1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决?
2.尽量不在NameNode上执行start-balancer.sh的原因是什么?
集群平衡介绍
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点。当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之间无法达到更好的网络带宽使用率,机器磁盘无法利用等等。可见,保证HDFS中的数据平衡是非常重要的。
在Hadoop中,包含一个Balancer程序,通过运行这个程序,可以使得HDFS集群达到一个平衡的状态,使用这个程序的命令如下:
- sh $HADOOP_HOME/bin/start-balancer.sh –t 10%
这个命令中-t参数后面跟的是HDFS达到平衡状态的磁盘使用率偏差值。如果机器与机器之间磁盘使用率偏差小于10%,那么我们就认为HDFS集群已经达到了平衡的状态。
Hadoop的开发人员在开发Balancer程序的时候,遵循了以下几点原则:
1. 在执行数据重分布的过程中,必须保证数据不能出现丢失,不能改变数据的备份数,不能改变每一个rack中所具备的block数量。
2. 系统管理员可以通过一条命令启动数据重分布程序或者停止数据重分布程序。
3. Block在移动的过程中,不能暂用过多的资源,如网络带宽。
4. 数据重分布程序在执行的过程中,不能影响name node的正常工作。
集群执行balancer依旧不平衡的原因
基于这些基本点,目前Hadoop数据重分布程序实现的逻辑流程如下图所示:
<ignore_js_op>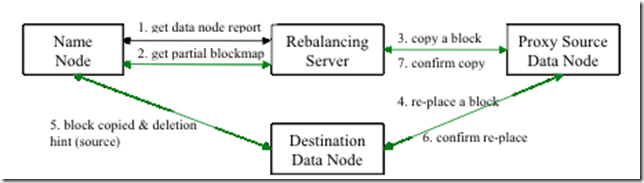
Rebalance程序作为一个独立的进程与name node进行分开执行。
1 Rebalance Server从Name Node中获取所有的Data Node情况:每一个Data Node磁盘使用情况。
2 Rebalance Server计算哪些机器需要将数据移动,哪些机器可以接受移动的数据。并且从Name Node中获取需要移动的数据分布情况。
3 Rebalance Server计算出来可以将哪一台机器的block移动到另一台机器中去。
4,5,6 需要移动block的机器将数据移动的目的机器上去,同时删除自己机器上的block数据。
7 Rebalance Server获取到本次数据移动的执行结果,并继续执行这个过程,一直没有数据可以移动或者HDFS集群以及达到了平衡的标准为止。
Hadoop现有的这种Balancer程序工作的方式在绝大多数情况中都是非常适合的。
现在我们设想这样一种情况:
1 数据是3份备份。
2 HDFS由2个rack组成。
3 2个rack中的机器磁盘配置不同,第一个rack中每一台机器的磁盘空间为1TB,第二个rack中每一台机器的磁盘空间为10TB。
4 现在大多数数据的2份备份都存储在第一个rack中。
在这样的一种情况下,HDFS级群中的数据肯定是不平衡的。现在我们运行Balancer程序,但是会发现运行结束以后,整个HDFS集群中的数据依旧不平衡:rack1中的磁盘剩余空间远远小于rack2。
这是因为Balance程序的开发原则1导致的。
简单的说,就是在执行Balancer程序的时候,不会将数据中一个rack移动到另一个rack中,所以就导致了Balancer程序永远无法平衡HDFS集群的情况。
针对于这种情况,可以采取2中方案:
1 继续使用现有的Balancer程序,但是修改rack中的机器分布。将磁盘空间小的机器分叉到不同的rack中去。
2 修改Balancer程序,允许改变每一个rack中所具备的block数量,将磁盘空间告急的rack中存放的block数量减少,或者将其移动到其他磁盘空间富余的rack中去。
----------------------------------------------------------------------------------------------------------
使用经验总结
由于历史原因,hadoop集群中的机器的磁盘空间的大小各不相同,而HDFS在进行写入操作时,并没有考虑到这种情况,所以随着数据量的逐渐增加,磁盘较小的datanode机器上的磁盘空间很快将被写满,从而触发了报警。
此时,不得不手工执行start-balancer.sh来进行balance操作,即使将dfs.balance.bandwidthPerSec 参数设置为10M/s,整个集群达到平衡也需要很长的时间,所以写了个crontab来每天凌晨来执行start-balancer.sh,由于此时集群不平衡的状态还没有那么严重,所以start-balancer.sh很快执行结束了。
另外需要注意的地方是,由于HDFS需要启动单独的Rebalance Server来执行Rebalance操作,所以尽量不要在NameNode上执行start-balancer.sh,而是找一台比较空闲的机器。
1) hadoop balance工具的用法:
To start:
bin/start-balancer.sh [-threshold <threshold>]
Example: bin/ start-balancer.sh
start the balancer with a default threshold of 10%
bin/ start-balancer.sh -threshold 5
start the balancer with a threshold of 5%
To stop:
bin/ stop-balancer.sh
2)影响hadoop balance工具的几个参数:
-threshold 默认设置:10,参数取值范围:0-100,参数含义:判断集群是否平衡的目标参数,每一个 datanode 存储使用率和集群总存储使用率的差值都应该小于这个阀值 ,理论上,该参数设置的越小,整个集群就越平衡,但是在线上环境中,hadoop集群在进行balance时,还在并发的进行数据的写入和删除,所以有可能无法到达设定的平衡参数值。
dfs.balance.bandwidthPerSec 默认设置:1048576(1 M/S),参数含义:设置balance工具在运行中所能占用的带宽,设置的过大可能会造成mapred运行缓慢