Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
v安装Elasticsearch
1.0 安装Java环境
安装Elasticsearch之前,需要安装Java8或Java8以上的Java环境,如果没有安装Java的,可以看之前的一篇文章《CentOS安装Java JDK》。

1.1 下载ES
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.1-linux-x86_64.tar.gz
在这里你可以找到elasticsearch最新的安装包。
下载之后用sudu rz -y上传到linux服务器的/opt目录。
1.2 解压文件
tar -zxvf elasticsearch-7.0.0.tar.gz
1.3 安装完事删除压缩包
rm -rf elasticsearch-7.0.0-linux-x86_64.tar.gz
v创建用户
2.0 创建Elasticsearch用户组
groupadd esgroup
2.1 创建es用户
useradd esuser
passwd esuser
enter password
注意:为es用户设置密码时:1、密码不得包含用户名,即:esuser 2、密码长度大于8位
本示例中我设置的测试密码是:toutoudemo
2.2 把用户esuser添加到esgroup用户组
usermod -G esgroup esuser
2.3 设置sudo权限
[root@localhost toutou]# visudo
#在root ALL=(ALL) ALL 一行下面
#添加estest用户 如下:
esuser ALL=(ALL) ALL
#添加成功保存后切换到es用户操作
[root@localhost toutou]# su esuser
[es@localhost root]$
2.4 验证esuser的sudo权限
sudo -l -U esuser
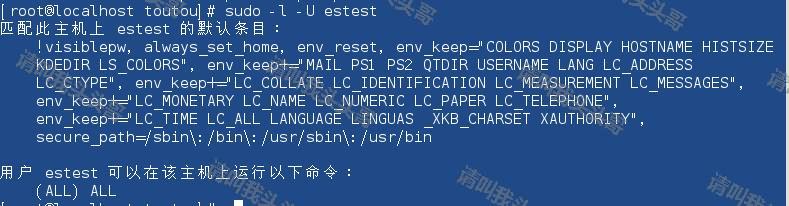
2.5 更改elasticsearch-7.3.1文件夹以及内部文件的所属用户为esuser, 用户组组为esgroup
sudo chown -R esuser:esgroup elasticsearch-7.3.1
v配置Elasticsearch
3.1 设置elasticsearch.yml
cluster.name: my-application
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
cluster.initial_master_nodes: ["node-1"]
elasticsearch.yml属性含义:
属性 cluster.name 如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。
属性 node.name 节点名可以忽略
属性 node.master 指定该节点是否有资格被选举成为node,默认是true
属性 index.number_of_shard 设置默认索引分片个数,默认为5片
属性 index.number_of_replica 设置默认索引副本个数,默认为1个副本
属性 path.conf 设置配置文件的存储路径,默认是es根目录下的config文件夹。
属性 path.data 设置索引数据的存储路径,默认是es根目录下的data文件夹
属性 path.work 设置临时文件的存储路径,默认是es根目录下的work文件夹
属性 path.logs 设置日志文件的存储路径,默认是es根目录下的logs文件夹
属性 path.repo 快照存储路径
属性 gateway.recover_after_nodes 设置集群中N个节点启动时进行数据恢复,默认为1
属性 network.host 映射出来的ip
属性 transport.tcp.port 设置节点间交互的tcp端口,默认是9300
属性 http.port: 9200 设置对外服务的http端口,默认为9200
属性 index.number_of_replicas 索引的复制副本数量
属性 indices.fielddata.cache.size fielddata缓存限制,默认无限制
属性 indices.breaker.fielddata.limit fielddata级别限制,默认为堆的60%
属性 indices.breaker.request.limit request级别请求限制,默认为堆的40%
属性 indices.breaker.total.limit 保证上面两者组合起来的限制,默认堆的70%
属性 discovery.zen.ping.multicast.enabled 是否广播模式,默认true,广播模式即同一个网段的ES服务只要集群名[cluster.name]一致,则自动集群
属性 discovery.zen.ping.unicast.hosts 手动指定,哪个几个可以ping通的es服务做集群,注意该设置应该设置在master节点上,data节点无效
3.2 修改/etc/sysctl.conf
注意切换回root 用户 执行
vm.max_map_count=262144
保存退出后,使用sysctl -p 刷新生效
3.3 修改文件/etc/security/limits.conf
* hard nofile 65536
* soft nofile 65536
* soft nproc 2048
* hard nproc 65536
v启动Elasticsearch
bin/elasticsearch
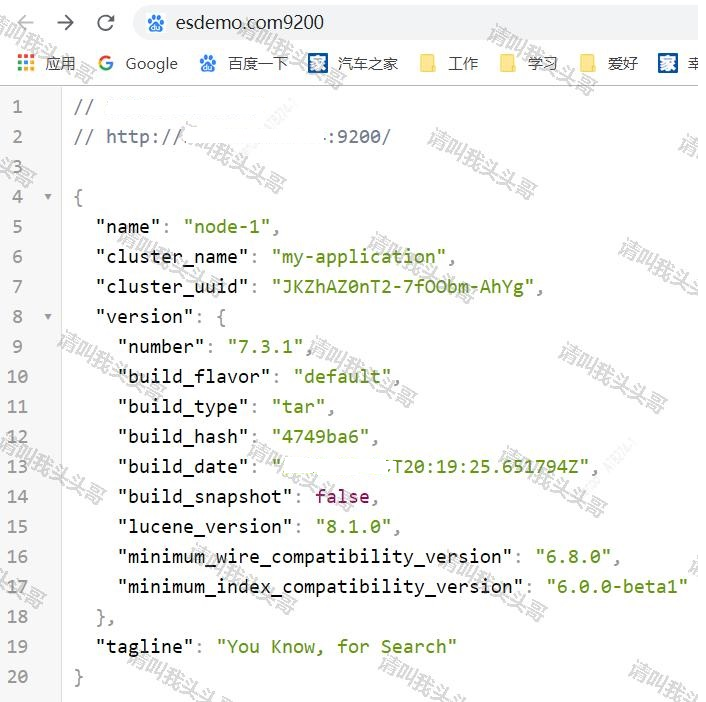
v安装elasticsearch-head
elasticsearch-head是基于nodejs开发的,所以需要安装nodejs环境
4.0 载nodejs 安装包
wget https://nodejs.org/dist/v10.13.0/node-v10.13.0-linux-x64.tar.xz
4.1 安装nodejs
tar -xvf node-v10.13.0-linux-x64.tar.xz
4.2 配置nodejs环境变量
vim /etc/profile
##配置nodejs 的HOME目录
export NODEJS_HOME=/usr/local/node-v10.13.0-linux-x64
##加入nodejs的环境变量
export PATH=${JAVA_HOME}/bin:${NODEJS_HOME}/bin:$PATH
保存/etc/profile,并执行 source /etc/profile 使其生效。
4.3 验证nodejs安装是否成功
node -v
4.4 下载es-head并解压
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
4.5 进入解压head目录
执行 npm install
若提示npm不可用,则需要安装npm sudo apt-get install npm
4.6 运行elasticsearch-head服务
npm run start
启动后浏览器中输入http://localhost:9100,效果如下:
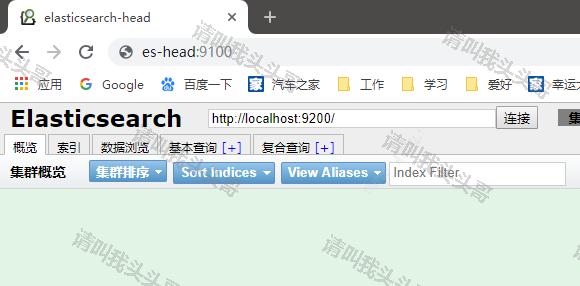
4.7 配置es的连接地址
vim /opt/elasticsearch-head/_site/app.js
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://ip:9200";
4.8 修改Elasticsearch 服务配置属性
修改elasticsearch服务配置文件允许跨域(在elasticsearch.yml文件中添加)
http.cors.enabled: true
http.cors.allow-origin: "*"
4.9 测试效果
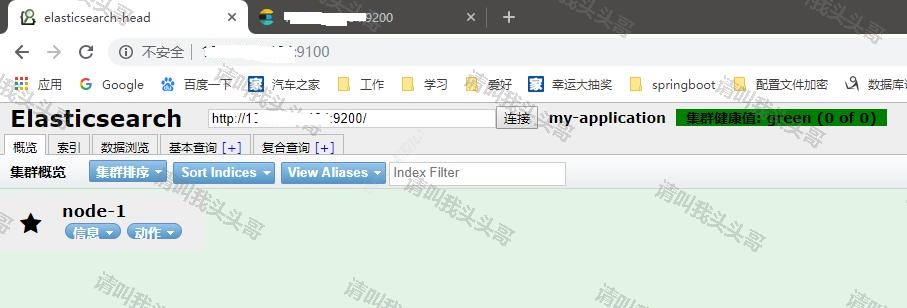
作 者:请叫我头头哥
出 处:http://www.cnblogs.com/toutou/
关于作者:专注于基础平台的项目开发。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!