记得以前初次接触fork()函数的时候,一直被“printf”输出多少次的问题弄得比较晕乎。不过,“黄天不负留心人"。哈~ 终于在学习进程和进程创建fork相关知识后,总算是大致摸清了其中的来龙去脉。废话不多讲,下面来谈谈本人的一点小小积累
- #include<unistd.h>
- pid_t fork(void);
- 返回值:自进程中返回0,父进程返回进程id,出错返回-1
fork()系统调用会通过复制一个现有进程来创建一个全新的进程. 进程被存放在一个叫做任务队列的双向循环链表当中.链表当中的每一项都是类型为task_struct成为进程描述符的结构.也就是我们写过的进程PCB.
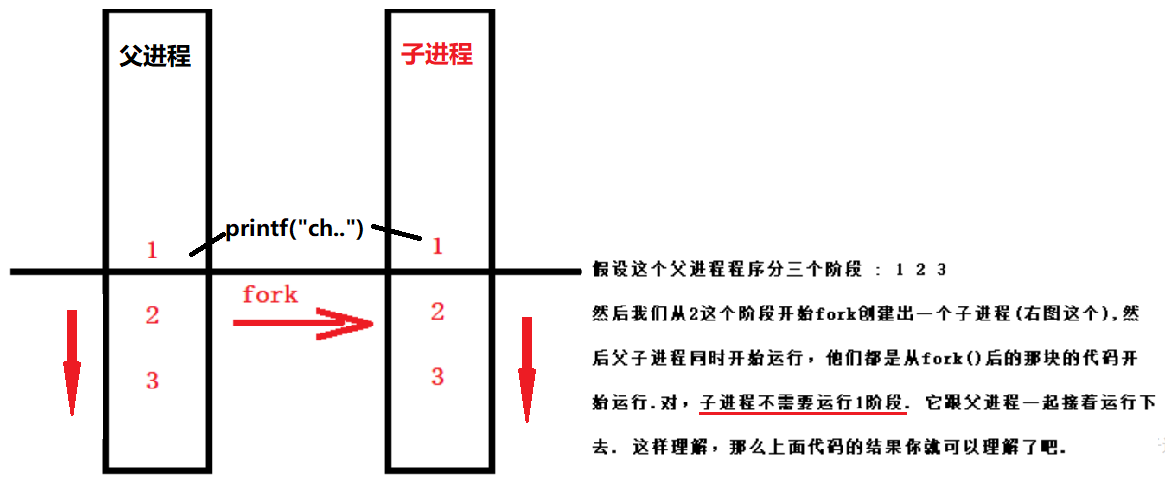
fork()运行时做的事情
1 /************************************************************************* 2 > File Name: 1.c 3 > Author: tp 4 > Mail: 5 > Created Time: Mon 07 May 2018 07:57:28 PM CST 6 ************************************************************************/ 7 8 #include <stdio.h> 9 #include <stdlib.h> 10 #include <unistd.h> 11 int main( void) 12 { 13 printf("change world! "); 14 pid_t pid = fork(); 15 if( pid == -1) {perror("fork"),exit(1); } 16 17 printf( "pid=%d, returnVal=%d ", getpid(), pid); 18 sleep( 1); 19 exit(0); 20 } ~
这段代码的运行结果,大家如果像我当时不了解fork的时候,一定会以为输出结果是两个"change world!",然后2个printf里面的内容. 因为

父子进程文件共享问题
1 /************************************************************************* 2 > File Name: 2.c 3 > Author: tp 4 > Mail: 5 > Created Time: Mon 07 May 2018 12:40:39 PM CST 6 ************************************************************************/ 7 8 #include <stdio.h> 9 #include <stdlib.h> 10 #include <unistd.h> 11 #include <fcntl.h> 12 13 int set = 110; 14 int main( void) 15 { 16 printf( "before fork "); 17 pid_t pid = fork( ); 18 if( pid < 0){ perror(" fork"),exit( 1);} 19 20 if( pid == 0) 21 { 22 ++set; 23 printf( "son pid=%d, %d ", getpid(), set); 24 } 25 else 26 { 27 sleep( 1); 28 printf( "parent pid=%d , %d ", getpid( ), set); 29 } 30 exit( 0); 31 }
看一下结果:
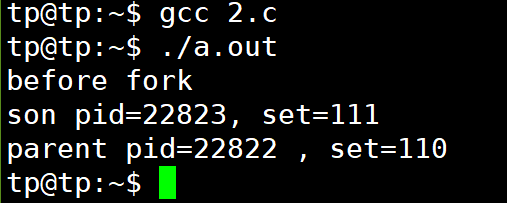
不难注意到 “before fork”这句话只是被打印了一次,这个从上面的例子,这不难理解;与此同时子进程中的set的值被改变了。此时再进行一个重定向操作会发生什么
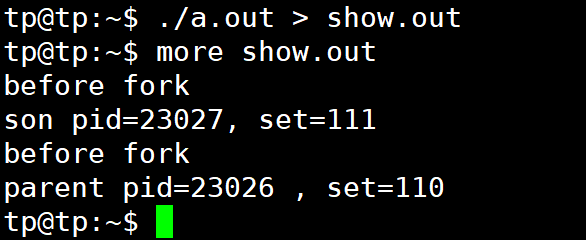
出现很神奇的现象! 这个时候打印了出了两次“before fork”,不仅仅是如此,上述针对父进程的标准输出执行重定向操作还导致了子进程也执行重定向操作。
透过现象看本质,来细细分析一下。针对打印两次“before fork”,首先,先要知道标准IO库是是带缓冲的,而像printf这种直接输出到标准输出时,这个缓冲区是由换行符刷新的;而当执行了重定向操作,这里就是将标准输出重定向到文件,文件就不会立即去刷新缓冲区(全缓冲的方式);好,由于在fork之前调用了一次printf,但fork之后,该行数据仍存留在缓冲区中,然后父进程数据空间被复制到子进程中,该行数据去也被复制了过去,这样父子进程都各自带有该行内容的缓冲区了,相当于子进程缓冲区添加了一行“before fork”,然后在每个进程exit之后,每个缓冲区的内容就被写到了相应的文件中。
再一个就是,在重定向父进程的标准输出时,子进程标准输出也被重定向。这就源于父子进程会共享所有的打开文件。 因为fork的特性就是将父进程所有打开文件描述符复制到子进程中。当父进程的标准输出被重定向,子进程本是写到标准输出的时候,此时自然也改写到那个对应的地方;与此同时,在父进程等待子进程执行时,子进程被改写到文件show.out中,然后又更新了与父进程共享的该文件的偏移量;那么在子进程终止后,父进程也写到show.out中,同时其输出还会追加在子进程所写数据之后,这也就解释了上面为什么“before fork”会在一个文件中打印两次。
在fork之后处理文件描述符一般又以下两种情况:
1.父进程等待子进程完成。此种情况,父进程无需对其描述符作任何处理。当子进程终止后,它曾进行过读,写操作的任一共享描述符的文件偏移已发生改变。
2.父子进程各自执行不同的程序段。这样fork之后,父进程和子进程各自关闭它们不再使用的文件描述符,这样就避免干扰对方使用的文件描述符了。这类似于网络服务进程。
同时父子进程也是有区别的:它们不仅仅是两个返回值不同;它们各自的父进程也不同,父进程的父进程是ID不变的;还有子进程不继承父进程设置的文件锁,子进程未处理的信号集会设置为空集等不同
fork()函数在底层中做了什么?


vfork和fork的之间的比较:
vfork()的诞生是在fork()还没有写时拷贝的时候,因为那个时候创建一个子进程的成本太大了,如果一下子创建好多了那么程序的效率一定会下降. 然后就有人提出了vfork(). vfork的实现原理非常简单,就是子进程,父进程完全公用一个资源. 就是是有人修改了内容,甚至main()函数退出了也不会新开辟一个空间. 所以这里里会有问题的,如果你的一个子进程没有使用exit()退出,那么程序就会出现段错误. 不相信可以去试一试~
vfork和fork之间的区别: