一、 进程创建:
Unix 下的进程创建很特别,与许多其他操作系统不同,它分两步操作来创建和执行进程: fork() 和 exec() 。首先,fork() 通过拷贝当前进程创建一个子进程;然后,exec() 函数负责读取可执行文件并将其载入地址空间开始运行。
1、fork() :kernel/fork.c
在Linux系统中,通过调用fork()来创建一个进程。调用 fork() 的进程称为父进程,新产生的进程称为子进程。在该调用结束时,在返回点这个相同的位子上,父进程恢复执行,子进程开始执行。fork()系统调用从内核返回两次:一次返回到父进程,另一次返回到新产生的子进程。使用fork()创建新进程的流程如下:
1)fork() 调用clone;
2)clone() 调用 do_fork();
3)do_fork() 调用 copy_process() 函数,copy_process() 函数将完成第 4-11 步;
4)调用 dup_task_struct() 为新进程创建一个内核栈、thread_info结构和task_struct,这些值与当前进程的值相同;
5)检查并确保新创建这个子进程后,当前用户所拥有的进程数目没有超出给它分配的资源的限制;
6)清理子进程进程描述符中的一些成员(清零或初始化,如PID),以使得子进程与父进程区别开来;
7)将子进程的状态设置为 TASK_UNINTERRUPTIBLE,保证它不会投入运行;
8)调用 copy_flags() 以更新 task_struct 的 flags 成员;
9)调用 alloc_pid() 为新进程分配一个有效的 PID;
10)根据传递给clone() 的参数标志,copy_process() 拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等;
11)做一些扫尾工作并返回一个指向子进程的指针。
12)回到 do_fork() 函数,如果 copy_process() 函数成功返回,新创建的子进程将被唤醒并让其投入运行。
下面用一段简单的代码演示一下 fork() 函数:
1 #include <unistd.h> 2 #include <stdio.h> 3 4 int main(){ 5 pid_t fpid; 6 int count= 0; 7 fpid = fork(); // fpid 为fork()的返回值 8 if(fpid < 0){ // 当fork()的返回值为负值时,表明调用 fork() 出错 9 printf("error in fork!"); 10 } 11 else if(fpid == 0){ // fork() 返回值为0,表明该进程是子进程 12 printf("this is a child process, the process id is %d ",getpid()); 13 count++; 14 } 15 else{ // fork() 返回值大于0,表明该进程是父进程,这时返回值其实是子进程的PID 16 printf("this is a father process, the process id is %d ",getpid()); 17 count++; 18 } 19 printf("计数 %d 次 ",count); 20 return 0; 21 }
输出结果:

可以看到,调用 fork() 函数后,原本只有一个进程,变成了两个进程。这两个进程除了 fpid 的值不同外几乎完全相同,它们都继续执行接下来的程序。由于 fpid 的值不同,因此会进入不同的判断语句,这也是为什么两个结果有不同之处的原因。另外,可以看到,父进程的 PID 刚好比子进程的 PID 小1。 fork() 的返回值有以下三种:
a)在父进程中,fork() 返回新创建子进程的 PID;
b)在子进程中,fork() 返回0;
c)如果 fork() 调用出错,则返回负值
2、exec() :fs/exec.c (源程序 exec.c 实现对二进制可执行文件和 shell 脚本文件的加载与执行)
通常,创建新的进程都是为了立即执行新的、不同的程序,而接着调用 exec() 这组函数就可以创建新的地址空间,并把新的程序载入其中。
exec() 并不是一个函数,而是一个函数簇,一共包含六个函数,分别为: execl、execlp、execle、execv、execvp、execve,定义如下:
#include <unistd.h> int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char *const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execve(const char *path, char *const argv[], char *const envp[]);
这六个函数的功能其实差不多,只是接受的参数不同。exec() 函数的参数主要有3个部分:执行文件部分、命令参数部分和环境变量部分:
1)执行文件部分:也就是函数中的 path 部分,该部分指出了可执行文件的查找方式。其中 execl、execle、execv、execve的查找方式都是使用的绝对路径,而 execlp和execvp则可以只给出文件名进行查找,系统会从环境变量 "$PATH"中查找相应的路径;
2)命令参数部分:也就是函数中的 file 部分,该部分指出了参数的传递方式以及要传递哪些参数。这里,"l"结尾的函数表示使用逐个列举的方式传递参数;"v"结尾的表示将所有参数整体构造成一个指针数组进行传递,然后将该数组的首地址当做参数传递给它,数组中的最后一个指针要求为 NULL;
3)环境变量部分:exec() 函数簇使用了系统默认的环境变量,也可以传入指定的环境变量。其中 execle 和execve 这两个函数就可以在 envp[] 中指定当前进程所使用的环境变量。
· 当 exec() 执行成功时,exec() 函数会取代执行它的进程,此时,exec() 函数没有返回值,进程结束。当 exec() 函数执行失败时,将返回失败信息(返回 -1),进程继续执行后面的代码。
通常,exec() 会放在 fork() 函数的子进程部分,来替代子进程继续执行,exec() 执行成功后子进程就会消失,但是执行失败的话,就必须要使用 exit() 函数来让子进程退出。下面用一段简单的代码来演示一下 exec() 函数簇中的一个函数的用法,其余的参考:https://www.cnblogs.com/dongguolei/p/8098181.html
1 #include <unistd.h> 2 #include <stdio.h> 3 #include <errno.h> 4 #include <string.h> 5 6 int main(){ 7 int childpid; 8 pid_t fpid; 9 fpid = fork(); 10 if(fpid == 0){ // 子进程 11 char *execv_str[] = {"ps","aux",NULL}; // 指令:ps aux 查看系统中所有进程 12 if( execv("/usr/bin/ps",execv_str) < 0 ){ 13 perror("error on exec "); 14 exit(0); 15 } 16 } 17 else{ 18 wait(&childpid); 19 printf("execv done "); 20 } 21 }
在这个程序中,使用 fork() 创建了一个子进程,随后立即调用 exec() 函数簇中的 execv() 函数,execv() 函数执行了一条指令,显示当前系统中所有的进程,结果如下(进程有很多,这里只截了一部分):
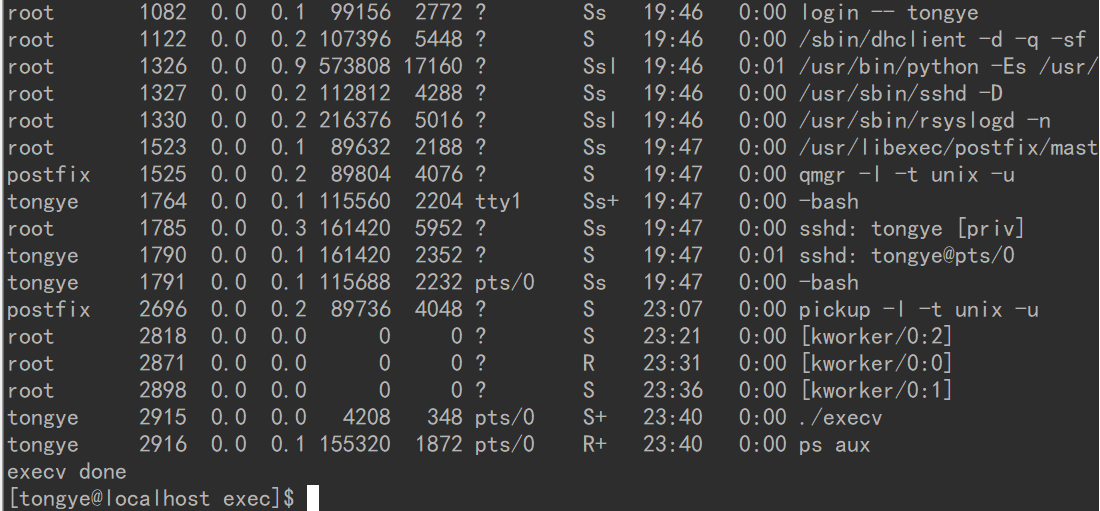
注意看最后两个进程,分别是父进程和调用 fork() 后创建的子进程。
二、进程终结
进程被创建后,最终要终结。当一个进程终结时,内核必须释放它所占有的资源,并把这一消息告诉其父进程。系统通过 exit() 系统调用来处理终止和退出进程的相关工作,而大部分工作则由 do_exit() 来完成 (kernel/exit.c):
1)将task_struct 中的标志成员设置为 PF_EXITING;
2)调用 del_timer_sync() 删除任一内核定时器,以确保没有定时器在排队,也没有定时器处理程序在运行;
3)调用 exit_mm() 函数释放进程占用的 mm_struct,如果没有别的进程使用它们(地址空间被共享),就彻底释放它们;
4)调用 sem__exit() 函数,如果进程排队等候 IPC 信号,它则离开队列;
5)调用 exit_files() 和 exit_fs(),以分别递减文件描述符、文件系统数据的引用计数,若其中某个引用计数的值降至零,则表示没有进程使用相应的资源,可以释放掉进程占用的文件描述符、文件系统资源;
6)把 task_struct 的 exit_code 成员设置为进程的返回值;
7)调用 exit_notify() 向父进程发送信号,并把进程状态设置为 EXIT_ZOMBIE;
8)调用 schedule() 切换到新的进程,继续执行。由于 EXIT_ZOMBIE 状态的进程不会被再调度,所以这是进程所执行的最后一段代码, do_exit() 没有返回值。
至此,与进程相关联的所有资源都被释放掉了,进程不可运行并处于 EXIT_ZOMBIE 退出状态。此时,进程本身所占用的内存还没有释放,如内核栈、thread_info 结构和 task_struct 结构等,它存在的意义是向父进程提供信息,当父进程收到信息后,或者通知内核那是无关的信息后,进程所持有的剩余的内存将被释放。父进程可以通过 wait4() 系统调用查询子进程是否终结,这其实使得进程拥有了等待特定进程执行完毕的能力。
系统通过调用 release_task() 来释放进程描述符。