近来回转 C++的学习,脑子又被搞得了一团迷(简直不要忘得太快.....  )
)
过后静下来想一想,还是因为有些东西没搞清楚导致,所以理了理两个容易搞迷糊的地方。
引用与指针
C++进行传值更倾向于使用引用。引用实质就是给已经定义的变量起一个别名,函数通过这个别名来完成对应的功能。
【引用特点】
①一变量可取多个别名
②引用必须初始化,同时只能在初始化时被引用,
③只能被引用同一变量,从一而终
【使用引用注意几种情况】
(1)何时添加const进行修饰
①防止引用变量被修改
我们知道在变量前加const 表示这是个常变量,不能被修改。那么在引用前加上const是一样的道理,例如: int a = 2; const int& d = a; 这样的形式防止变量a的别名d 对值‘2’进行修改。
②引用的为常量 如:
 常量是具有常性的,所以必须在前面加上const使其保持常性。
常量是具有常性的,所以必须在前面加上const使其保持常性。
③引用参数存在隐式类型转换

(2)函数传引用作返回值
①不要返回临时变量的引用
例如
int& Add(int d1, int d2) //临时变量的引用作返回值 { int ret = d1 + d2; return ret; } void Test() { int& sum = Add(1, 2); //获取返回值ret的别名 cout<<"占用位置"<<endl; cout<<sum<<endl; }
结果:

分析:ret是隶属于Add函数栈帧,ret的引用作返回值,返回的其实是ret变量的地址;而当Add函数调用完毕后,该处被操作系统收回权限,若再通过返回的地址访问该处就是非法的(结果便成了上图随机值)。这与传值返回有着很大的差别,
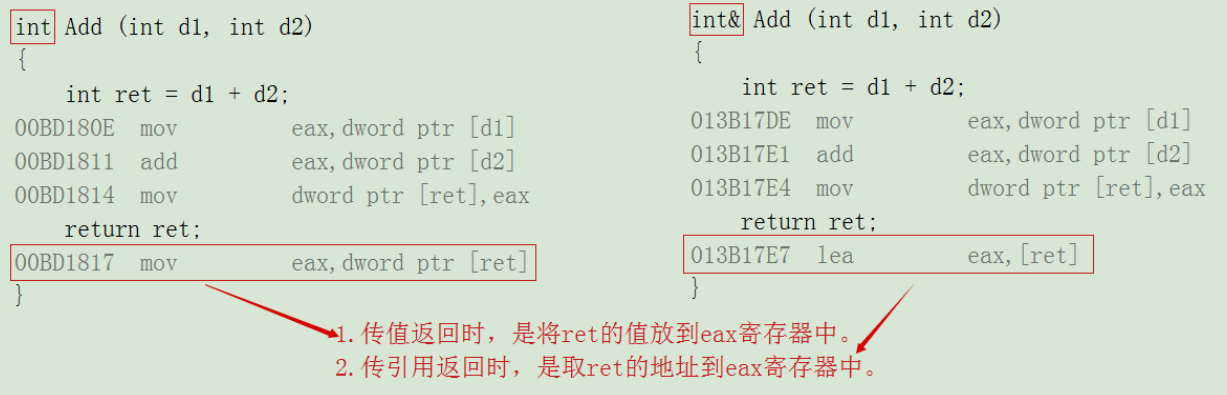
(传值返回&引用返回 汇编代码)
②当返回的对象出了函数作用域依旧存在,最好使用引用作返回,因为它更高效。
因为引用返回仅仅是一个别名(其实是保存在寄存器eax中的地址),而若是传值返回,且返回的ret是一个对象,便会产生临时对象,这个临时对象用ret拷贝构造初始化(拷贝构造请往下看),而这个临时对象底层是在返回值接收方的函数中提前开辟好的,在函数接受方接收完成后,还需调用析构函数来清理该临时对象,进一步增大了开销;所以用引用返回会更高效。
注:返回值优化参考http://www.cnblogs.com/hazir/archive/2012/04/19/2456840.html
然后就是注意它和指针的区别(比较重要)。
【引用和指针区别】
* 引用只能在定义时初始化一次,之后不能改变去指向其它变量(从一而终);指针变量的值可变
* 引用必须指向有效的变量,指针可以为空;用指针传参,函数栈额外开空间来拷贝一份参数地址,引用传参则不会。
* sizeof指针对象和引用对象的意义不一样。sizeof引用得到的是所指向的变量的大小,而sizeof指针是对象地址的大小。
* 指针和引用自增(++)自减(--)意义不一样。
总之, 相对而言,引用比指针更安全,指针更灵活。
构造函数
首先,它是用来初始化类里面的成员变量的公有成员函数,有且仅在定义对象时自动执行一次。
它有如下基本特征:
1. 函数名与类名相同。
2. 无返回值。
3. 对象实例化时系统自动调用对应的构造函数。
4. 构造函数可以重载。
5. 构造函数可以在类中实现,也可以在类外实现(类外加上类限定符)
6. 如果类定义中没有给出构造函数,则C++编译器自动产生一个缺省的构造函数,但只要我们定义了一个构造函数,系统就不会自动生成缺省的构造函数。(半缺省时,只能从最右边往左连续着缺省,如:Date(int year, int month =1, int year = 1 ),这和参数入栈规则有关)
7. 无参的构造函数和全缺省值的构造函数都认为是缺省构造函数,并且缺省的构造函数只能有一个。
【构造函数初始化列表】
我们一般都是在构造函数体内来初始化数据成员,但这并不是真正意义上的初始化,而是赋值;初始化发生时间更早,是在数据成员的defalut(缺省)构造函数被自动调用的时候,内置类型除外。defalut构造函数先为这些数据成员设初值,然后自定义实现的构造函数再对它们赋予新值。于是这样便把default构造函数的一切作为给白白浪费了,效率有待提高。
所以一般初始化是使用“初始化列表”来进行的。初始化列表以一个冒号开始,接着一个逗号分隔数据列表,每个数据成员都放在一个括号中进行初始化。如下:


