转载:https://zhuanlan.zhihu.com/p/100051331
1.Spark基于StandaLone的任务提交模式
StandaLone提交任务有两种模式,一种是基于客户端Client提交任务,另一种是集群cluster提交任务。
首先来看基于客户端提交任务:
提交命令为:
./spark-submit --master spark://node1:7077 --deploy-mode client --class jar包它执行的流程大致如下:
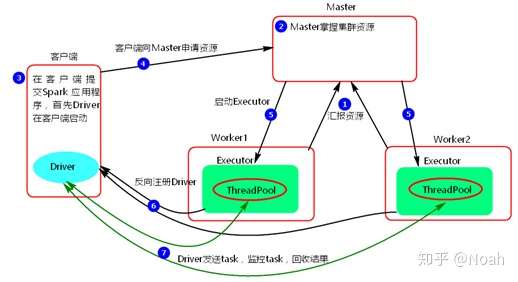
1.当有了客户端后,就会有了相应的master与worker节点,并且当集群启动的时候,worker会向master汇报资源(核,内存等),然后master就会掌握了worker的资源。
2.这时,当客户端提交Spark application时,Driver会首先在客户端启动,Driver启动之后,客户端会向Master申请资源。
3.Master会找到满足客户端请求资源的Worker节点,并且会去启动一个executor,executor就相当于Hadoop里面的Container,就是申请一批container来执行task任务,而Executor是一个进程,它会准备一个线程池,就是pool task,也是是去执行任务的。当executor启动成功后,会向driver反向注册,也就是告诉driver,我已经准备好了,你可以向我发送task任务了。
4.Driver直接向Executor发送task,并且监控task,将executor执行的结果给回收回来。
但是这种模式是有问题得的:
首先driver是在客户端启动的,每提交一个spark任务后,每个apllication都会启动一个driver,每一个任务都会有一个独立的Driver,Driver与集群中的worker会有很多的通信,如果在客户端提交大量的application,有可能会造成客户端网卡流量激增的问题,可以在客户端看到task的执行与结果,这种模式可以用于平时的测试状态。
standalone还有基于集群的提交模式
该模式的命令为:
./spark-submit --master spark://node1:7077 --deploy-mode cluster --class jar包该模式的执行流程为:
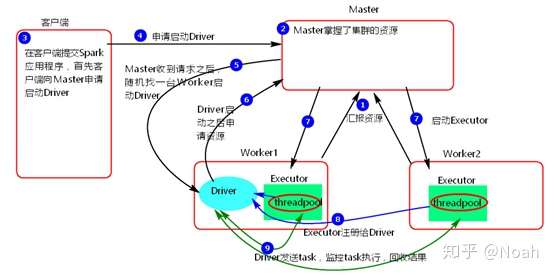
1.当集群启动的时候,worker会向master汇报资源,然后master就会掌握worker的集群信息。
2.客户端会提交Spark Application,这时客户端会向Master申请启动Driver。
3.Master会随机找到一个满足资源的Worker节点启动diver,这时当driver启动后,driver会向master申请资源用于application启动。
4.Master收到请求后会找到满足资源的节点去启动executor,每个executor里面会有线程池threadpool。
5.executor启动会向driver注册,driver向executor发送task,并且回收处理的解果。
Driver进程是在集群某一台Worker上启动的,在客户端是无法查看task的执行情况的。假设要提交100个application到集群运行,每次Driver会随机在集群中某一台Worker上启动,那么这100次网卡流量暴增的问题就散布在集群上。这种模式适合于生产环境,运行的状态要在web UI上面查看详细的信息。
2.Spark基于Yarn提交任务模式
它也有两种方式,一种是client客户端,另一种是cluster集群方式
提交任务的命令是:
./spark-submit --master yarn --class jar包执行任务的流程大致是这样的:
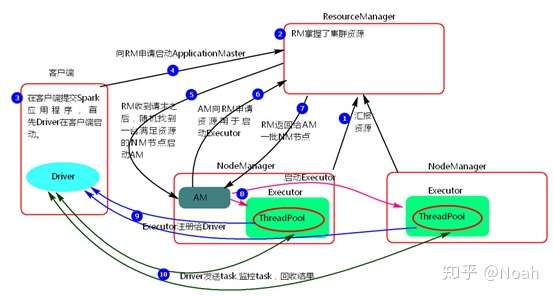
因为Yarn有自己资源管理的模式,所以在这种模式下,由resourceManager来掌握集群的资源,
1.当启动后,nodeManager会向resourcemanager汇报资源,而RM会掌握NM的资源。
2.当在客户端提交SparkApplication时,Driver会在客户端启动,客户端会向RM申请启动ApplicationMaster(在hadoop2.0后,负责任务调度)。
3.RM 收到请求会向随机找一个满足资源的NM启动Application Master,AM启动后,会向RM申请资源用于启动executor,RM会返回一批NM节点给AM,AM收到返回结果后,会真正的向NM中去启动executor,每个executor中会有线程池。
4.executor启动后会向Driver注册,Driver会向executor发送task,并且监控task执行,收回task执行的结果。
它的问题在于:因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加,可以在客户端看到task的执行和结果.Yarn-client模式同样是适用于测试。
ApplicationMaster的作用:
1. 为当前的Application申请资源
2. 给NameNode发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
2.第二种模式时基于Yarn cluster模式执行的。
它的命令如下:
./spark-submit --master yarn --deploy-mode cluster --class jar包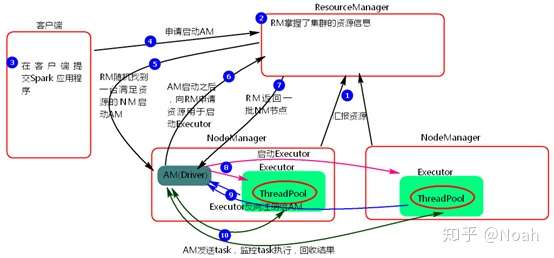
它的执行流程是这样的:
1.启动集群后,NM会向RM汇报资源,而RM就掌握了集群的资源。
2.当客户端提交Spark Appliction。会向RM申请启动ApplictaionMaster,而RM会随机找到一个满足资源的NM去启动AM。
3.当AM启动之后它负责任务调度,所以这里就不启动Driver,而AM就相当于Driver一样的功能存在。
http://4.AM启动后会向RM申请启动Executor,每个Executor会由线程池,RM会返回一批满足资源的NM节点。
http://5.AM接收到返回结果会找到相应的NM,启动Executor,executor启动后会向AM注册,而AM会将task发送到executor去执行,并且监控task,回收task'处理的结果。
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
ApplicationMaster的作用:
1. 为当前的Application申请资源
2. 给NameNode发送消息启动Excutor。
3. 任务调度。
停止集群任务命令:yarn application -kill applicationID