前言:
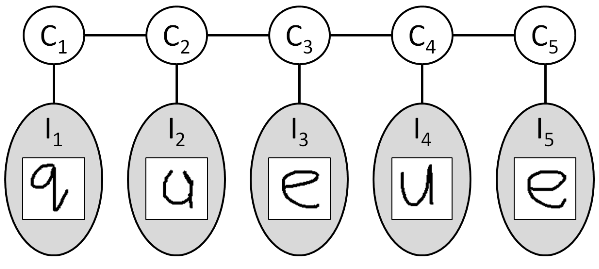
本次实验主要任务是学习CRF模型的参数,实验例子和PGM练习3中的一样,用CRF模型来预测多张图片所组成的单词,我们知道在graph model的推理中,使用较多的是factor,而在graph model参数的学习中,则使用较多的是指数线性模型,本实验的CRF使用的是log-linear模型,实验内容请参考 coursera课程:Probabilistic Graphical Models 中的assignmnet 7. 实验code可参考网友的:code实验对应的模型示意图如下:
CRF参数求解过程:
本实验中CRF模型所表示的条件概率计算公式为:
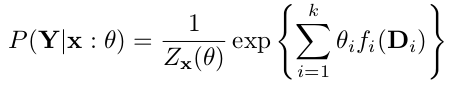
其中的分母为划分函数,表达式为:
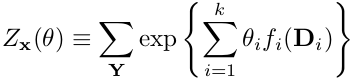
采用优化方法训练CRF模型的参数时,主要任务是计算模型的cost和grad表达式。其中cost表达式为:
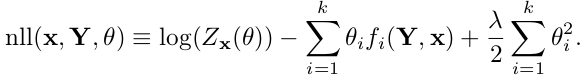
grad表达式为:
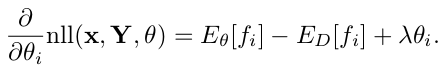
公式中的2个期望值表示模型对特征的期望以及数据对特征的期望,其表达式如下:
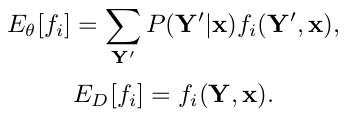
在计算cost和grad时需要分别计算下面6个中间量:

关于这几个中间量的计算方法,可以参考实验教程中的介绍,或者直接看博文后面贴出的代码,这里简单介绍下其计算方法:
log partition function: 需先建立CRF模型对应的clique tree,并对其校正,校正过程中时需要message passing,而最后passing的消息和最后一个clique factor相乘后的val之和取对数就logZ了。
weighted feature counts: 当训练样本中某个样本及标签的值符合CRF模型的某一个特征时,就将该特征对应的参数值累加,最后求和即可。
regularization cost: 直接计算。
model expected feature counts: 计算模型对特征的期望,同样需要用到前面校正好了的clique tree. 当某个特征的变量全部属于clique tree中某个clique变量时,求出该clique对应的factor中符合这些特征变量值的和,注意归一化。
data feature counts: 在计算weighted feature counts的同时,如果某个特征在样本中出现,则对相应特征计数。
regularization gradient term: 直接计算。
matlab知识:
ndx = sub2ind(siz,varargin):
siz为一个矩阵的维度向量,varargin输入的向量表示在矩阵size的位置,返回的是linear index的值。比如sub2ind([3 4],2,4)返回11,表示在3×4大小的矩阵中,第2行第4列为矩阵的第11个元素。
C = horzcat(A1,...,AN):
将参数表示的矩阵在水平方向合成一个大矩阵。
实验中一些函数简单说明:
[cost, grad] = LRCostSGD(X, y, theta, lambda, i):
计算带L2惩罚项的LR cost. 其中X是输入矩阵,每一行代表一个样本,y为对应的标签向量。theta为LR模型的权值参数,lambda为权值惩罚系数。i表示选择X矩阵中第i个样本来计算(循环取,mod实现)。cost和grad分别为这个样本的误差值和输出对权值的导数值。
thetaOpt = StochasticGradientDescent (gradFunc, theta0, maxIter):
实验1的内容。gradFunc是函数句柄,[cost, grad] = gradFunc(theta, i),计算logistic regression在第i个样本theta处的cost和grad. theta0为权值初始值,maxIter为最大迭代次数。这里的每次迭代只使用了一个样本,采用随机梯度下降法(SGD)更新权值。
thetaOpt = LRTrainSGD(X, y, lambda):
该函数完成的是用训练样本X和标签y对LR进行参数优化,迭代次数和初始学习率等超参数在函数内部给定,实现该函数时需调用StochasticGradientDescent().
pred = LRPredict (X, theta):
计算样本矩阵X在参数theta下的预测标签pred.
acc = LRAccuracy(GroundTruth, Predictions):
计算关于真实标签GroundTruth和预测标签Predictions的准确率。
allAcc = LRSearchLambdaSGD(Xtrain, Ytrain, Xvalidation, Yvalidation, lambdas):
实验2的内容。该函数是计算lambdas向量中每个lambda在验证集Xvalidation,Yvalidation上的错误率,这些错误率保存在输出变量allAcc中。
[P, logZ] = CliqueTreeCalibrate(P, isMax):
实验3的内容。对clique tree P进行校正,在校正过程中同时求得划分函数Z的log值:logZ. 求logZ时只能用sum-product不能使用max-product,所以此时的isMax=0. 其方法是将最后一次传送的message和最后一个clique相乘得到的factor,然后将factor中的val求和即可。
featureSet = GenerateAllFeatures(X, modelParams):
X是训练样本矩阵,因为在CRF中需要同时输入多张图片(本实验中多张图片构成一个单词),所以这里X中的每一行代表一张图片。结构体modelParams有3个成员:numHiddenStates,表示CRF中隐含节点的个数,这里为26(26个字母); numObservedStates,表示CRF中观察节点的个数,这里为2(每个像素要么为0,要么为1); lambda,权值惩罚系数。返回值featureSet包括2个成员:numParams, CRF中参数的个数,需考虑权值共享情况,即可能有多个特征共用一个权值; features, 装有多个feature的向量,且每个feature又是一个结构体。该feature结构体中有3个成员,如下:var,特征所包含的变量;assignment,因为特征一般为指示函数,所以表示特征只在assignment处的值为1,其它处为0; paramIdx,特征所对应的参数在theta中的索引。
features = ComputeConditionedSingletonFeatures (X, modelParams):
计算输入图像中单个像素的特征,如果输入X为3*32大小,因为有26个字母,所以总共的特征数为3*32*26=2496. 又假设每个像素可取0或1两个值,所以总共的参数个数为2*32*26=1664. 很明显有些特征是共用相同参数的。得到的features.var为图片序列的编号,features.assignment为对应字母的编号,features.paramIdx由像素值决定参数的位置。
features = ComputeUnconditionedSingletonFeatures (len, modelParams):
len为图片序列中图片的个数。如果len=3,则该函数实现后的特征向量长度为3*26=78,参数个数为26. features.var为图片编号,features.assignment为字母编号的,features.paramIdx位置和字母编号一样。
features = ComputeUnconditionedPairFeatures (len, modelParams):
len为图片序列中图片的个数。如果len=3, 则该函数实现后的特征向量长度为2*26*26=1352,参数个数为26×26=676. 其中的features.var为图片序列编号的组合,features.assignment为字母序号编号的组合,features.paramIdx为所在字母序号中对应的位置。
由上面学到的3种特征可知,特征的var都是与输入图片序列的标号有关,特征的assignment都是与字母的序号有关,paramIdx可能与字母序列以及图片序列编号都 有关。实验教程中给出的3种特征如下:
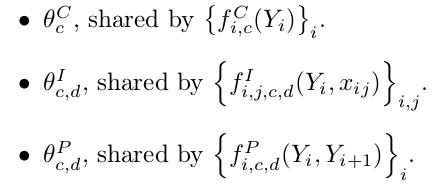
上面第2种特征为应该为conditionedPairFeatures,但和实验code没有对应起来,实验code中该特征被替换成了conditionedSigleFeatures.
