c;
while((c=getchar())<'0'||c>'9')if(c=='-')flag=-1;res=c-'0';
while((c=getchar())>='0'&&c<='9')res=(res<<1)+(res<<3)+c-'0';res*=flag;
}
inline void work()
{
for(register int i=1;i<=m;++i)
{
read(ql);read(qr);
while(l<ql) del(l++);
while(l>ql) add(--l);
while(r<qr) add(++r);
while(r>qr) del(r--);
printf("%d
",now);
}
}
int main()
{
read(n);
for(register int i=1;i<=n;++i) read(aa[i]);
read(m);
work();
return 0;
}
这个优化力度远远大于上一个优化,因此效果非常显著
(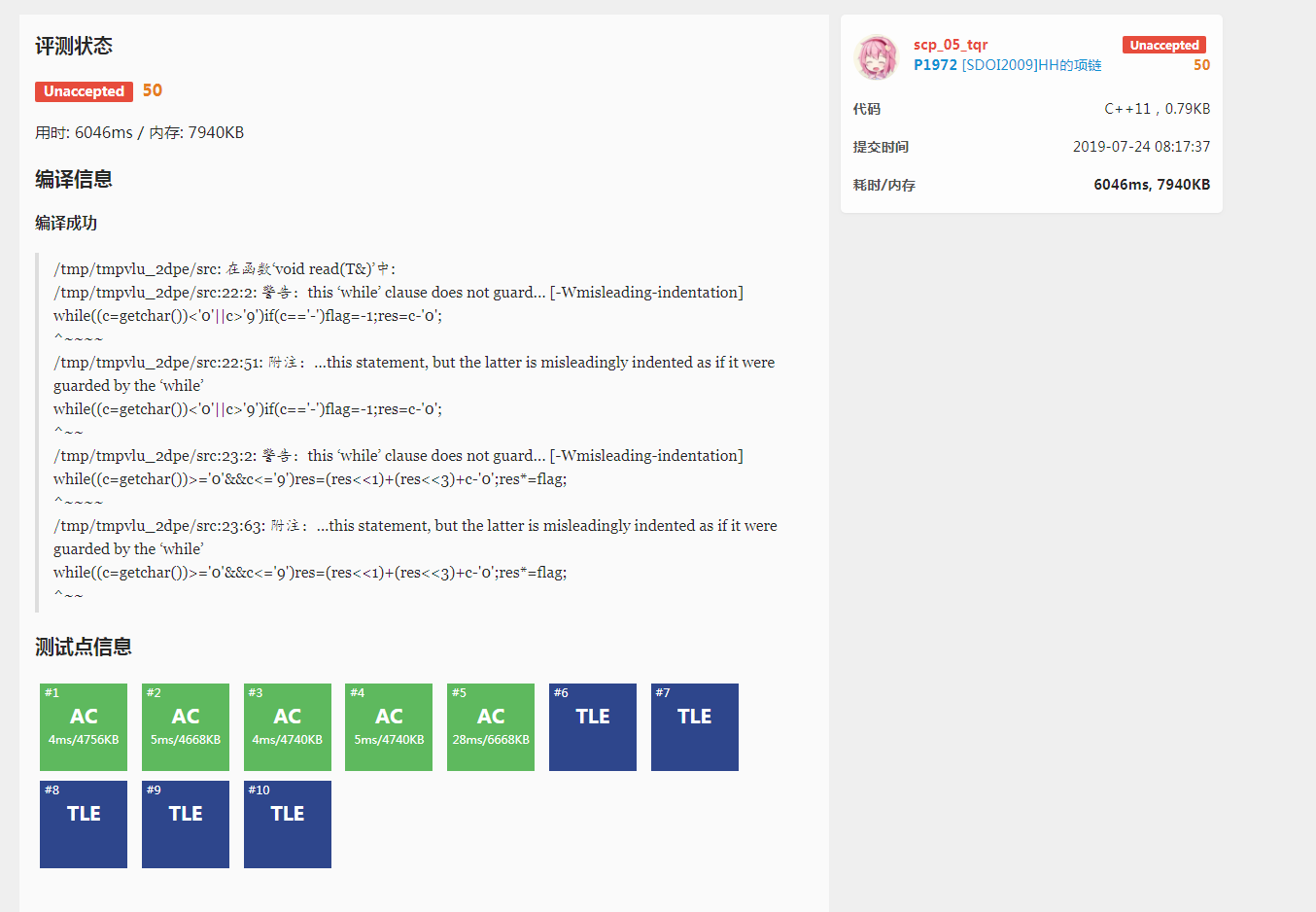
但是,仍然T了5个点,因此我们还要继续优化!
继续优化
- 奇偶排序
当有多个查询区间时,我们将大小为n的序列分为(1)~(sqrt{n})个块,从(1)到(sqrt{n})编号,然后根据这个对查询区间进行排序
把查询区间按照左端点所在块的序号排个序,如果左端点所在块相同,再按右端点排序
int cmp(query a, query b)
{
return belong[a.l]==belong[b.l]?a.r<b.r:belong[a.l]<belong[b.l];
}
这样排序之后优化力度已经很大了,但还不够!
对于左端点在同一奇数块的区间,右端点按升序排列,反之降序(即奇偶排序)
int cmp(query a, query b)
{
return(belong[a.l]^belong[b.l])?belong[a.l]<belong[b.l]:((belong[a.l]&1)?a.r<b.r:a.r>b.r);
}
- 指针压缩
这里主要是优化常数,将上面的函数和判断压缩成下面这个样子
while(l<ql) now-=!--cnt[aa[l++]];
while(l>ql) now+=!cnt[aa[--l]]++;
while(r<qr) now+=!cnt[aa[++r]]++;
while(r>qr) now-=!--cnt[aa[r--]];
然后就A了
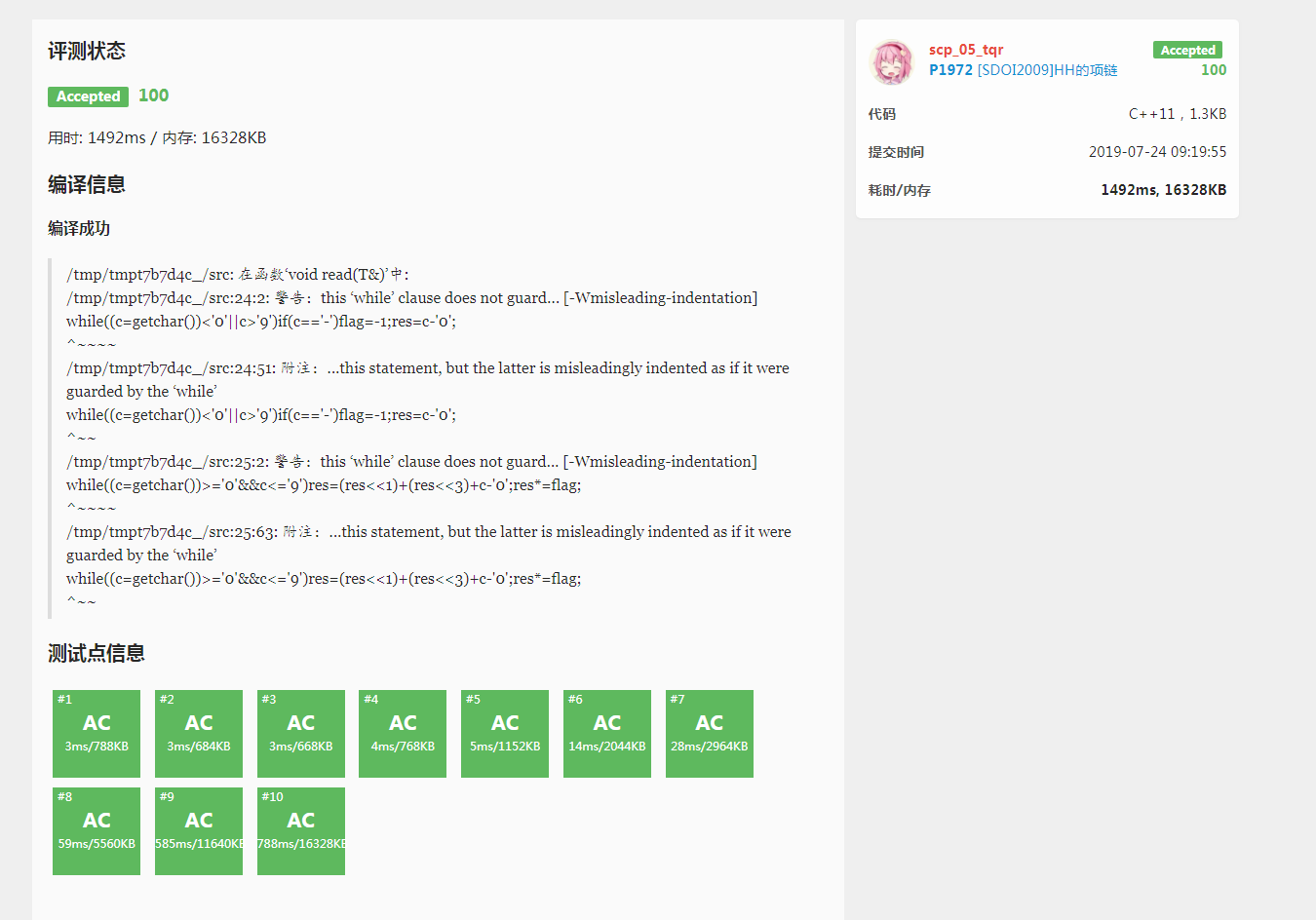
对比:

完整代码:
#include<bits/stdc++.h>
#define N 1000005
#define ql q[i].l
#define qr q[i].r
using namespace std;
int n,m,l=1,r=0;
int belong[N],a[N],cnt[N],now,ans[N];
struct query
{
int l,r,id;
}q[1000005];
bool cmp(query a,query b)
{
return(belong[a.l]^belong[b.l])?belong[a.l]<belong[b.l]:((belong[a.l]&1)?a.r<b.r:a.r>b.r);
}
template<class T>inline void read(T &res)
{
T flag=1;char c;
while((c=getchar())<'0'||c>'9')if(c=='-')flag=-1;res=c-'0';
while((c=getchar())>='0'&&c<='9')res=(res<<1)+(res<<3)+c-'0';res*=flag;
}
template<class T>inline void write(T x)
{
if(x<0)putchar('-'),x=-x;
if(x>=10)write(x/10);
putchar('0'+x%10);
}
int main()
{
read(n);
int size=sqrt(n);
int bnum=ceil((double)n/size);
for(register int i=1;i<=bnum;++i)
for(register int j=(i-1)*size;j<=i*size;++j)
belong[j]=i;
for(register int i=1;i<=n;++i) read(a[i]);
read(m);
for(register int i=1;i<=m;++i)
{
read(q[i].l);
read(q[i].r);
q[i].id=i;
}
sort(q+1,q+m+1,cmp);
for(register int i=1;i<=m;++i)
{
while(l<ql) now-=!--cnt[a[l++]];
while(l>ql) now+=!cnt[a[--l]]++;
while(r<qr) now+=!cnt[a[++r]]++;
while(r>qr) now-=!--cnt[a[r--]];
ans[q[i].id]=now;
}
for(register int i=1;i<=m;++i)
write(ans[i]),putchar('
');
return 0;
}

