一、多道技术
1.多路复用
操作系统主要使用来
- 记录哪个程序使用什么资源
- 对资源请求进行分配
- 为不同的程序和用户调解互相冲突的资源请求。
我们可将上述操作系统的功能总结为:
处理来自多个程序发起的多个(多个即多路)共享(共享即复用)资源的请求,简称多路复用。
2.时间上的复用
当一个资源在时间上复用时,不同的程序或用户轮流使用它,第一个程序获取该资源使用结束后,在轮到第二个。。。第三个。。。
例如:只有一个cpu,多个程序需要在该cpu上运行,操作系统先把cpu分给第一个程序,在这个程序运行的足够长的时间(时间长短由操作系统的算法说了算)或者遇到了I/O阻塞,操作系统则把cpu分配给下一个程序,以此类推,直到第一个程序重新被分配到了cpu然后再次运行,由于cpu的切换速度很快,给用户的感觉就是这些程序是同时运行的,或者说是并发的,或者说是伪并行的。至于资源如何实现时间复用,或者说谁应该是下一个要运行的程序,以及一个任务需要运行多长时间,这些都是操作系统的工作。
3.空间上的复用
每个客户都获取了一个大的资源中的一小部分资源,从而减少了排队等待资源的时间。
例如:多个运行的程序同时进入内存,硬件层面提供保护机制来确保各自的内存是分割开的,且由操作系统控制,这比一个程序独占内存一个一个排队进入内存效率要高的多。
有关空间复用的其他资源还有磁盘,在许多系统中,一个磁盘同时为许多用户保存文件。分配磁盘空间并且记录谁正在使用哪个磁盘块是操作系统资源管理的典型任务。
3.多道程序系统
(1)多道程序设计技术
所谓多道程序设计技术,就是指允许多个程序同时进入内存并运行。即同时把多个程序放入内存,并允许它们交替在CPU中运行,它们共享系统中的各种硬、软件资源。当一道程序因I/O请求而暂停运行时,CPU便立即转去运行另一道程序。
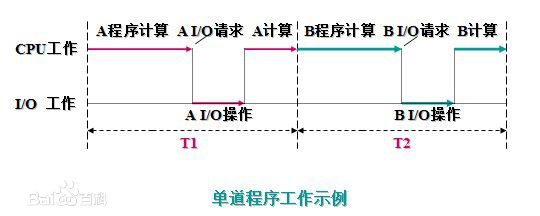
单道程序的运行过程:
在A程序计算时,I/O空闲, A程序I/O操作时,CPU空闲(B程序也是同样);必须A工作完成后,B才能进入内存中开始工作,两者是串行的,全部完成共需时间=T1+T2。
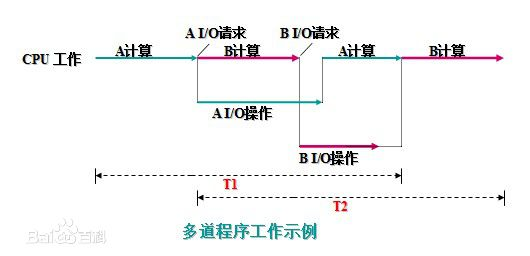
多道程序的运行过程:
将A、B两道程序同时存放在内存中,它们在系统的控制下,可相互穿插、交替地在CPU上运行:当A程序因请求I/O操作而放弃CPU时,B程序就可占用CPU运行,这样 CPU不再空闲,而正进行A I/O操作的I/O设备也不空闲,显然,CPU和I/O设备都处于“忙”状态,大大提高了资源的利用率,从而也提高了系统的效率,A、B全部完成所需时间<<T1+T2。
多道程序设计技术不仅使CPU得到充分利用,同时改善I/O设备和内存的利用率,从而提高了整个系统的资源利用率和系统吞吐量(单位时间内处理作业(程序)的个数),最终提高了整个系统的效率。
单处理机系统中多道程序运行时的特点:
- 多道:计算机内存中同时存放几道相互独立的程序;
- 宏观上并行:同时进入系统的几道程序都处于运行过程中,即它们先后开始了各自的运行,但都未运行完毕;
- 微观上串行:实际上,各道程序轮流地用CPU,并交替运行。
多道程序系统的出现,标志着操作系统渐趋成熟的阶段,先后出现了作业调度管理、处理机管理、存储器管理、外部设备管理、文件系统管理等功能。

4.多道技术
内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)。
二、进程
1.什么是进程
程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。正是这样的设计,大大提高了CPU的利用率。进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
2.进程与程序的区别
程序仅仅只是一堆代码而已,而进程指的是程序的运行过程。
举例:
想象一位有一手好厨艺的计算机科学家egon正在为他的女儿元昊烘制生日蛋糕。
他有做生日蛋糕的食谱,
厨房里有所需的原料:面粉、鸡蛋、韭菜,蒜泥等。
在这个比喻中:
- 做蛋糕的食谱就是程序(即用适当形式描述的算法)
- 计算机科学家就是处理器(cpu)
- 而做蛋糕的各种原料就是输入数据。
进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。
需要强调的是:同一个程序执行两次,那也是两个进程,比如打开暴风影音,虽然都是同一个软件,但是一个可以播放苍井空,一个可以播放饭岛爱。
3.并发与并行
并行:同时运行,只有具备多个cpu才能实现并行。
并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)。

4.同步与异步
同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;
异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
举个例子,打电话时就是同步通信,发短息时就是异步通信。
5.进程的创建与终止
而对于通用系统,需要由系统运行过程中创建或撤销进程的能力,主要分为四种形式创建新的进程:
- 系统初始化(查看进程linux中用ps命令,windows中用任务管理器,前台进程负责与用户交互,后台运行的进程与用户无关,运行在后台并且只在需要时才唤醒的进程,称为守护进程,如电子邮件、web页面、新闻、打印)
- 一个进程在运行过程中开启了子进程(如nginx开启多进程,os.fork, subprocess.Popen等)
- 用户的交互式请求,创建一个新进程(如用户双击暴风影音)
- 一个批处理作业的初始化(只在大型机的批处理系统中应用)
无论哪一种,新进程的创建都是由一个已经存在的进程执行了一个用于创建进程的系统调用而创建的:
- 在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
- 在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
关于创建的子进程,UNIX和windows
- 相同的是:进程创建后,父进程和子进程有各自不同的地址空间(多道技术要求物理层面实现进程之间内存的隔离),任何一个进程的在其地址空间中的修改都不会影响到另外一个进程。
- 不同的是:在UNIX中,子进程的初始地址空间是父进程的一个副本,提示:子进程和父进程是可以有只读的共享内存区的。但是对于windows系统来说,从一开始父进程与子进程的地址空间就是不同的。
进程的终止:
- 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
- 出错退出(自愿,python a.py中a.py不存在)
- 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
- 被其他进程杀死(非自愿,如kill -9)
5.进程的层次结构
无论UNIX还是windows,进程只有一个父进程,不同的是:
- 在UNIX中所有的进程,都是以init进程为根,组成树形结构。父子进程共同组成一个进程组,这样,当从键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员。
- 在windows中,没有进程层次的概念,所有的进程都是地位相同的,唯一类似于进程层次的暗示,是在创建进程时,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程,但是父进程有权把该句柄传给其他子进程,这样就没有层次了。
6.进程的状态
tail -f access.log |grep '404'
执行程序tail,开启一个子进程,执行程序grep,开启另外一个子进程,两个进程之间基于管道'|'通讯,将tail的结果作为grep的输入。
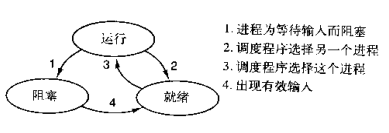
进程grep在等待输入(即I/O)时的状态称为阻塞,此时grep命令都无法运行
其实在两种情况下会导致一个进程在逻辑上不能运行,
- 进程挂起是自身原因,遇到I/O阻塞,便要让出CPU让其他进程去执行,这样保证CPU一直在工作
- 与进程无关,是操作系统层面,可能会因为一个进程占用时间过多,或者优先级等原因,而调用其他的进程去使用CPU。
因而一个进程由三种状态:
7.进程并发的实现
进程并发的实现在于,硬件中断一个正在运行的进程,把此时进程运行的所有状态保存下来,为此,操作系统维护一张表格,即进程表(process table),每个进程占用一个进程表项(这些表项也称为进程控制块)。

该表存放了进程状态的重要信息:程序计数器、堆栈指针、内存分配状况、所有打开文件的状态、帐号和调度信息,以及其他在进程由运行态转为就绪态或阻塞态时,必须保存的信息,从而保证该进程在再次启动时,就像从未被中断过一样。
三、线程
1.什么是线程
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间。
进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位,
例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
2.有了进程为什么还要线程?
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
- 进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
- 进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
3.为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务公用一块地址空间,那么必须在一个进程内开启多个线程。
详细的讲分为4点:
- 多线程共享一个进程的地址空间
- 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
- 对于计算/cpu密集型应用,多线程并不能提升性能,但对于I/O密集型应用,使用多线程会明显地提升速度(I/O密集型根本用不上多核优势)
- 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程(比开进程开销要小的多)
计算密集型
(1)特点:要进行大量的计算,消耗CPU资源。比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。
(2)计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
(3)计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
IO密集型
(1)涉及到网络、磁盘IO的任务都是IO密集型任务。
(2)特点:CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。
(3)对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
(4)IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
4.进程与线程的区别
(1)Threads share the address space of the process that created it; processes have their own address space.
线程共享创建它的进程的地址空间;进程有自己的地址空间。
(2)Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
线程直接访问进程的数据段;进程拥有父进程的数据段的自身副本。
(3)Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
线程可以直接与其他线程的通信;进程必须使用进程间通信与兄弟姐妹的通信。
(4)New threads are easily created; new processes require duplication of the parent process.
很容易创建新线程;新进程需要重复父进程。
(5)Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
线程可以对相同进程的线程进行相当的控制;进程只能对子进程进行控制。
(6)Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
对主线程的更改(取消、优先级更改等)可能影响进程的其他线程的行为;对父进程的更改不会影响子进程。
5.用户级与内核级线程的对比
(1)用户级线程和内核级线程的区别
- 内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
- 用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
- 用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
- 在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
- 用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
(2)内核线程的优缺点
优点:
当有多个处理机时,一个进程的多个线程可以同时执行。
缺点:
由内核进行调度。
(3)用户进程的优缺点
优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多。
允许每个进程定制自己的调度算法,线程管理比较灵活。
线程能够利用的表空间和堆栈空间比内核级线程多。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起。另外,页面失效也会产生同样的问题。
缺点:
资源调度按照进程进行,多个处理机下,同一个进程中的线程只能在同一个处理机下分时复用
四、Python GIL(Global Interpreter Lock)
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
上面的核心意思就是,无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行。
1.为什么会有GIL
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,本且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
2.GIL的影响
从上文的介绍和官方的定义来看,GIL无疑就是一把全局排他锁。毫无疑问全局锁的存在会对多线程的效率有不小影响。甚至就几乎等于Python是个单线程的程序。
那么读者就会说了,全局锁只要释放的勤快效率也不会差啊。只要在进行耗时的IO操作的时候,能释放GIL,这样也还是可以提升运行效率的嘛。或者说再差也不会比单线程的效率差吧。理论上是这样,而实际上呢?Python比你想的更糟。
下面我们就对比下Python在多线程和单线程下得效率对比。测试方法很简单,一个循环1亿次的计数器函数。一个通过单线程执行两次,一个多线程执行。最后比较执行总时间。测试环境为双核的PC。
注:为了减少线程库本身性能损耗对测试结果带来的影响,这里单线程的代码同样使用了线程。只是顺序的执行两次,模拟单线程。
顺序执行的单线程(single_thread.py)
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
同时执行的两个并发线程(multi_thread.py)
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
thread_array[tid] = t
for i in range(2):
thread_array[i].join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
运行结果(测试10次的平均值):
single_thread.py
Total time: 20.728185653686523
multi_thread.py
Total time: 20.755187034606934
3.如何避免受到GIL的影响
(1)用multiprocess替代Thread
multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。
当然multiprocess也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量,对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocess由于进程之间无法看到对方的数据,只能通过在主线程申明一个Queue,put再get或者用share memory的方法。这个额外的实现成本使得本来就非常痛苦的多线程程序编码,变得更加痛苦了。
(2)用其他解析器
之前也提到了既然GIL只是CPython的产物,那么其他解析器是不是更好呢?没错,像JPython和IronPython这样的解析器由于实现语言的特性,他们不需要GIL的帮助。然而由于用了Java/C#用于解析器实现,他们也失去了利用社区众多C语言模块有用特性的机会。所以这些解析器也因此一直都比较小众。