VisualizeCharacters (X):
可视化样本X,因为X中一个样本序列,可能包含多个字母,该函数将X中所含的字母显示在一张图上。
[nll, grad] = InstanceNegLogLikelihood(X, y, theta, modelParams):
实验4和5的内容。其中参数X,y,modelParams和前面介绍的一样,注意X矩阵对CRF来说只算一个样本。参数theta为列向量,大小numParams x 1,是整个CRF模型中共享的参数。这2个实验的实现主要按照博文前面介绍的算法来计算,代码如下:
% function [nll, grad] = InstanceNegLogLikelihood(X, y, theta, modelParams) % returns the negative log-likelihood and its gradient, given a CRF with parameters theta, % on data (X, y). % % Inputs: % X Data. (numCharacters x numImageFeatures matrix) % X(:,1) is all ones, i.e., it encodes the intercept/bias term. % y Data labels. (numCharacters x 1 vector) % theta CRF weights/parameters. (numParams x 1 vector) % These are shared among the various singleton / pairwise features. % modelParams Struct with three fields: % .numHiddenStates in our case, set to 26 (26 possible characters) % .numObservedStates in our case, set to 2 (each pixel is either on or off) % .lambda the regularization parameter lambda % % Outputs: % nll Negative log-likelihood of the data. (scalar) % grad Gradient of nll with respect to theta (numParams x 1 vector) % % Copyright (C) Daphne Koller, Stanford Univerity, 2012 function [nll, grad] = InstanceNegLogLikelihood(X, y, theta, modelParams) % featureSet is a struct with two fields: % .numParams - the number of parameters in the CRF (this is not numImageFeatures % nor numFeatures, because of parameter sharing) % .features - an array comprising the features in the CRF. % % Each feature is a binary indicator variable, represented by a struct % with three fields: % .var - a vector containing the variables in the scope of this feature % .assignment - the assignment that this indicator variable corresponds to % .paramIdx - the index in theta that this feature corresponds to % % For example, if we have: % % feature = struct('var', [2 3], 'assignment', [5 6], 'paramIdx', 8); % % then feature is an indicator function over X_2 and X_3, which takes on a value of 1 % if X_2 = 5 and X_3 = 6 (which would be 'e' and 'f'), and 0 otherwise. % Its contribution to the log-likelihood would be theta(8) if it's 1, and 0 otherwise. % % If you're interested in the implementation details of CRFs, % feel free to read through GenerateAllFeatures.m and the functions it calls! % For the purposes of this assignment, though, you don't % have to understand how this code works. (It's complicated.) featureSet = GenerateAllFeatures(X, modelParams); %因为拟合的是条件概率,所以需要使用X % Use the featureSet to calculate nll and grad. % This is the main part of the assignment, and it is very tricky - be careful! % You might want to code up your own numerical gradient checker to make sure % your answers are correct. % % Hint: you can use CliqueTreeCalibrate to calculate logZ effectively. % We have halfway-modified CliqueTreeCalibrate; complete our implementation % if you want to use it to compute logZ. nll = 0; grad = zeros(size(theta)); %%% % Your code here: % 计算cost ctree = CliqueTreeFromFeatrue(featureSet.features, theta, modelParams); %对整个展开的CRF对应的graph而言 [ctree,logZ] = CliqueTreeCalibrate(ctree, 0); %对tree进行校正,并求出划分函数的对数 [featureCnt,weightCnt] = WeightFeatureCnt(y, featureSet.features, theta); weightedFeatureCnt = sum(weightCnt); regCost = (modelParams.lambda/2)*(theta * theta'); nll = logZ-weightedFeatureCnt+regCost; % 