from weibopy import WeiboOauth2, WeiboClient from collections import defaultdict import time import webbrowser import re from pyecharts import Map from snownlp import SnowNLP from collections import Counter #————————————————————part 1 获取微博访问权限———————————————————— client_key = '' # 你的 app key client_secret = '' # 你的 app secret redirect_url = 'https://api.weibo.com/oauth2/default.html' auth = WeiboOauth2(client_key, client_secret, redirect_url) # 获取认证 code webbrowser.open_new(auth.authorize_url) # 在打开的浏览器中完成操作 # 最终会跳转到一个显示 「微博 OAuth2.0」字样的页面 # 从这个页面的 URL 中复制 code= 后的字符串 # URL 类似这样 https://api.weibo.com/oauth2/default.html?code=9c88ff5051d273522700a6b0261f21e6 code = input('输入 code:') # 使用 code 获取 token token = auth.auth_access(code) # print(token) # AccessToken是为了避免多次调用API时需要重复输入用户名和密码的一种设计。程序登录后获得AccessToken,使用AccessToken就能在一定时间内免密码使用平台的功能。 #————————————————————part 2 调用 API 接口获取数据———————————————————— # token 是刚刚获得的 token,可以一直使用 client = WeiboClient(token['access_token']) # suffix 指定 API 的名称,parmas 是参数,在文档中有详细描述 result = client.get(suffix='comments/show.json', params={'id': 4359907132320154, 'count': 200, 'page': 1}) #团团点名视觉中国 # print(result) #————————————————————part 3 整理所需数据———————————————————— province_list = defaultdict(list) # 保存按省划分的评论正文 comment_text_list = [] # 保存所有评论正文 # 获取「团团点名视觉中国」评论列表 # 共获取 10 页 * 每页最多 200 条评论 for i in range(1, 11): result = client.get(suffix='comments/show.json', params={'id': 4359907132320154, 'count': 200, 'page': i}) comments = result['comments'] if not len(comments): break for comment in comments: text = re.sub('回复.*?:', '', str(comment['text'])) province = comment['user']['province'] province_list[province].append(text) comment_text_list.append(text) print('已抓取评论 {} 条'.format(len(comment_text_list))) time.sleep(1) # ————————————————————part 4制作积极份子热图和表情统计———————————————————— # 获取省份列表 provinces = {} results = client.get(suffix='common/get_province.json', params={'country': '001'}) for prov in results: for code, name in prov.items(): provinces[code] = name print(provinces) # 评论情感分析 positives = {} for province_code, comments in province_list.items(): sentiment_list = [] for text in comments: s = SnowNLP(text) sentiment_list.append(s.sentiments) # 统计平均情感 positive_number = sum(sentiment_list) positive = positive_number / len(sentiment_list) * 100 # 按省保存数据, 0010 为国家前缀 province_code = '0010' + str(province_code) if province_code in provinces: provice_name = provinces[province_code] positives[provice_name] = int(positive) # 绘制情感分布图 keys = list(positives.keys()) values = list(positives.values()) map = Map("团团点名视觉中国 积极份子分析地域图", width=1200, height=600) map.add("积极份子", keys, values, visual_range=[0, 100], maptype='china', is_visualmap=True, is_label_show=True, visual_text_color='#000') map.render(path="积极份子分布.html") # 获取评论中出现的表情 emoji_list = [] for comment in comment_text_list: emojis = re.findall(re.compile(u'([.*?])', re.S), comment) if emojis: for emoji in emojis: emoji_list.append(emoji) emoji_dict = Counter(emoji_list) print(emoji_dict)
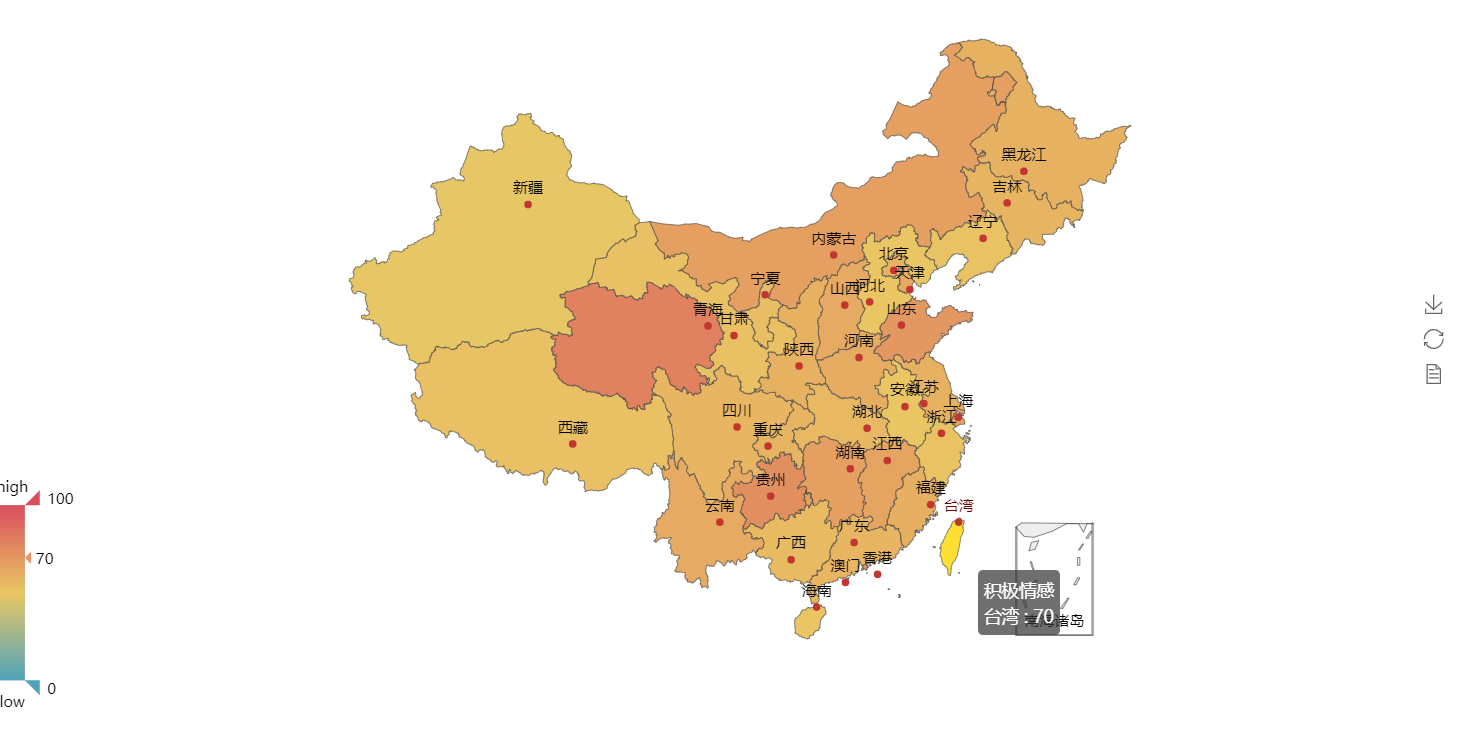
效果图:
附上微博来源地址(团团点名视觉中国):https://m.weibo.cn/detail/4359907132320154