- 对于Redis主从复制,数据值每个服务器都存了。
- 客户端连接这个集群,不用在乎Master了
Redis好处:
1. 减轻db压力
2. RDB(间隔,非实时); AOF(日志形式记录,实时)如果在项目 断电(不会保存)和 停止redis redis停止时候会保存就rdb日志文件, rdb是独立进程实现的。
Redis 集群方案
注意: Redis3.0 之前 不支持redis集群
1、客户端分片技术(mycat,没有故障转移功能)
2、主从复制实现的集群,缺点数据冗余!
3、redis强烈推荐 redis-cluster (redis3.0之后实现的)
三台独立的 redis 服务器
卡槽:0 - 16384位置
分析: "set name ok ",如何存储呢?
根据客户端的key 进行算法 计算出一个数字 取模 卡槽总数(16384) 得出来的值 映射到对应的卡槽
比如有3台redis,每个卡槽均匀分布。客户端随便连接一台redis,执行get name时候 ,根据key 通过算法得到数字,自动转到实际值存储的那一台。
集群方案:
1. 3.0版本之前
- 3.0版本之前的redis是不支持集群的,我们的redis如果想要集群的话,就需要一个中间件,然后这个中间件负责将我们需要存入redis中的数据的key通过一套算法计算得出一个值。然后根据这个值找到对应的redis节点,将这些数据存在这个redis的节点中。
- 在取值的时候,同样先将key进行计算,得到对应的值,然后就去找对应的redis节点,从对应的节点中取出对应的值。
- 这样做有很多不好的地方,比如说我们的这些计算都需要在系统中去进行,所以会增加系统的负担。还有就是这种集群模式下,某个节点挂掉,其他的节点无法知道。而且也不容易对每个节点进行负载均衡。
2. 常见集群方案
1.官方方案redis-cluster搭建实战
2.客户端分片技术(不推荐),扩容/缩容时,必须手动调整分片程序,出现故障不能自动转移
3.可以使用主从复制方式(不推荐)
4.使用一些代理工具
关于Redis-cluster原理
- Redis 是一个开源的 key-value 存储系统,由于出众的性能,大部分互联网企业都用来做服务器端缓存。Redis 在3.0版本前只支持单实例模式,虽然支持主从模式、哨兵模式部署来解决单点故障,但是现在互联网企业动辄大几百G的数据,可完全是没法满足业务的需求,所以,Redis 在 3.0 版本以后就推出了集群模式。
- Redis 集群采用了P2P的模式,完全去中心化。Redis 把所有的 Key 分成了 16384 个 slot,每个 Redis 实例负责其中一部分 slot 。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。Redis 客户端可以在任意一个 Redis 实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
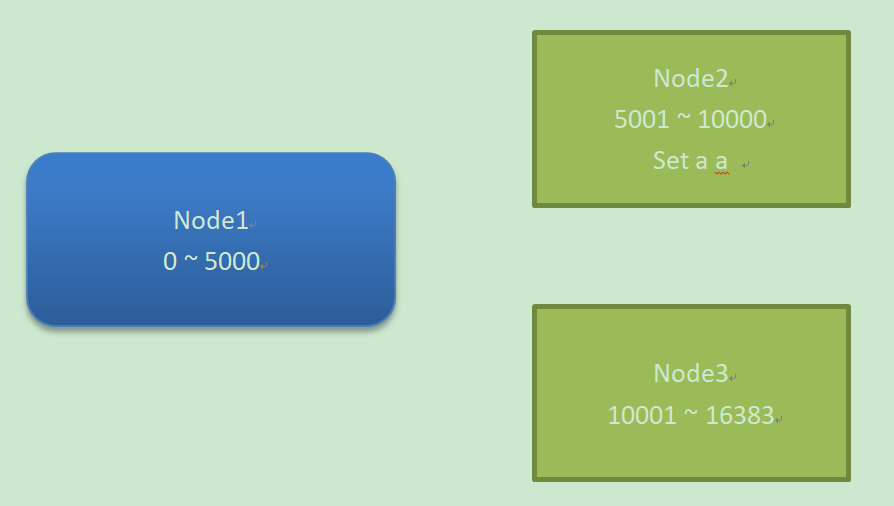
集群搭建时候,需要给集群的节点分配插槽, 0 ~ 1683
在node1 执行 set a a
- 使用crc16算法对key进行计算,得到一个数字,然后对这个数字进行求余进行求余 16384. crc16 :a = 26384, 26384%16384 = 10000
- 查找包含10000插槽的节点,找到了Node2,自动跳转到Node2
- 在Node2上执行 set a a 命令
在Node3上执行 get a
- a --> 10000
- 跳转到Node2
- 在Node2执行 get a
在这个图中:
每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。
解释:
那么redis是怎么做到的呢?
1.首先,在redis的每一个节点上,都有这么两个东西,一个是插槽(slot)可以理解为是一个可以存储两个数值的一个变量这个变量的取值范围是:0-16383。还有一个就是cluster我个人把这个cluster理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
还有就是因为如果集群的话,是有好多个redis一起工作的,那么,就需要这个集群不是那么容易挂掉,所以呢,理论上就应该给集群中的每个节点至少一个备用的redis服务。这个备用的redis称为从节点(slave)。那么这个集群是如何判断是否有某个节点挂掉了呢?
2.首先要说的是,每一个节点都存有这个集群所有主节点以及从节点的信息。
3.它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的节点去ping一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。如果某个节点和所有从节点全部挂掉,我们集群就进入faill状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入发力了状态。这就是我们的redis的投票机制,具体原理
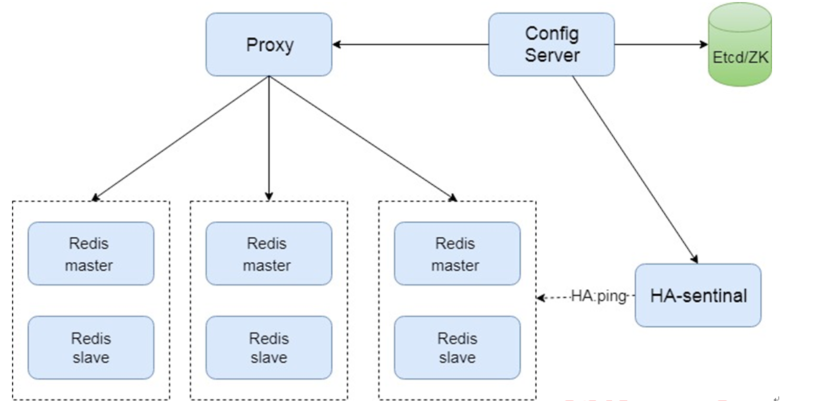
这套架构的特点:
- 分片算法:基于 slot hash桶;
- 分片实例之间相互独立,每组 一个master 实例和多个slave;
- 路由信息存放到第三方存储组件,如 zookeeper 或etcd
- 旁路组件探活