我想最主要的作用有:
1、在进程下次启动时读取上次保存的对象的信息
2、在不同的AppDomain或进程之间传递数据
3、在分布式应用系统中传递数据
......
在C#中常见的序列化的方法主要也有三个:BinaryFormatter、SoapFormatter、XML序列化
本文就通过一个小例子主要说说这三种方法的具体使用和异同点
这个例子就是使用三种不同的方式把一个Book对象进行序列化和反序列化,当然这个Book类首先是可以被序列化的。至于怎么使一个类可以序列化可以参见:



 [Serializable]
[Serializable]

 }
} }
}一、BinaryFormatter序列化方式
1、序列化,就是给Book类赋值,然后进行序列化到一个文件中
 Book book = new Book(); book.BookID = "1"; book.alBookReader.Add("gspring"); book.alBookReader.Add("永春"); book.strBookName = "C#强化"; book.strBookPwd = "*****"; book.SetBookPrice("50.00"); BinarySerialize serialize = new BinarySerialize(); serialize.Serialize(book); BinarySerialize serialize = new BinarySerialize(); Book book = serialize.DeSerialize(); book.Write();
Book book = new Book(); book.BookID = "1"; book.alBookReader.Add("gspring"); book.alBookReader.Add("永春"); book.strBookName = "C#强化"; book.strBookPwd = "*****"; book.SetBookPrice("50.00"); BinarySerialize serialize = new BinarySerialize(); serialize.Serialize(book); BinarySerialize serialize = new BinarySerialize(); Book book = serialize.DeSerialize(); book.Write();调用反序列化后的截图如下:
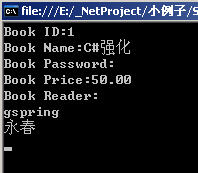
也就是说除了标记为NonSerialized的其他所有成员都能序列化
二、SoapFormatter序列化方式
调用序列化和反序列化的方法和上面比较类似,我就不列出来了,主要就看看SoapSerialize类
序列化之后的文件是Soap格式的文件(简单对象访问协议(Simple Object Access Protocol,SOAP),是一种轻量的、简单的、基于XML的协议,它被设计成在WEB上交换结构化的和固化的信息。 SOAP 可以和现存的许多因特网协议和格式结合使用,包括超文本传输协议(HTTP),简单邮件传输协议(SMTP),多用途网际邮件扩充协议(MIME)。它还支持从消息系统到远程过程调用(RPC)等大量的应用程序。SOAP使用基于XML的数据结构和超文本传输协议(HTTP)的组合定义了一个标准的方法来使用Internet上各种不同操作环境中的分布式对象。)
调用反序列化之后的结果和方法一相同
三、XML序列化方式
调用序列化和反序列化的方法和上面比较类似,我就不列出来了,主要就看看XmlSerialize类
xml序列化之后的文件就是一般的一个xml文件:

也就是说采用xml序列化的方式只能保存public的字段和可读写的属性,对于private等类型的字段不能进行序列化
关于循环引用:
比如在上面的例子Book类中加入如下一个属性:
public Book relationBook;
在调用序列化时使用如下方法:
Book book = new Book(); book.BookID = "1"; book.alBookReader.Add("gspring"); book.alBookReader.Add("永春"); book.strBookName = "C#强化"; book.strBookPwd = "*****"; book.SetBookPrice("50.00"); Book book2 = new Book(); book2.BookID = "2"; book2.alBookReader.Add("gspring"); book2.alBookReader.Add("永春"); book2.strBookName = ".NET强化"; book2.strBookPwd = "*****"; book2.SetBookPrice("40.00"); book.relationBook = book2; book2.relationBook = book; BinarySerialize serialize = new BinarySerialize(); serialize.Serialize(book);