原文地址
守护进程
传统的后台服务一般作为守护进程(daemon)运行。linux 上创建 daemon 的步骤一般如下:
- 创建子进程,父进程退出;
- 调用系统调用
setsid()脱离控制终端; - 调用系统调用
umask()清除进程 umask 确保 daemon 创建文件和目录时拥有所需权限; - 修改当前工作目录为系统根目录;
- 关闭从父进程继承的所有文件描述符,并将标准输入/输出/错误重定向到
/dev/null。
前 3 个步骤是必须的。一些用来创建 daemon 的第三方库(比如这个)基本也是这么实现的,不过创建子进程的方式有些是用系统调用 fork ,有些是用标准库 exec 包,目的都一样。
优雅的结束进程
粗暴一点的方式是使用 kill 发送信号给后台进程,然后后台进程也没有安装任何自定义的信号处理器,直接按默认的行为终止进程。进程退出后,虽然其占用的内核资源都会被操作系统回收,但某些情况下,比如原子性的事务执行到一半时因为进程退出而中止,这种粗暴的退出会导致更复杂的状况。可控的退出是更优雅的方式。
响应信号
SIGKILL 和 SIGSTOP 信号被定义成无法被忽略或者捕获,这两个信号会导致后台进程直接粗暴的退出。其他信号会被 golang 语言运行时捕获。golang 语言运行时对这些信号的默认处理行为是:
- SIGBUS / SIGFPE / SIGSEGV 转换成运行时 panic
- SIGHUP / SIGINT / SIGTERM 进程退出
- SIGQUIT / SIGILL / SIGTRAP / SIGABRT / SIGSTKFLT / SIGEMT / SIGSYS 进程退出并打印调用堆栈
- SIGTSTP / SIGTTIN / SIGTTOU 终端作业控制相关,仍然保持默认的处理方式
- SIGPROF golang 运行时用来实现 runtime.CPUProfile
- 其他信号无任何动作
标准库中的 signal.Notify() 可以让 golang 语言运行时把相应的信号转发到 channel 里来代替默认的处理行为。下面的例子中,进程在监听到结束进程的的信号 SIGINT 或 SIGTERM 后,开始执行回收资源的操作,等待所有资源回收完成(事务执行完毕)后进程再退出。
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
c := make(chan os.Signal)
signal.Notify(c, os.Interrupt, syscall.SIGTERM)
for s := range c {
// wait for all resources are released
// ...
fmt.Printf("catch signal %v, now exit...
", s)
break
}
return
}
等待所有协程退出
当主协程退出时,并不会等待其他其他协程(后面称为工作协程)执行完毕。工作协程可能正在执行某个事务,主协程退出后,这个事务也就中断了。因此在主协程收到退出信号时,应该给工作协程发送退出信号,然后工作协程都退出后主协程再退出。工作协程在检测到退出信号后,开始释放占有的资源然后退出,这个操作不应该间隔太久,否则在主协程收到退出信号后因为要等待工作协程的退出,导致进程迟迟不会结束。主协程给工作协程发送退出信号可以使用前文中介绍的用 channel 当成信号量的方式。后文中将介绍更通用的使用标准库中的 context.Context 来管理工作协程生命期的方式。
goroutine 生命期管理
考虑这样一种场景:某个函数执行耗时比较大,可能是由于要通过网络调用后端服务而网络延迟可能很大,也可能是比较复杂的 CPU 计算执行时间比较久;调用者调用这个函数时会设置一个固定的超时时间,而不会无限制等待函数执行完成,超时时间到了后还没有等到结果的话就会认为调用失败然后进行相应的错误处理。通常调用者会开启一个协程来执行这个耗时的调用,然后通过 channel 来超时等待执行结果。如下例所示:
package main
import (
"fmt"
"time"
)
func longtimeCostFunc(c chan<- int) {
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
fmt.Println("calculating...")
}
c <- 1
fmt.Println("calculate finished")
}
func main() {
result := make(chan int, 1)
go longtimeCostFunc(result)
// 结果等待时间最多3秒
select {
case r := <-result:
fmt.Println("longtimeCostFunc return:", r)
case <-time.After(3 * time.Second):
// handle timeout error
fmt.Println("too long to wait for the result")
}
// blocking main goroutine exit
time.Sleep(time.Minute)
return
}
在这个例子中,当超时时间(3 second)到了后, 调用者不再等待 longtimeCostFunc() 的执行结果,开始进行相应的超时错误处理。此时执行 longtimeCostFunc() 的协程(工作协程)仍然在执行。在极端情况下,可能会导致无数个协程在默默进行毫无意义的操作白白耗费系统资源。因此需要一种机制让调用者不再关注工作协程的执行结果后通知工作协程退出。下面的示例中展示了使用标准库的 context 包来通知工作协程退出的方式:
package main
import (
"context"
"fmt"
"time"
)
func longtimeCostFunc(ctx context.Context, c chan<- int) {
for i := 0; i < 10; i++ {
select {
case <-ctx.Done():
fmt.Println("calculate interrupted")
return
case <-time.After(time.Second):
fmt.Println("calculating...")
