一.Spring支持四种事务隔离级别:
1.ISOLATION_READ_UNCOMMITTED(读未提交):这是事务最低的隔离级别,它充许令外一个事务可以看到这个事务未提交的数据。
2.ISOLATION_READ_COMMITTED(读已提交): 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据
3.ISOLATION_REPEATABLE_READ(可重复读): 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。
4.ISOLATION_SERIALIZABLE(可串行化) 这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。
spring设置中还有一个默认级别:
ISOLATION_DEFAULT:使用数据库默认的事务隔离级别。
二、一些名词
多个事务并发会产生一些问题:
脏读:可以读取到其他事务修改但未提交的脏数据。
不可重复读:在一个事务中重复读取相同数据。在其中两次读取数据之间有另一个事务修改并提交了该数据。使得事务两次读到的数据是不一样的。
幻读: 第一个事务对一个表中的数据进行了修改,这种修改涉及 到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有 修改的数据行,就好象发生了幻觉一样。
丢失更新: 多个用户同时对一个数据资源进行更新,必定会产生被覆盖的数据,造成数据读写异常。
例子:假定有数据表
==student==
id | name
1 | 张三
a.脏读
事务A:select name from student where id=1;
事务B:update student set name='李四' where id=1;不提交
结果:可能是“李四”
读已提交:避免读取未提交数据。
b.不可重复读
事务A:select name from student where id=1;
select name from student where id=1;
事务B:update student set name='李四' where id=1;提交
结果:第一次读到“张三”,第二次可能读到“李四”
可重复读:避免事务B修改id为1的数据。但是事务B可以向表中新增数据李四
c.幻读
事务A:select name from student;
select name from student;
事务B:insert into student values(default,'李四');提交
结果:第一次读到“张三”,第二次可能读到"张三"和"李四"
串行化读:每次读都需要获得表级共享锁,读写相互都会阻塞。可避免幻读。
各种隔离级别与各种读的关系:

三、MySQL默认隔离级别
MySQL/InnoDB默认是可重复读的(REPEATABLE READ);
Oracle默认隔离级别是读已提交(READ_COMMITTED);
四、修改与查询MySQL事务隔离级别的方法:
1 #查全局事务隔离级别 2 SELECT @@global.tx_isolation; 3 #查当前会话事务隔离级别 4 SELECT @@session.tx_isolation; 5 #查当前事务隔离级别 6 SELECT @@tx_isolation; 7 #设置全局隔离级别 8 set global transaction isolation level read committed; 9 #设置当前会话隔离级别 10 set session transaction isolation level read committed;
其它隔离级别的设置就不说了。
测试,以root身份登陆,修改session.tx_isolation:
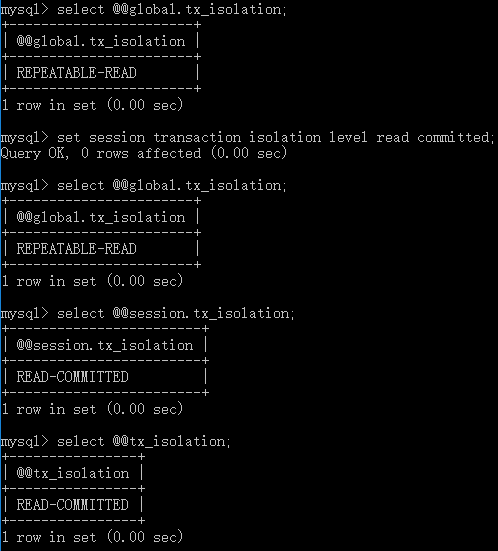
退出mysql,再次以root身份登陆,上次会话的设置失效:
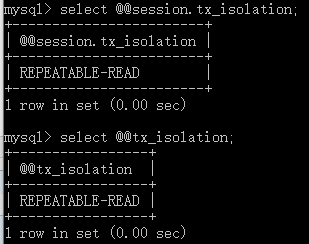
更换身份,使用foreigner身份登陆,修改全局权限:

再次以root身份登陆,查看权限:
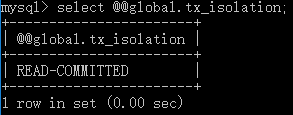
可见,全局事务隔离级别是MySQL全局的,与某个用户的或者某个会话的隔离级别没有关系。
五、锁机制
定义:当有事务操作时,数据库引擎会要求不同类型的锁定,如相关数据行、数据页或是整个数据表,当锁定运行时,会阻止其他事务对已经锁定的数据行、数据页或数据表进行操作。只有在当前事务对于自己锁定的资源不在需要时,才会释放其锁定的资源,供其他事务使用。
我个人对锁的理解是,某线程想要执行某个事务中的某条sql,必须得有某个锁。如果没有该锁,要等待自己获得该锁后才能执行相应操作。
共享锁(Share)
共享锁的代号是S,共享锁的锁粒度是行或者元组(多个行)。一个事务获取了共享锁之后,可以对锁定范围内的数据执行读操作。
排它锁(eXclusive)
排它锁的代号是X,是eXclusive的缩写,排它锁的粒度与共享锁相同,也是行或者元组。一个事务获取了排它锁之后,可以对锁定范围内的数据执行写操作。
意向锁
意向锁的含义是如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁;对任一结点加锁时,必须先对它的上层结点加意向锁。如:对表中的任一行加锁时,必须先对它所在的表加意向锁,然后再对该行加锁。这样一来,事务对表加锁时,就不再需要检查表中每行记录的锁标志位了,系统效率得以大大提高。
简单的说就是我要对哪个表进行事务操作了,就给哪个表加一个意向锁。
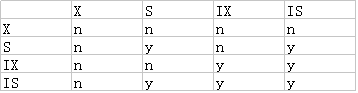
锁的互斥与兼容关系
锁和锁之间的关系,要么是相容的,要么是互斥的。
锁a和锁b相容是指:操作同样一组数据时,如果事务t1获取了锁a,另一个事务t2还可以获取锁b;
锁a和锁b互斥是指:操作同样一组数据时,如果事务t1获取了锁a,另一个事务t2在t1释放锁a之前无法获取锁b。
上面提到的共享锁、排它锁、意向共享锁、意向排它锁相互之前都是有兼容/互斥关系的,可以用一个兼容性矩阵表示(y表示相容,n表示互斥):
六、悲观锁和乐观锁
悲观锁(Pessimistic Lock), 每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁。
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适。
七、丢失更新及解决方法。
丢失更新:
假设没有X锁存在。执行A,B两个事务。下面这种情况事务A的提交会被事务B的提交覆盖

解决办法,加入X锁即可。