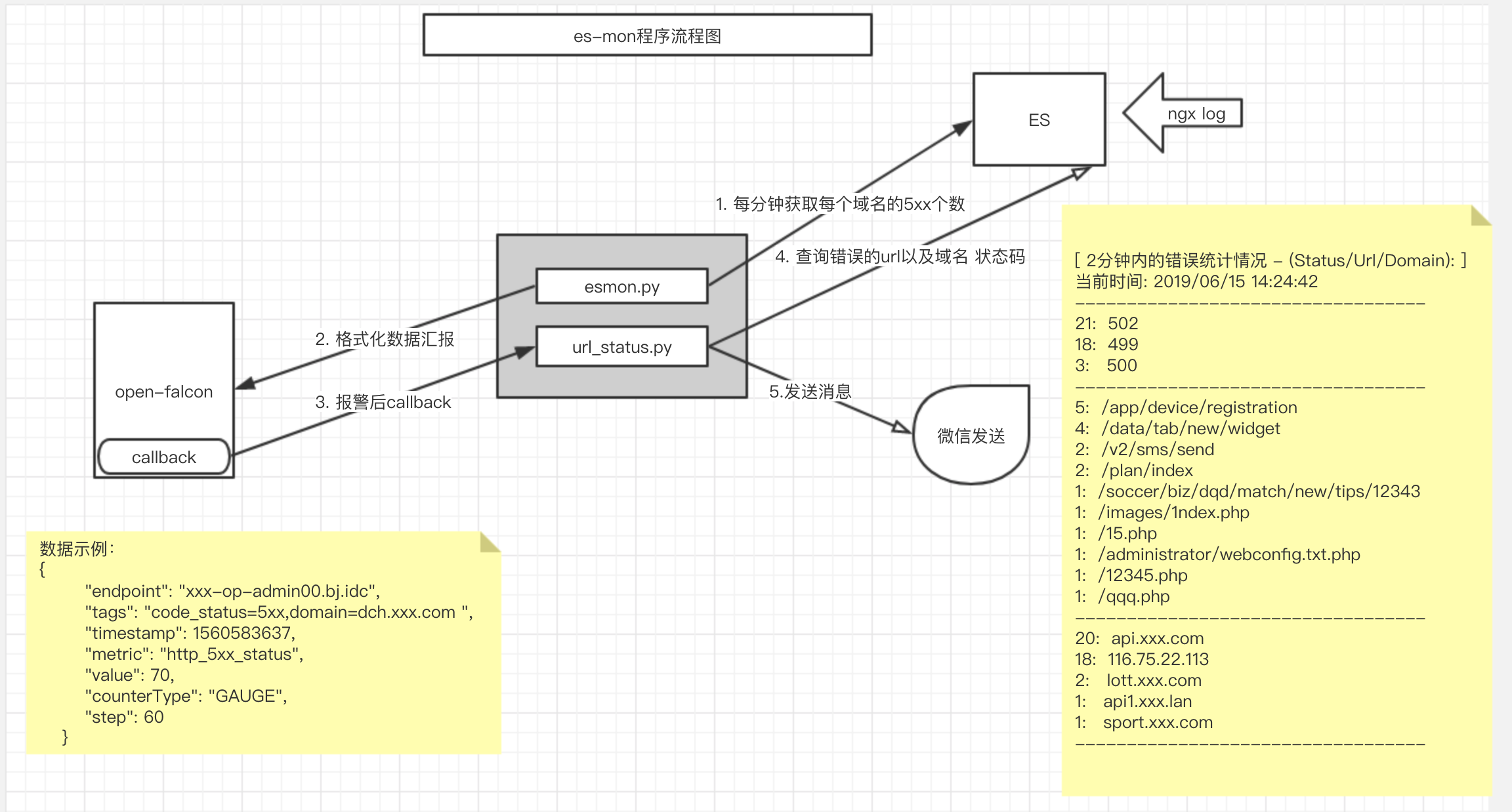
背景: 如果我们运维的是web网站, 那么http的状态码是必须要监控的,当出现4xx 5xxx的状态码的时候需要能发出报警,然后定位问题。当我们监控nginx的状态码出现错误状态码的时候, 一般的处理方法是通过kibana查询是哪个接口导致从而确定是哪个服务,再进一步登录业务机器查询业务日志确定原因。我们现在要做的事情就是将 人为的通过kibana查询改造为程序自动发送,这样研发就可以直接登录对应相应的业务机器查询日志定位原因,减少了运维的人工介入,很大程度的提高了效率。
我们采用的是如下的方法:
- 在应用服务器上使用filebeat 收集 499 TO 599 的状态码的请求 存储到ES中
- 使用脚本计算每分钟每个域名的 error_code 数量 ,汇报到open-falcon监控系统
- 使用open-falcon 系统设置每个域名的阈值,比如超过1分钟超过100个则报警
- 使用open-falcon的报警call back 功能,触发 脚本接口,脚本接口查询汇总错误域名/url/数量发送到企业微信
- 研发通过报错的域名和url 定位服务问题
此方案的优点在于成本比较小,如果您是大公司,完全可以收集所有的日志。
总体思路和程序流程如下: