前言:
接着coursera课程:Probabilistic Graphical Models 上的实验3,本次实验是利用马尔科夫网络(CRF模型)来完成单词的OCR识别,每个单词由多个字母组合,每个字母为16×8大小的黑白图片。本次实验简化了很多内容,不需要我们去学这些参数(已提供),不需要掌握推理的方法(也提供了),目的是让大家对CRF模型有个感性认识。马尔科夫网络相比贝叶斯网络的优点就是不用自己去确定那些太明确结构(比如说那些因果关系)。
matlab基础知识:
n = norm(X):
计算X的诱导2范数。如果X为向量,则n为它的欧式距离。如果X为矩阵,则n为X的最大特征值。
b = nchoosek(n,k):
这个是计算组合数的函数,从n个中拿出k个的拿法。
C = vertcat(A1,...,AN):
该函数是将多个矩阵A2,...,AN在垂直方向上连接起来得到C.
关于实验的一些注释:
allWords:
里面的每一个样本都是一个单词,单词的长度不一定相同。句子由字母构成,而每个字母就是一副小图片(16×8大小,且每个像素都是0或1)。所以对马尔科夫网络而言,每个训练样本是多张图片。且样本是带有标签的,标签值是一个向量,向量长度和单词长度一样,向量元素值表示对应字母的序号(1~26分别对应a~z)。
P = ComputeImageFactor (img, imgModel):
这个函数其实就是一个softmax分类器的实现,输入img通过softmax后得到一个26维的输出(模型参数已经保存在imgModel中了),输出值表示该图片内容为26个字母的概率。只是不太明白为什么imgModel中参数只有25个字母的权值,另外一个权值是在softmax进行归一化前直接默认输出为0的(归一化后当然不是0了),这样做的理由?
factors = ComputeSingletonFactors (images, imageModel):
对应的模型为:
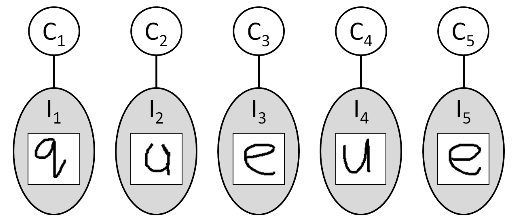
练习1所对应的内容。images是一个结构体向量,里面装了多张图片(可以组成多个单词)的信息(图片内容和标签)。imageModel是提供好了的模型的参数,这里只需用到softmax部分的参数。每一张图片在用softmax输出时都对应一个factor,所以factors也是一个结构体向量。
allFactors = BuildOCRNetwork (images, imageModel, pairwiseModel, tripletList):
该函数的作用是对一个单词的图片建立它的各种factor集合。因为各种factor形式所需要的参数已经给出了,比如imageModel,pairwiseModel,tripletList(当然正常情况下,这些参数是需要通过大量的单词图片样本来训练的)。
pred = RunInference (factors):
该函数是使用CRF模型来进行推理的函数。比如说已经用BuildOCRNetwork()函数算出了某个单词图片的factors,直接传入本函数,就可以得到这个图片序列所预测的单词。
wordPredictions = ComputeWordPredictions (allWords, imageModel, pairwiseModel, tripletList):
该函数的作用是计算所有单词图片集(allWords中含有多个单词的图片)在CRF模型下的预测,每个图片序列得到一个预测的单词。内部实现当然是循环调用RunInference()函数。
[charAcc, wordAcc] = ScorePredictions (words, predictions, showOutput):
该函数的作用是:用训练好的CRF模型对words进行预测,charAcc表示字母预测准确率,wordAcc表示单词预测准确率。
实验1完成后执行:
[charAcc, wordAcc] = ScoreModel(allWords, imageModel, [], []);
则会发现charAcc=76.70%,wordAcc=22.00%.
factors = ComputeEqualPairwiseFactors (images, K):
images是某个单词的图片序列,假设这个单词的长度为n,则该函数返回n-1个factor的集合。其中每个factor表中都有K*K项,且其值都设为1.
