设想有这样一个场景:爬虫把数据一条一条写入到 Redis 中,你的另一个程序从 Redis 中一条条读取出来,进行一些处理后写入 MongoDB。
一开始,你的处理逻辑非常简单,如果爬虫爬取的数据中,包含“垃圾信息”这四个字,那么直接把信息丢弃。
运行了一段时间,新增了一个需求:如果数据的“source”字段为weibo并且包含“过时信息”,那么把数据丢弃。
又过了一段时间,老板又来了一个需求:如果数据的"source"字段为“bilibili”,并且正文包含“报警”,那么调用一个报警接口,通知老板。但数据继续走后续流程。
按照常规做法,每次增加新的需求,你都要改项目代码,然后重新启动程序。
现在,我们想实现一个插件系统,整个项目始终不停运行,这些新增的需求通过一个一个插件文件来完成,每完成一个需求,把这个文件放到某个特定的文件夹里面,系统自动就会开始调用。
所谓的“插件系统”,看起来非常高大,实际上非常简单,我们的主程序定期扫描特定文件夹,如果发现新增文件或者有文件发生了修改,就热加载这个文件中的代码。
在 Python 里面,我们可以使用importlib.reload函数来重新加载一个模块。我们来看一下它的用法。
首先,我们创建一个文件example_plugin.py,里面的内容如下:
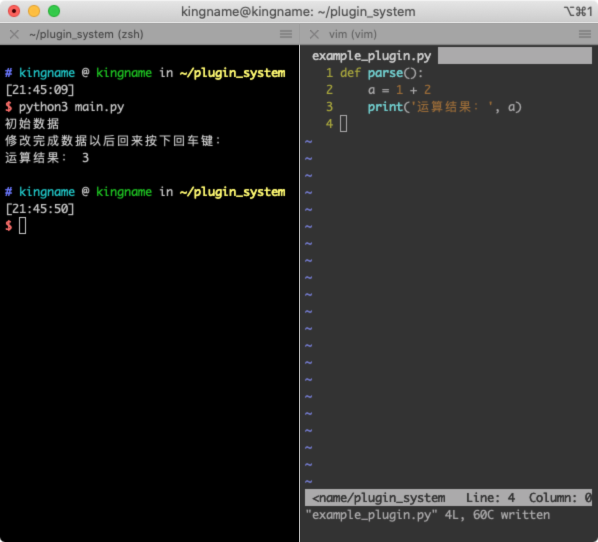
def parse(): print('初始数据')
然后,我们创建一个main.py文件,来调用它:
import importlib import example_plugin example_plugin.parse() input('修改完成数据以后回来按下回车键:') importlib.reload(example_plugin) example_plugin.parse()
程序运行到input这一行时,会停下来。然后我们去修改example_plugin.py中,parse函数中的代码,修改完成以后保存。回到终端里面按下回车。运行效果如下图所示:
如果 example_plugin.py 在一个package 里面,也没有问题,如下图所示结构:

只不过是在main.py中,把导入模块的代码改成了from package import module而已。
但需要注意的是,reload函数的作用对象是一个module,也就是xxx.py文件。所以如果你试图像下面这样写代码,必然会出问题:
import importlib from plugin.example_plugin import parse parse() importlib.reload(parse) #这里一定会出问题 parse()
还有一种非常容易让人混淆的情况,那就是如果example_plugin.py中的函数也叫做example_plugin,然后在__init__中提前导入:from example_plugin import example_plugin,那么此时当你在 main.py中执行from plugin import example_plugin时,导入的实际上是example_plugin函数,而不是 module。如下图所示:

最后,如果你使用 PyCharm 来测试,可能会发现你修改了文件,但是热加载却失败了。这是因为 PyCharm 在改了文件以后,不是实时写到硬盘上的,它有一个缓存时间。当你修改了一个文件以后,你可以使用另一个程序打开一下这个被修改的文件,这样缓存到 PyCharm 中的修改内容就会被真正写到文件里面去。
这就是实现热加载的核心功能了。基于importlib.reload,你可以写一段代码,监控某个特定的文件夹,一旦发现里面新增、修改、删除文件,你就把这些变动的代码热加载一次。然后正在运行中的 Python 程序就可以不停机使用新增的功能了。
转自:微信公众号:未闻code