class B(int b1, int b2) : _b1(b1) , _b2(b2) {//可以保留原构造赋值部分} private: int _b1; int _b2; };
它位于构造函数参数列表后,在函数体{}之前,这说明该列表里的初始化工作发生在函数体内的任何代码被执行之前。该列表中针对各个成员变量而设的参数,直接当实参被拿去作初值(或传进另一拷贝构造函数中来初始化该成员变量),这样也就避免前面提到的“白白浪费”了,这也正是 effectiveC++所提到的观点。
所以尽量使用初始化列表进行初始化,因为它是更高效的。
大部分时候构造函数既可以使用初始化列表又能在函数体内初始化,但有几种情况必须使用初始化列表。
- 类的非静态的const 数据成员 (成员被const修饰,于是被定义出来之后,构造函数来初始化,此时已不能被修改)
- 为引用的数据成员 (引用从一而终)
- 没有缺省构造函数的类的成员变量 ()
注意!!
成员变量按声明顺序依次初始化,而非初始化列表出现的顺序 (看如下例子)
class A { public: A(int n) : _a2(n) , _a1(_a2) {} void Show() { cout<<"a1 "<<_a1<<endl<<"a2 "<<_a2<<endl; } private: int _a1; int _a2; }; int main() { A a(1); a.Show(); return 0; }
不难看出在构造函数中是先跟变量_a2赋值,然后再用_a2来初始化_a1,结果就应该是 1 和 1;但是结果却是
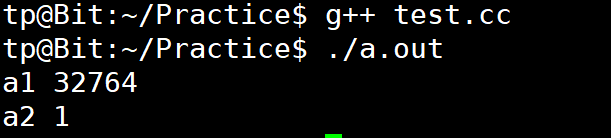
因为成员变量按声明顺序依次初始化,而非初始化列表出现的顺序。这里按变量定义顺序,应该先初始化 _a1 ,再初始化 _a2 ,但初始化列表里, _a1 是使用 _a2 的值来初始化的,但此时 _a2还没有被初始化,于是_a1就不会被初始化了。
接下来说说一个特殊的构造函数
【拷贝构造函数】
创建对象时使用同类对象来进行初始化(相当于复制对象),这时所用的构造函数称为拷贝构造函数(Copy Constructor),拷贝构造函数是特殊的构造函数。
class Date
{
public :
Date()
{}
// 拷贝构造函数
Date (const Date& d)
{
_year = d ._year;
_month = d ._month;
_day = d ._day;
}
private :
int _year ;
int _month ;
int _day ;
};
特征:
1. 拷贝构造函数其实是一个构造函数的重载。
2. 拷贝构造函数的参数必须使用引用传参,使用传值方式会引发无穷递归调用(调拷贝构造函数会传参,传参过程又会调用拷贝构造,以此往复...无穷递归)
3. 若未显示定义,系统会生成默认缺省的拷贝构造函数。缺省的拷贝构造函数会依次拷贝类成员进行初始化
何时调用拷贝函数:
- 一个对象以值传递的方式传入函数体
- 一个对象以值传递的方式从函数返回(与返回值优化密切相关)
- 一个对象需要通过另一个对象进行初始化
关于拷贝构造函数还有一类很热的问题,构造函数拷贝赋值函数的N种调用情况
即判断下面每种情况都调用了多少次构造、拷贝构造...
//1.Date 对象做参数传值 void fun1 (Date d) //void fun1(Date& d) {} // 2.Date 对象做返回值传值 Date fun2 () // Date& fun2() { Date d ; return d ; } // 3.Date 对象做临时返回值传值 (编译器优化问题) Date fun3 () // Date& fun3() { return Date (); } int main () { // 场景 Date d1; fun1(d1); // 场景 Date d2 = fun2(); // 场景 Date d3 ; d3 = fun3 (); return 0; }
这其实和前面所说的传值返回也有着紧密的联系,同时还涉及编译器的优化,如果有兴趣可以参考:
http://www.cnblogs.com/hazir/archive/2012/04/19/2456840.html