前言
本次读的文章是与feature learning相关,feature learning也叫做deep learning,是最近一个比较热门的话题。因为它可以无监督的学习到图片和视频的一些特征(当然在其它领域也可以,比如语音,语言处理等),而这些特征并不需要人为手动去设。手动设计的特征,常见的有sift,surf,hog等,它们都是经过了很长的时间才设计出来的,并且它只适应于2D的图片,如果把所需学习的目标换成视频,则也同样需要把这些算法扩展到3D,比如HOG3D,3Dsurf,这个扩展过程也是需要很多技巧和时间的。另外,手动设计的某一特征只对某些数据库表现好,而对其它的数据库效果并不能保证就好。手动设计特征的第二个缺点就是,当把数据换成某个领域的其它数据,比如说Kinect深度图像,视频数据,多结构数据等,那么以前存在的那些手动设计的的特征点就表现更差了,也就是说换了一个非RGB领域的数据,这些特征点就不适应了,因此又得重新设计,这不太划算了。第三个缺点是手动设计的提取过程所花时间很长,不利用大数据特征的提取。当然了,deep learning一般是学习的层次结构,它也是有一定理论依据的,即模拟人脑的大脑皮层工作,因为大脑皮层的视觉区域也是分层次工作的,越底层的视觉皮层对那些底层特征就越敏感。综上所述,feature learning有这么多应用需求的驱动和生物神经理论上的支持,注定它能够在AI领域中发挥一定的作用。一些实验表明,有些feature learning学习到的特征几乎比所有其它的特征效果要好,比如本文中的ISA模型就是其中一个。
Natural image中的ISA模型
下面来看看ISA模型在二维自然图片中的模型,如下所示:

其中图中的第一层是输入图像的path,第二层其实是ISA的第一层输出,第二层和第一层之间的W就是我们需要learn的权值,第二层和输出层第三层的权值V是固定的,是不需要学习的,可以看到第二层的2个绿色的圈和第三层红色圈中的一个相邻,所以这里的子空间个数为2。第一层的输入是把图像的二维patch变成一个一维的向量。当然这个W的学习过程就是在优化图中下面那个公式,并且满足权值矩阵W是正交矩阵。
如果把权值矩阵的每一行反过来变成一个二维的patch图片,则这些小的patch图片就是我们在ISA的第一个输出层完成后学习到的特征图片,如下图所示:

从图中下面的英文解释可以看出,这些学习到的patch有2个特征,第一是它对一些edge比较敏感,也就是说它们是一些edge的检测算子。第二个特征是是相邻的2个patch之间具有类似的特征,比如说都是检测水平方向上的edge,或者都是检测垂直方向上的edge。
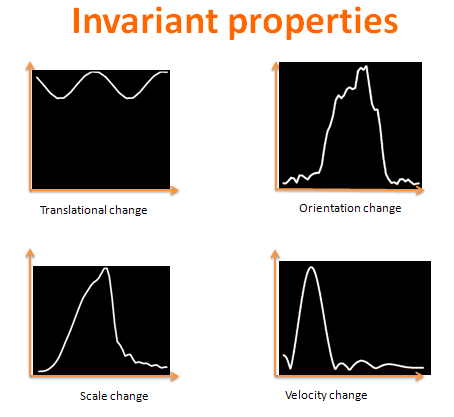
另外这些学习到的patch具有对输入图像的平移不敏感,但是对输入图像的频率和旋转非常敏感,所以说这些学习到的patch是可以识别一些不同频率不同旋转角度的图像的。这些patch的3个特征的曲线测试图如下所示:

Natural video中的ISA模型
上面的ISA模型是针对于二维图像而言的,当直接把这个模型扩展到3维的视频数据中会碰到很大的困难,因为一个视频数据就相当于一个长方体,那么这个长方体的维数就非常大,如果我们直接把一个视频数据变成一个一维的向量输入到ISA模型的第一层,就会发现这个输入向量的维度非常大,因而W的列数就非常大,这样在训练W参数的过程中由于需要计算有关W的特征向量等一系列过程,这些过程的时间复杂度是与输入向量的维数成3次方成正比,因而其计算速度非常之慢。所以作者在解决这个问题的时候采用的方法是:不一次输入一个视频的所以数据,而是在视频长方体中截取一个小的长方体patch,把这个patch变成向量后输入到ISA模型中,此时的ISA输入向量的维数就会大大降低,并且作者还使用了PCA进行降维,其维度会变得更低。另一方面,作者使用一些训练视频patch训练出一个ISA模型后,就把这些模型直接复制到旁边,这样就有多个这样的ISA模型,然后把它们的输出直接当做第二个’大’的ISA模型的输入(当然这中间也是需要经过PCA白化的),接着对第二个模型采用同样的方法进行训练,直到收敛。最后第二个ISA模型的输出就是最终的特征向量了。第二层的W同样也是多个视频patch,后面会提到。这里的两层ISA模型也就是作者在论文中所讲的Stacked convolutional ISA。其结构如下:

当然了,如果是训练好了这2个ISA模型的参数W,就可以对新来的视频数据进行测试了,对新来的视频提取出特征向量的示意图如下所示:

可以看出,作者是将2个ISA层的输出联合起来作为最终的特征向量,因为这样可以提高识别的准确率。
另外还有两点需要提到的是:1. 作者训练ISA模型中的参数是采用的批量投影梯度下降法,其具体的优化过程论文中并没有讲,我也没继续深入去研究过,按照道理来说,这个优化算法应该是个比较经典的算法。2. 对第一层ISA的红色圈输出,并不是所有的输出值都有采用,因为有些输出值较小,说明其响应较小,就应该去掉。所以作者对这个值设定了一个阈值,阈值的选取是通过实验的交叉验证得到的。
学习到的特征的分析
论文的后面部分对ISA模型中学习到的2层patch进行了下分析,第一层模型学习到的patch如下:

这些特征和在二维的图片中学习到的特征图片类似,这里每一组有10个patch说明输入的视频patch中时间维度上是取的10帧。当然了,这些从视频数据学习到特征也是具备对图像的平移不敏感,对图像的尺度变化,速度变化,旋转变化非常敏感。
这些特征的曲线测试如下图所示:
作者还从统计上求出了那些响应大的神经元所对应视频数据的旋转角度和速度的点的分布情况,如下图所示:
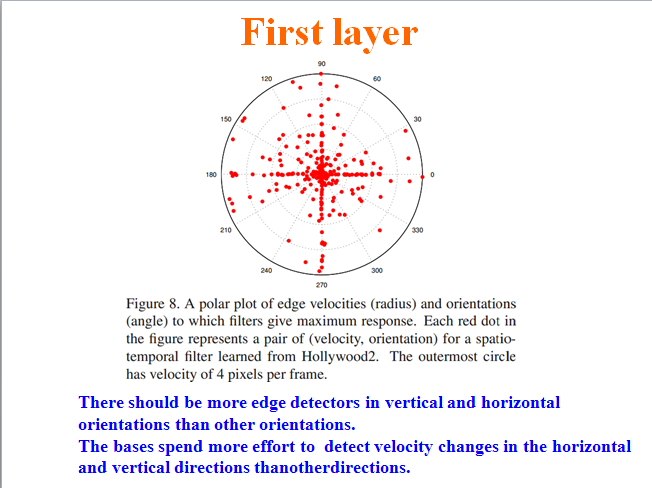
从图中可以看出来,学习到的底层特征在水平方向和垂直方向上的最多。
高层学习到的特征更为复杂,但是不容易解释,如下图所示:

实验结果
作者在UCF,Hollywood2,Youtube,KTH这4个出名且很有挑战的数据库上做了测试,其测试结果表明,作者提出的算法比在此之前的其它算法的最好结果都要好,这是一个比较令人惊讶的地方。其算法准确度结果如下:

总结
feature learning的学习能力还是非常强的,应该是以后的研究热点,相应以后还会大大提高它在AI各个领域的作用。
附录
参考资料