1.首先在浏览器中进入WAP版微博的网址,因为手机版微博的内容较为简洁,方便后续使用正则表达式或者beautifulSoup等工具对所需要内容进行过滤
https://login.weibo.cn/login/
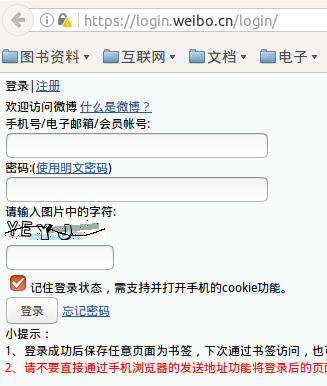
2.人工输入账号、密码、验证字符,最后最重要的是勾选(记住登录状态)
3.使用Wireshark工具或者火狐的HttpFox插件对GET请求进行分析,需要是取得GET请求中的Cookie信息
在未登录新浪微博的情况下,是可以通过网址查看一个用户的首页的,但是不能进一步查看该用户的关注和粉丝等信息,如果点击关注和粉丝,就会重定向回到登录页面
比如使用下面函数对某个用户 http://weibo.cn/XXXXXX/fans 的粉丝信息进行访问,会重定向回登录页面
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html

所以需要在请求的包中的headers中加入Cookie信息,
在勾选了记住登录状态之后,点击关注或者粉丝按钮,发出GET请求,并使用wireshark对这个GET请求进行抓包
可以抓到这个GET请求

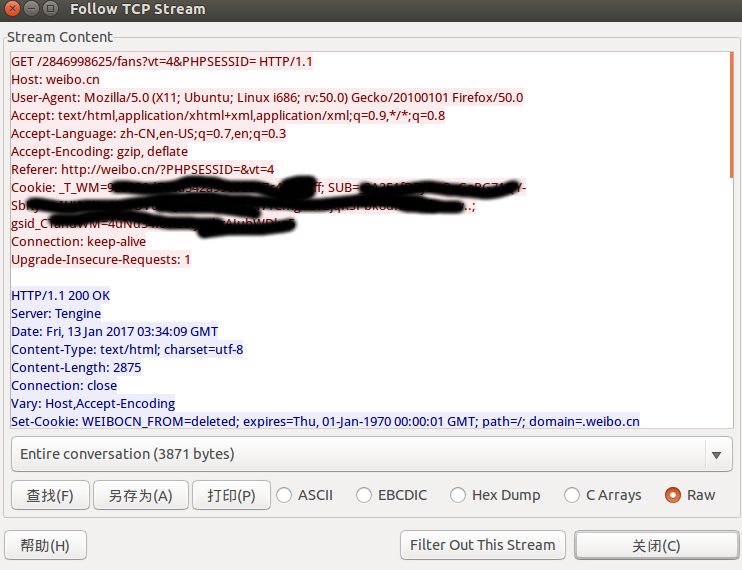
右键Follow TCP Stream,图片中打码的部分就Cookie信息
4.加入Cookie信息,重新获取网页
有了Cookie信息,就可以对Header信息就行修改
#获取网页函数
def getHtml(url,user_agent="wswp",num_retries=2): #下载网页,如果下载失败重新下载两次
print '开始下载网页:',url
# headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0'}
headers = {"User-agent":user_agent,"Cookie":"_T_WM=XXXXXXXX; SUB=XXXXXXXX; gsid_CTandWM=XXXXXXXXX"}
request = urllib2.Request(url,headers=headers) #request请求包
try:
html = urllib2.urlopen(request).read() #GET请求
except urllib2.URLError as e:
print "下载失败:",e.reason
html = None
if num_retries > 0:
if hasattr(e,'code') and 500 <= e.code < 600:
return getHtml(url,num_retries-1)
return html
import urllib2 if __name__ == '__main__': URL = 'http://weibo.cn/XXXXXX/fans' #URL替代 html = getHtml(URL) print html
成功访问到某个用户的粉丝信息
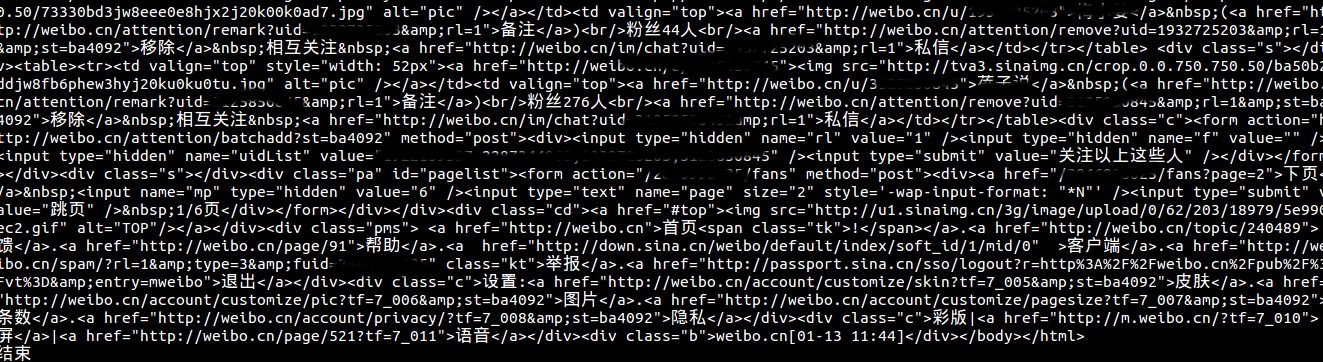
试一试访问一下最近一年很火的papi酱的微博,她的个人信息页面
import urllib2 if __name__ == '__main__': URL = 'http://weibo.cn/2714280233/info' #URL替代 html = getHtml(URL) print html