}
}
c <- 1
fmt.Println("calculate finished")
}
func main() {
result := make(chan int, 1)
ctx, cancel := context.WithCancel(context.Background())
go longtimeCostFunc(ctx, result)
select {
case r := <-result:
fmt.Println("longtimeCostFunc return:", r)
case <-time.After(3 * time.Second):
// notify worker goroutine to exit
cancel()
// handle timeout error
fmt.Println("too long to wait for the result")
}
// blocking main goroutine exit
time.Sleep(time.Minute)
return
}
调用者通过 context.WithCancel() 获取一个可以取消的 context 及与之关联的取消函数 cancel,然后将获取的 context 传递给工作协程(一般作为第一个参数),工作协程通过 context.Done() 监听此 context 是否已经取消,当监听到取消事件后,工作协程就可以不再继续正常的业务流程可以退出了。当调用者调用取消函数 cancel 时,所有通过 context.Done() 监听此 context 是否取消的工作协程都会收到取消的信号。使用这种方式来管理子协程的生命期的时候,要注意子协程在执行正常的业务流程中要能及时响应 context 已取消的信号。
context 机制除了可以用来管理协程生命期外,还可以用来在有创建关系的一组协程中共享变量。通过这个特性可以实现类似其他语言的但 golang 没有的线程本地存储特性,
数据库操作与 ORM
标准库中的数据库操作接口
golang 标准库的数据接口使用了模板方法模式的设计模式。database/sql 包将 SQL 数据库的操作抽象成几个通用的接口对外提供。调用者使用 SQL 数据库时,不管底层用的哪种具体的 SQL 产品(MySQL, PostgreSQL, SQLite等等),都只需要调用通用的 database/sql 包中的接口。database/sql 中各通用接口的实现又只用到了标准库中的 database/sql/driver 包定义的各种类型。从标准库文档中可以看到 database/sql/driver 中的各种类型都是纯的 interface ,并没有实现。因此使用某种具体的 SQL 数据库产品时,需要提供一个第三方的包,这个包必须实现 database/sql/driver 中的各个 interface 并注册全局的接口实例。这个第三方包就是 SQL 数据库的驱动。当调用都使用 database/sql 操作数据库时,会找到注册的具体数据库驱动的实例,最终调用到第三方包中实现的数据库操作。
MySQL 是互联网公司广泛使用的 SQL 数据库产品,以流行的 MySQL 第三方 golang 驱动 github.com/go-sql-driver/mysql 使用为例,使用时需要 import 标准库的 database/sql 包和第三方驱动包:
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
import 的包前面加上下划线表示源码中没用使用此包,但编译时不会报错,并且通过这种方式 import 的包的初始化函数 init() 在 main 函数前会被运行时先调用。在驱动的源码 driver.go 中定义的初始化函数将实现了 database/sql/driver 接口的 MySQL 驱动实例注册到了全局的实例表里:
func init() {
sql.Register("mysql", &MySQLDriver{})
}
通过这种方式,调用者只需要使用 database/sql 包,就能操作各种类型的 SQL 数据库了。
ORM
在代码中直接通过 SQL 语句来操作关系型数据库有时候会很繁琐,因此出现了各种 sqlbuilder 和 ORM 。ORM 在具体的编程语言和 SQL 数据库之间增加了一层抽象,将具体语言的类型系统(比如 golang 中的 struct, python 中的 class) 映射成关系型数据库中的表。在需要操作 SQL 数据库时,ORM 的使用者仍然只需要在关注各自语言的类型系统上操作,ORM 组件层会将这些操作转化成相应的 SQL 语句来操作底层的 SQL 数据库。换句话说, SQL 数据库对使用者来说明透明的。
抽象和分层是解决复杂问题的基本原则。
比如一个 Student 类,在 golang 中被定义成一个 struct :
type Student struct {
id int
name string
gender int
age int
class int
}
当需要在 SQL 数据库保存一个 Student 类的实例时,SQL 数据库中需要一张相应的 t_student 表,此表相应也有 5 个 column (id, name, gender, age, class)。使用 ORM 时,golang 中 Student 类的实例被映射成数据库 t_student 表的一个记录。当需要更新某个 Student 实例的属性时,golang 中直接修改 struct 的某个字段:
studentA.age = 15
ORM 组件会将这个操作映射成相应的 update SQL 语句,最终实现数据库中相应实体的更新。
需要注意的时编程语言的类型和数据库表能被 ORM 映射是因为两者都具体一些类似的特性。ORM 把这些共同的特性抽象成通用的操作,显然这两者也不是完全一一对应的,因此某些特殊的数据库的操作并不能用 ORM 来实现,仍然需要用 SQL 语句来操作。
另外,ORM 层做的转换并不见得很智能,在 DBA 看来这种转换来的 SQL 可能相当低效。因此在某些性能敏感的场合下,最好对 ORM 转换的 SQL 做下审核。
ORM 一般需要用到语言的反射(reflect)特性。在没有反射特性的语言上(比如 C++),要实现一个 ORM 库是相当复杂的。因此这类语言都没什么好用的 ORM 库。幸运的是,golang 不是这类语言。
golang 的 ORM 库,推荐使用 gorm ,具体使用教程参考官方文档,这里就不赘述了。
HTTP 服务
标准库 net/http 包
使用 golang 标准库的 net/http 包实现一个 HTTP server 很简单,只需要几行代码:
package main
import (
"net/http"
)
func foo(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("foo
"))
}
func bar(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("bar
"))
}
func main() {
http.HandleFunc("/foo", foo)
http.HandleFunc("/bar", bar)
http.ListenAndServe(":8080", nil)
}
下面结合 net/http 包源码简单的分析下这个 server 在内部是如何运行的。首先忽略掉前面接口注册的代码,查看服务总入口处 http.ListenAndServe() 的实现:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}
发现就是将参数 addr 和 handler 构造出一个 Server 对象,然后直接调用其 ListenAndServe() 方法。继续查看 Server 的定义:
type Server struct {
Addr string // TCP address to listen on, ":http" if empty
Handler Handler // handler to invoke, http.DefaultServeMux if nil
// ...
}
其他字段都是一些数据字段,构造 Server 对象的时候也没有设置,这里省略不表。除此之外,只有 Handler 字段是个接口,定义如下:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
因此在这里可以猜想到 Server 的 ListenAndServe() 方法应该是从 TCP 连接上读取数据后解析出 HTTP 请求报文,将这个 HTTP 包文抽象成 Request 对象并将其指针作为参数传递给调用者设置的 Handler 的 ServeHTTP() 方法,然后接收此方法写入第一个 ResponseWriter 类型参数的数据,将其组包成 HTTP 响应报文,最后通过 TCP 连接发送给客户端。为了验证这个猜想,直接实现一个自定义的 Handler 来调用:
package main
import (
"net/http"
)
func foo(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("foo
"))
}
func bar(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("bar
"))
}
type MyHandler struct{}
func (mh *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
switch r.URL.Path {
case "/foo":
foo(w, r)
case "/bar":
bar(w, r)
default:
w.WriteHeader(404)
}
}
func main() {
server := &http.Server{Addr: ":8080", Handler: &MyHandler{}}
server.ListenAndServe()
}
效果和前面的例子一模一样。继续阅读 Server 的 ListenAndServe() 方法也会发现确实和上面猜想的一样。这个方法里实现了 HTTP 报文的解析与组装,这部分还是比较复杂的,这里就不深究了。上面这个流程简单用图形描述如下:
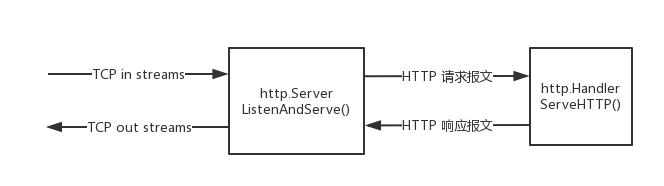
在这个自定义的 Handler 实现里,用 switch 把不同的路径的请求分发给不同的处理函数,实现这个路由功能的实体叫做多路选择器(mux)。在 net/http 包中提供了 ServerMux 类型专门用来做这种路由功能。ServerMux 也实现了 ServeHTTP() 方法,因此也可以当成 Handler 用来构造 Server 对象。ServerMux 内部维护了 HTTP 请求路径与对应 Handler 的路由表,通过 HandleFunc() 可以将路径与对应 Handler 注册到这个路由表里。上面第一个例子中 http.HandleFunc("/foo", foo) 实际上就是把路径 /foo 和对应的处理函数 foo 注册到默认的多路选择器 DefaultServeMux 的路由表里,构造 Server 时如果没有指定 Handler ,就会使用这个默认的多路选择器。运行时 Server 的 ListenAndServe 会调用 ServerMux 的 ServeHTTP() 方法,这个方法中根据请求路径在注册的路由表找到对应的 Handler ,最终把请求交给这个 Handler 来处理。这种用多路选择器来实现路由功能的流程简单用图形描述如下:
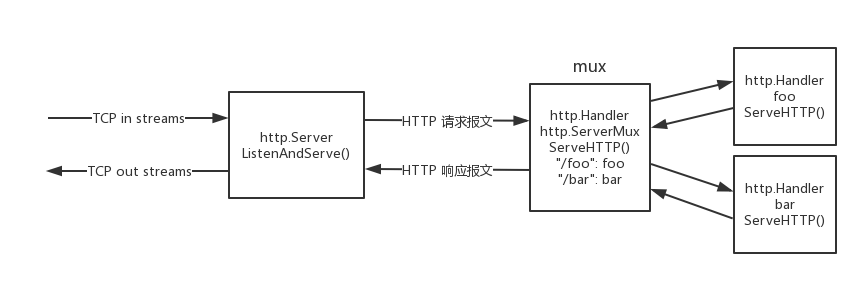
httprouter
golang 标准库的提供多路选择器实现的路由功能比较简单,只能根据请求路径进行字符串全匹配。现在流行的 RESTful 风格的 HTTP 接口一般会在路径里带上参数: /user/:id ,而且还会使用不同的 HTTP Method 表示对资源的不同操作。这需要针对 HTTP Method 和请求路径的组合做路由选择,并且还需要从路径里提取出参数。这时候标准库就不够用了。httprouter 是一个广泛使用的高性能开源多路选择器,在有复杂路由的场景下推荐使用。具体的使用教程参考官方文档,这里不赘述。
虽然使用这个库来实现 HTTP 服务时,写的代码好像和使用标准库时有点不一样,但是从上面的分析中应该知道,httprouter 只是一个实现了路由功能的多路选择器,它仍然是一个 Handler 并用来构造 Server 。理解了这点,应该就能更快的上手这个库了。
middleware
中间件(middleware)在不同的语境下有不同的含义。这里说的中间件可以理解为一个修饰器(参考设计模式的修饰模式),中间件把处理 HTTP 业务逻辑的原始 Handler 修饰(增加一些额外的功能)成另外一个 Handler 。net/http 包中的 StripPrefix 和 TimeoutHandler 可以看成是中间件应用。使用中间件可以在不修改原有业务逻辑的基础上方便扩展新功能。
仍以上面的示例代码为例。在上面的示例代码中,实现了两个 Handler 分别处理路径为 /foo 和 /bar 的请求。假设这时候需要增加一个功能:将每个请求处理耗时记录到日志。笨一点的做法是在每个 Handler 里都加上记录耗时日志的代码,在业务比较简单只有几个 Handler 是这样做还能接受,但是如果有几十上百个 Hanlder 的话,相同的代码片断要拷贝几十上百份,这样的代码就很丑陋了。这时候可以使用一个中间件把原有的 Handler 增加耗时日志的功能:
package main
import (
"log"
"net/http"
"time"
)
func foo(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("foo
"))
}
func bar(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("bar
"))
}
func timeLogMiddleware(f http.HandlerFunc) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
start := time.Now()
defer log.Printf("handle request: %s cost %.4f seconds
", r.URL.String(), time.Now().Sub(start).Seconds())
f(w, r)
})
}
func main() {
http.Handle("/foo", timeLogMiddleware(foo))
http.Handle("/bar", timeLogMiddleware(bar))
http.ListenAndServe(":8080", nil)
}
但是这段代码有可能会让人迷惑:这里又是 Handler 又是 HandlerFunc 到底是什么关系?而普通函数 foo 怎么又变成了 Handler 注册到了路由表里?这里简单梳理一下。先看 HandlerFunc 相关的定义:
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}
在 golang 里函数作为一等公民是可以当成值传递的。这里中间件 timeLogMiddleware 是一个函数,并且需要一个类型为 HandlerFunc 的参数,而普通函数 foo 和类型 HandlerFunc 具有相同的函数签名,因此 foo 可以直接传给 timeLogMiddleware() 调用。在 timeLogMiddleware() 的定义里,又实现了一个匿名函数,这个匿名函数增加了记录耗时日志的功能并最终会调用传进来的普通函数 foo。这个匿名函数因为和类型 HandlerFunc 具有相同的函数签名因此可以转型成 HandlerFunc 类型的值。最后因为 HandlerFunc 类型实现了 ServeHTTP 接口,因此 HandlerFunc 类型的值可以用 Handler 类型来接收。最终整个的过程就是通过函数调用 timeLogMiddleware(foo) 得到了一个 Handler 值。
当然中间件也可以实现成自定义的 struct 类型,只要实现 ServeHTTP 接口即可。上面的示例如果这样实现的话可能更容易理解一点:
package main
import (
"log"
"net/http"
"time"
)
func foo(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("foo
"))
}
func bar(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("bar
"))
}
type timeLogMiddleware struct {
f http.HandlerFunc
}
func (t *timeLogMiddleware) ServeHTTP(w http.ResponseWriter, r *http.Request) {
start := time.Now()
defer log.Printf("handle request: %s cost %.4f seconds
", r.URL.String(), time.Now().Sub(start).Seconds())
t.f(w, r)
}
func main() {
http.Handle("/foo", &timeLogMiddleware{foo})
http.Handle("/bar", &timeLogMiddleware{bar})
http.ListenAndServe(":8080", nil)
}
上面的例子展示了如何使用中间件在没有修改原有业务逻辑代码的情况下扩展新功能。中间件也可以继续修饰中间件,或者不同的中间件组合使用,真正做到代码的可插拨。这里的关键是要理解 Handler 是如何作为 HTTP 协议框架与业务逻辑处理之间的桥梁的。
gin
通过上面的介绍,读者应该基本上能实现一个微型的 HTTP 框架了。HTTP 协议的解析与组装可以直接使用标准库 http.Server 的实现,加上比标准库强大点的路由功能,定制一些常用的中间件,再加上一些工具函数,一个轻量高效的 HTTP 框架就诞生了。实际上流行的开源框架 gin 做的工作也就是这些。使用这类微型的 HTTP 框架,再加上数据库相关的及一些其他的外围开源库,就可以开发企业级应用了。
小赢其他自研组件介绍
- 日志库 支持文件滚动和分级日志;
- ZRPC 库 和公司的 zmq rpc 服务交互时需要用到;
- 网络工具库 ;
- dc 库 模调上报接口,模调系统的说明参考这里;
- apollo 客户端库 ,apollo 是公司使用的配置中心,基于携程开源的 apollo 开发,推荐尽量使用 apollo 配置,配置文件的方式不方便动态更新,使用说明参考这里。
总结
本文总结了在开发后台服务时的一些惯常做法和并简单介绍了相关的技术及开源库。
后在服务一般作为守护进程存在。守护进程应该要捕获常用的退出信号,并确保占用的资源都释放后才能退出主协程,不响应任何信号让 golang 运行时采用默认的信号处理动作不是好的做法。回收资源的过程也应该避免耗时太久,可以使用标准库的 context 包来管理工作协程的生命期,工作协程收到退出信号后应该及时退出避免阻塞整个进程的退出。
通常后台服务离不开数据库,这里主要介绍了关系型数据库和 golang 标准库的 SQL 接口实现,这个实现使用了模板方法模式:将各种数据数据库产品的底层协议交互抽象到数据库驱动层,将 SQL 编程接口抽象成 database/sql 包的公开接口,这些接口的实现是调用固定组合的驱动层接口。特定的数据库驱动只需要实现驱动层的各个接口,这样调用者就能通过标准库统一的接口操作各种各样的数据库产品了。ORM 将语言的类型映射成数据库表,使用者不再需要再关注操作数据库的 SQL ,直接操作语言的本地类型对象,ORM 底层会转换成相应的 SQL 语句。
HTTP 协议作为互联网的标配之一,HTTP 库也纳入到了 golang 的标准库里。只使用标准库写一个 HTTP 服务还是比较简单的。标准库将 HTTP 协议框架与业务逻辑解耦,两者之间只通过 Handler 接口来连接,这个接口只有一个方法。标准库的 ServerMux 用来实现简单的路由功能,需要更复杂的路由功能可以使用第三方库 httprouter 或者自己实现一个定制的路由器也不是什么难事。使用中间件可以在不修改原有代码的基础上扩展新功能。流行的开源框架 gin 也是用中间件大大减轻了 HTTP 服务开发的工作量。