计算grad mFeatureCnt = ModelFeatureCount (ctree, featureSet.features, theta);%求模型期望时,不能使用y信息 regGrad = modelParams.lambda* theta; grad = mFeatureCnt-featureCnt+regGrad; end %% 该函数实现的功能是对每个特征都建立一个factor function ctree = CliqueTreeFromFeatrue(features, theta, modelParams) n = length(features); factors = repmat(EmptyFactorStruct(),n,1); for i=1:n factors(i).var = features(i).var; factors(i).card = ones(1,length(features(i).var))*modelParams.numHiddenStates; %难道都是y变量? factors(i).val = ones(1, prod(factors(i).card)); % 给该factor赋特征值 factors(i) = SetValueOfAssignment(factors(i), features(i).assignment, exp(theta(features(i).paramIdx))); end ctree = CreateCliqueTree(factors); end %% 该函数是求输入样本是否满足各个特征,如果满足特征i,则counts(i)=1,且weighted(i)填入相应的权值。 function [counts, weighted] = WeightFeatureCnt(y, features, theta) %这里要使用y值,因为要用y来计算指示特征 %注意特征向量的长度和参数向量的长度并不相同,因为多个特征可以共用一个参数,所以一般参数向量要短些 counts = zeros(1,length(theta)); weighted = zeros(length(theta), 1); for i = 1:length(features) feature = features(i); if all(y(feature.var)==feature.assignment) %判断所给的y是否满足特征所描述的 counts(feature.paramIdx) = 1; weighted(i) = theta(feature.paramIdx); end end end %% 该函数是计算模型的特征期望值,利用模型对应校正好的clique tree来计算,每个特征由其对应的clique中归一化的val构成 function mFeatureCnt = ModelFeatureCount (ctree, features, theta) mFeatureCnt = zeros(1,length(theta)); %提前开辟空间有利于matlab运算速度 for i = 1:length(features) mIdx = features(i).paramIdx; cliqueIdx = 0; for j = 1:length(ctree.cliqueList) if all(ismember(features(i).var,ctree.cliqueList(j).var)) cliqueIdx = j; %在clique tree上找到包含第i个特征所有元素的clique break; end end eval = setdiff(ctree.cliqueList(cliqueIdx).var, features(i).var); featureFactor = FactorMarginalization(ctree.cliqueList(cliqueIdx),eval); %得到只包含该特征变量的factor idx = AssignmentToIndex(features(i).assignment,featureFactor.card); mFeatureCnt(mIdx) = mFeatureCnt(mIdx) + featureFactor.val(idx) / sum(featureFactor.val);%归一化 end end
相关理论知识点:
learning按照模型结构是否已知,数据是否完全可以分为4类。比如HMM属于结构已知但数据不完全那一类(因为模型中的状态变量不能观测)。
PGM learning的任务有:probabilistic queries(for new instance);Specific prediction task(for new instance);Knowledge discovery(for distribution).
overfitting分为参数的overfitting和结构的overfitting.
PGM中比较容易整合先验知识。
MLE(最大似然估计)与充分统计量密切相关。
在BN中,如果有disjoint set的参数,则可将似然函数分解成局部的似然函数乘积。如果是table CPD的话,则局部似然函数又能进一步按照变量中每一维分解。
数据越少需使用越简单的模型,这样泛化性能才好,否则很容易过拟合。
MLE的缺点是不能很好的判断其参数估计的可信度。比如在下列两种情况下用抛硬币估计硬币朝上的概率时,使用MLE有结果:(a). 10次有7次朝上,这时估计硬币朝上的概率为0.7;(b). 10000次有7000次朝上,硬币朝上的概率也被判为0.7. 虽然估计的结果都为0.7,但很明显第二种情形的估计结果更可信,第一种情形过拟合。
为了克服MLE的缺点,可采用Bayesian估计(也叫最大后验估计),Bayesian估计的抗噪能力更强,类似于权值惩罚。贝叶斯估计是把模型中的参数也看成是一个随机变量,这样在估计该参数时会引入该参数的先验。为了达到共轭分布的目的,该先验分布一般取Dirichlet分布。
2个变量的Dirichlet分布曲线可以在2维平面上画出,是因为Dirichlet变量之间有和为1的约束,相当于减少了一个自由量。
在贝叶斯网络中,如果参数在先验中是相互独立的,则这些参数在后验中也是相互独立的。
划分函数的对数对参数求导,直接把划分函数按照定义代入公式,可得求导结果为模型对特征的期望。在采用MLE估计时,可以推出loss对参数的导数为数据对特征的期望减去模型对特征的期望, MRF下的证明如下:

所以最终MRF的梯度公式为:
![]()
相对应CRF是用的log条件似然函数,其梯度计算公式为:

MRF和CRF的loss函数的优化都属于凸优化。并且两者计算梯度时都需要图模型的inference,其中MRF每次迭代需inference一次,而CRF每次迭代的每个样本处需inference一次。从这点看貌似CRF的计算量要大些。不过由于MRF需要拟合联合概率,而CRF不需要,所以总的来说,CRF计算量要小些。
在MRF和CRF中也可以采用MAP估计,这里的先验函数一般为高斯先验和拉普拉斯先验,两者的公式分别为:
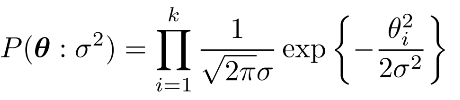
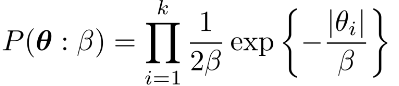
其中高斯先验类似L2惩罚,使得很多参数在0附近(因为接近0时导数变小,惩罚力度变小),但不一定为0,所以对应的模型很dense,而拉普拉斯先验类似L1惩罚,使得很多参数都为0(因为其导数不变,即惩罚力度没变),对应模型比较sparse.
参考资料: