今日内容
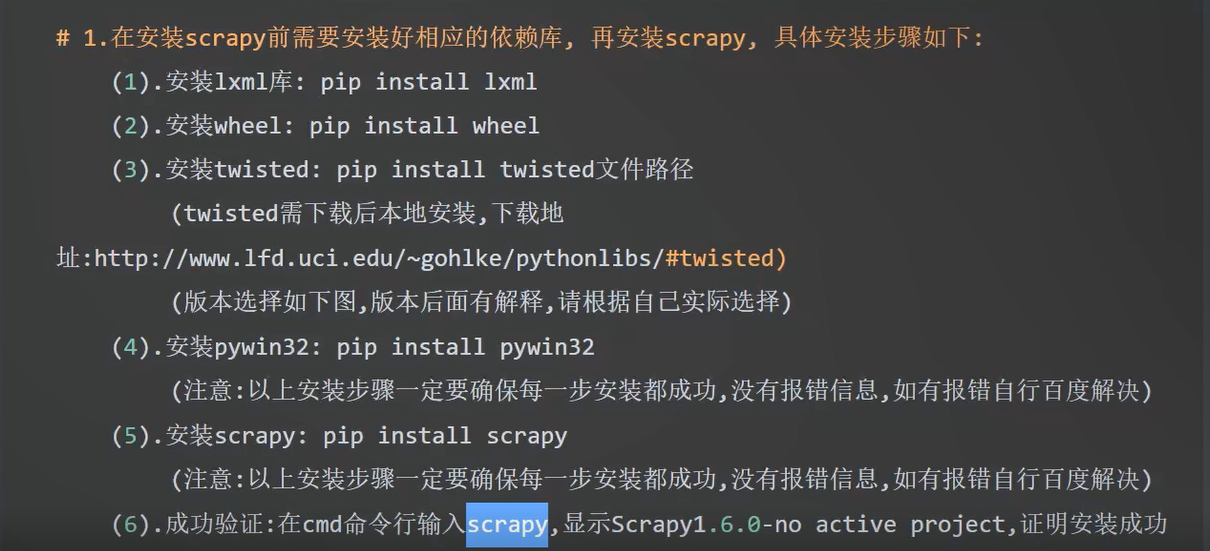
1.安装与配置
2.创建项目
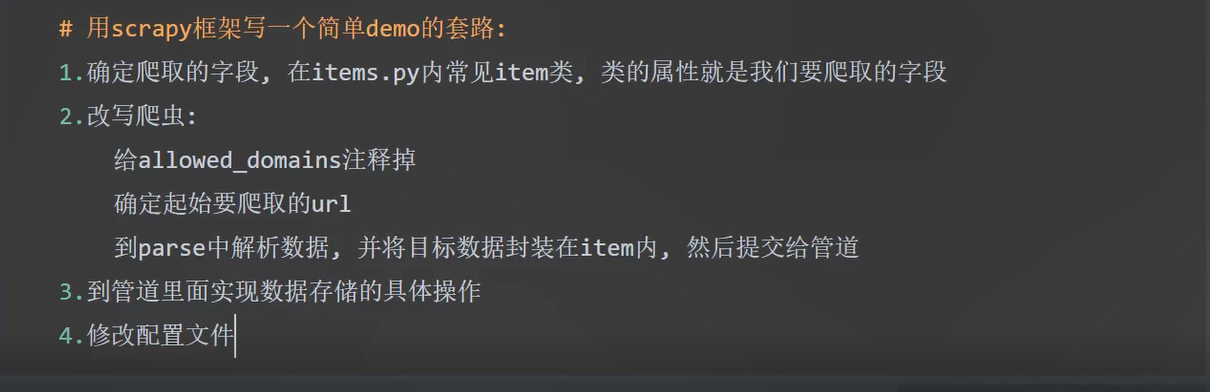
# scrapy
scrapy startproject 项目名 #创建项目
scrapy genspider 文件名 baidu.com #创建爬虫
#运行
scrapy crawl 文件名
scrapy crawl 文件名 --nolog #运行命令 ---nolog就是不在控制台打印日志
#注意事项:
--nolog:不打印日志,同样如果抛出异常,也不会打印异常
3.工程目录的介绍

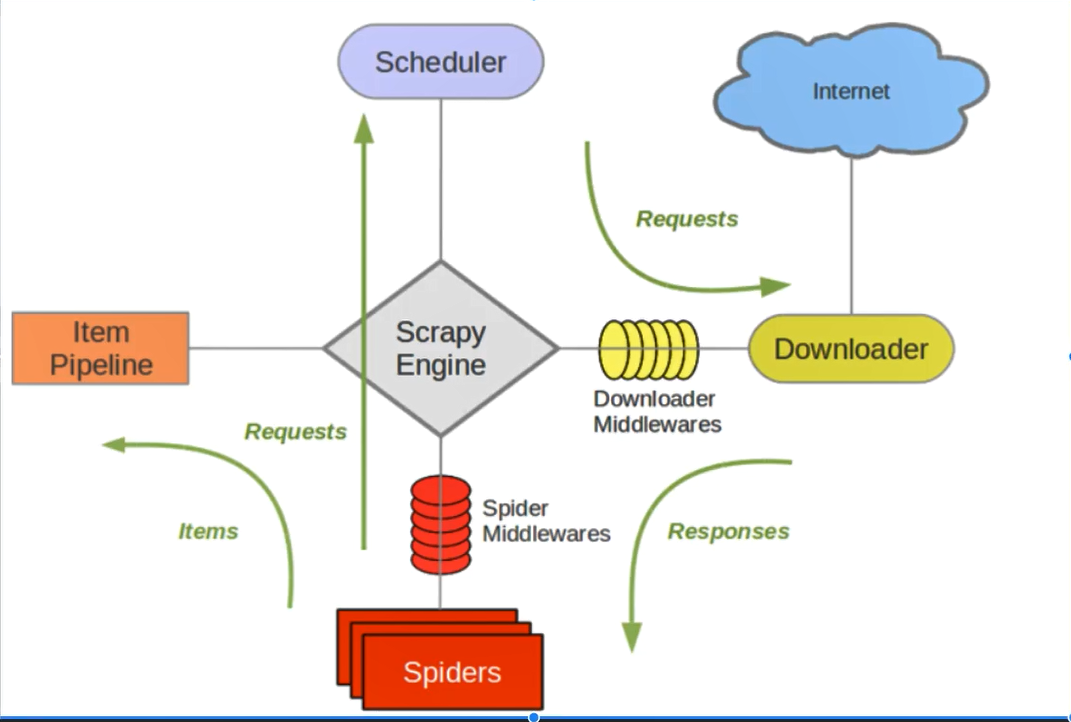
4.核心组件与数据流向
#五大核心组件
1.引擎组件:整个框架的调度者,负责各个组件之间的通信与数据的传递
2.爬虫组件:定义爬取行为和解析规则
3.调度器组件:负责调度所有请求
4.下载器:负责爬取页面
5.管道:负责数据持久化

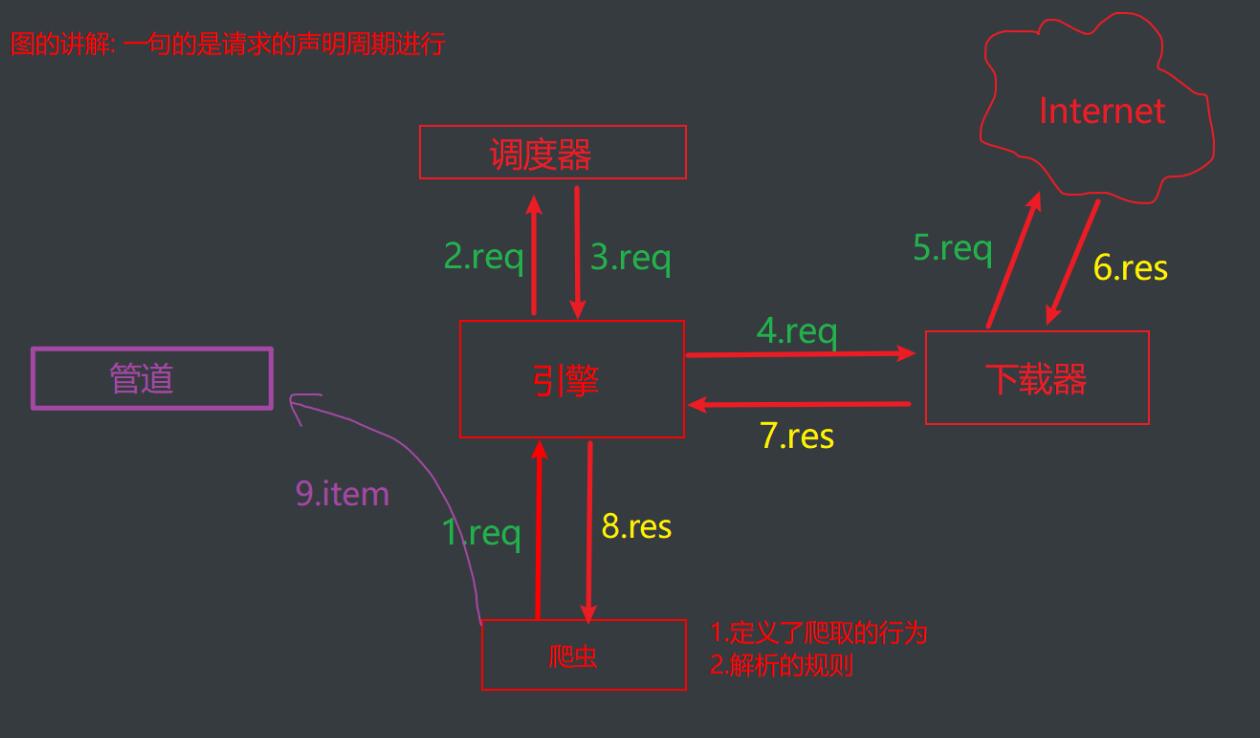
req是请求 res是获取到的数据
这个图比较标准