对应的模型为:
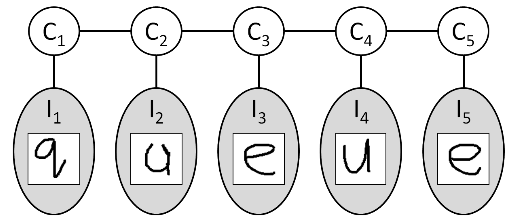
factors = ComputePairwiseFactors (images, pairwiseModel, K):
实验2的内容。这个函数和上面的函数是一样的,只不过它的每个factor的值是用模型中给定的权值。
实验2后完成后:首先将函数BuildOCRNetwork()中第45行注释掉,改为不等同的pairwiseModel,然后执行:
[charAcc, wordAcc] = ScoreModel(allWords, imageModel, pairwiseModel, [])
结果为:charAcc=80.90%,wordAcc=30.00%. 可以发现有较大提高。
实验3对应的模型为:
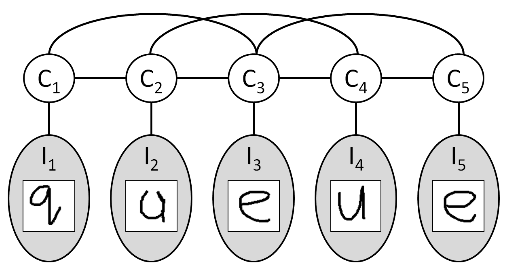
factors = ComputeTripletFactors (images, tripletList, K):
实验3的内容。这个函数主要是求三元组形式的factor,每个单词的长度为n,则返回一个n-2长度的factor列表,每张图片对应一个factor表,每个factor表有K^3项,里面的值按照tripletList里面的对应位置的参数给,其它值默认为1. 因为如果按照k^3来计算的话,则需要17576种组合,而其中很多种组合是不常见的,所以本次实验只给出了最常见的2000个组合的值。
实验3完成后执行下面语句:
[charAcc, wordAcc] = ScoreModel(allWords, imageModel, pairwiseModel, tripletList)
结果为:charAcc=81.62% ,wordAcc=37.00%. 有提高了一些。
sim = ImageSimilarity (im1, im2):
该函数为计算两张图片im1和im2之间的相似度。具体距离计算方法可以去查阅函数的代码,这个方法有点意思,不过主要还是在余弦距离上改进的。
factor = ComputeSimilarityFactor (images, K, i, j):
实验4的内容。这个factor的计算依据是:当2张图片非常相似时,则它们被预测为同一个字母的概率要大,反之要小。同理如果两张图片的所表示的字母是一样的,则它们之间的权重应该为这两张图片的相似度。images为一个单词的多张图片,i和j为这个图片集的某2个下标。这2张图片只生成一个factor,factor表格大小为K*K,如果是相同字母,则值为两者之间的相似度,否则为1.
factors = ComputeAllSimilarityFactors (images, K):
练习5的内容,该函数是计算一个单词图片序列的所有相似度factor,共有0.5*K*(K-1)个,每个factor表格大小为K*K. 实验过程可直接调用前面的函数:ComputeSimilarityFactor().
factors = ChooseTopSimilarityFactors (allFactors, F):
练习6的内容。该函数的作用是在所有的factor集(由两两组合构成)中选出相似度最大的F个。由于每一个factor的最大值在factor表中的对角线上,且有对角线上的值相同。所以随便取对角线上一个元素即可。
当然了,上面几次验证都是在相似度取top-2的情况下得到的,如果不考虑相似度,则运行:
[charAcc, wordAcc] = ScoreModel(allWords, imageModel, pairwiseModel, tripletList)
结果为:
charAcc=80.03% ,wordAcc=34.00%.
那么如果采用top-4效果会不会考些呢?
依旧运行下面程序:
[charAcc, wordAcc] = ScoreModel(allWords, imageModel, pairwiseModel, tripletList)
则结果为:charAcc=81.77% ,wordAcc=36.00%.比top-2时小效果还要稍微低一点,也就是说并不是top数越高越好。另外,如果你将top数设置太大,则计算量太大,很容易电脑就内存不够挂掉。
实验总结:
由本次实验可知,在真正使用CRF时,我们需要学习imageModel, pairwiseModel, tripletList这些参数,这当然是通过大量训练样本来学习的,且相似度超参数top-F中的F也是需要手动去调的。另外,即使已经学习到了这些模型的参数,在用CRF对测试样本进行预测时也是需要很多步骤的。而在本次实验中,参数的学习以及模型的预测使用方法都是已知的,老师在该实验设计时简化了不少内容。不过在后续的实验过程中会陆续的补上。
如果遇到下列错误:
dlopen: cannot load any more object with static TLS
解决方法是:在matlab下,依次进入Preferences > General > Java-Heap Memory.增加这个内容,具体我也不知道该要用多少,所以我干脆土豪了一把,拉到最大了。然后重启matlab,如果还不行就重启电脑。
如果在linux下,上面的方法可能不奏效,解决这个bug的方法可以参考官方的bug解法方法,下载那个.zip并解压后得到libiomp5.so文件,然后替换matlab按照目录下的~/R2013b/sys/os/glnxa64/libiomp5.so,重启matlab即可。
The doinference command failed. Look at the file inf.log to diagnose the cause.
跟踪定位到出错的那一句,发现是在函数RunInference()里面,因为有使用系统命令语句:
[retVal, output] = system(command);
而该语句是要使目录下的文件doinference-linux,该文件不具有可执行权限,因此先用chmod对该文件设置为可执行后就ok了。
参考资料: