Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
作用:集中、转换和存储数据
官方网站:
https://www.elastic.co/cn/products/logstash
一个民间的中文Logstash最佳实践:
https://doc.yonyoucloud.com/doc/logstash-best-practice-cn/index.html
1.下载Logstash,版本为6.2.4,下载地址
https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz
2.解压到目录

3.启动Logstash进程,Hello World Demo
bin/logstash -e 'input { stdin { } } output { stdout {} }'
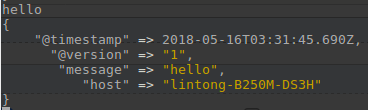
bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}'
输入:Hello World
输出:
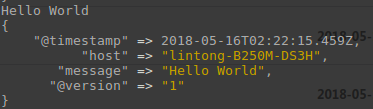
在这个Demo中,Hello World作为数据,在线程之间以 事件 的形式流传。不要叫行,因为 logstash 可以处理多行事件。
Logstash 会给事件添加一些额外信息。最重要的就是 @timestamp,用来标记事件的发生时间。因为这个字段涉及到 Logstash 的内部流转,所以必须是一个 joda 对象,如果你尝试自己给一个字符串字段重命名为 @timestamp 的话,Logstash 会直接报错。所以,请使用 filters/date 插件 来管理这个特殊字段。
此外,大多数时候,还可以见到另外几个:
- host 标记事件发生在哪里。
- type 标记事件的唯一类型。
- tags 标记事件的某方面属性。这是一个数组,一个事件可以有多个标签。
4.语法
Logstash 设计了自己的 DSL —— 有点像 Puppet 的 DSL,或许因为都是用 Ruby 语言写的吧 —— 包括有区域,注释,数据类型(布尔值,字符串,数值,数组,哈希),条件判断,字段引用等。
区段(section)
Logstash 用 {} 来定义区域。区域内可以包括插件区域定义,你可以在一个区域内定义多个插件。插件区域内则可以定义键值对设置。示例如下:
input {
stdin {}
syslog {}
}
数据类型
Logstash 支持少量的数据值类型:
bool debug => true
string host => "hostname"
number port => 514
array match => ["datetime", "UNIX", "ISO8601"]
hash
options => {
key1 => "value1",
key2 => "value2"
}
条件判断(condition)
表达式支持下面这些操作符:
equality, etc: ==, !=, <, >, <=, >=
regexp: =~, !~
inclusion: in, not in
boolean: and, or, nand, xor
unary: !()
比如:
if "_grokparsefailure" not in [tags] {
} else if [status] !~ /^2dd/ and [url] == "/noc.gif" {
} else {
}
命令行参数:logstash命令
参数: 执行 -e bin/logstash -e '' 文件 --config 或 -f bin/logstash -f agent.conf 测试 --configtest 或 -t 用来测试 Logstash 读取到的配置文件语法是否能正常解析。 日志 --log 或 -l Logstash 默认输出日志到标准错误。生产环境下你可以通过 bin/logstash -l logs/logstash.log 命令来统一存储日志。
使用Logstash的Kafka插件
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-kafka.html
启动一个kafka作为输入,并输入1231212
~/software/apache/kafka_2.11-0.10.0.0$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
stdin.conf文件
input{
kafka{
bootstrap_servers => ["127.0.0.1:9092"]
topics => [ 'test' ]
}
}
output {
stdout {
codec => rubydebug
}
}
启动logstash
bin/logstash -f stdin.conf
输出

关于auto_offset_reset参数:
由于Kafka是消息队列,消费过的就不会再消费
<i>可以在stdin.conf中设置auto_offset_reset="earliest",比如
input{
kafka{
bootstrap_servers => ["127.0.0.1:9092"]
topics => [ 'test' ]
auto_offset_reset => "earliest"
}
}
output {
stdout {
codec => rubydebug
}
}
在kafka中依次输入
1111 2222 3333
输出为,注意这里timestamp的时间是1111 -> 2222 -> 3333,logstash会从头开始消费没有消费的消息

<ii>当auto_offset_reset="latest"
logstash会从进程启动的时候开始消费消息,之前的消息会丢弃
在kafka中依次输入
1111 2222 3333
输出为
Kafka -> logstash -> Es的conf文件
input{
kafka{
bootstrap_servers => ["127.0.0.1:9092"]
topics => [ 'topicB' ]
auto_offset_reset => "earliest"
consumer_threads => 1
codec => json
}
}
output {
elasticsearch{
hosts => ["127.0.0.1:9200"]
index => "XXX"
}
}
Kafka -> logstash -> File的conf文件
参考
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-file.html
注意:如果是kafka输入是line格式的,使用codec => line { format => "custom format: %{message}"}
关于codec的说明
https://www.elastic.co/guide/en/logstash/6.2/codec-plugins.html
如果kafka输入是json格式的,使用codec => json
input{
kafka{
bootstrap_servers => ["127.0.0.1:9092"]
topics => [ 'topicB' ]
auto_offset_reset => "earliest"
consumer_threads => 1
codec => json
}
}
output {
stdout {
codec => rubydebug {}
}
file {
path => "/home/lintong/桌面/logs/path/to/1.txt"
#codec => line { format => "custom format: %{message}"}
codec => json
}
}
使用Logstash的HDFS插件
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-webhdfs.html
配置文件
input{
kafka{
bootstrap_servers => ["127.0.0.1:9092"]
topics => [ 'topicB' ]
auto_offset_reset => "earliest"
consumer_threads => 1
codec => json
}
}
output {
stdout {
codec => rubydebug {}
}
webhdfs {
host => "127.0.0.1" # (required)
port => 50070 # (optional, default: 50070)
path => "/user/lintong/xxx/logstash/dt=%{+YYYY-MM-dd}/logstash-%{+HH}.log" # (required)
user => "lintong" # (required)
codec => json
}
}
到 http://localhost:50070 下看文件内容
