我们知道,URL 由下面几个部分组成:

其中Query部分,中文叫做查询参数。它在 URL 中,是由等号连接的键值对。这些键值对有一些是有效的,例如:
https://open.163.com/newview/movie/courseintro?newurl=MDAPTVFE8
这个网址中的newurl=MDAPTVFE8是不能修改的,一旦你改了,那就不再是这个页面了。
但还有一些网址,他们的查询参数对网页的显示没有任何影响,例如下面两个网址:
https://www.163.com/dy/article/G7NINAJS0514HDK6.html?from=nav https://www.163.com/dy/article/G7NINAJS0514HDK6.html
当你访问这两个网址,你会发现它们打开的是同一个页面。因为这些参数是给网站用的。网站使用这些参数来统计用户是从哪个页面跳转到这个页面的。
在我们开发新闻通用爬虫的时候,这种可有可无的查询参数会对基于 URL 的去重导致严重干扰。同一篇新闻,可能因为从不同的页面跳转过来,就有不同的查询参数,那么就可能会被当做多篇不同的新闻。
我们在对新闻进行去重的时候,一般会有一个三级去重逻辑:基于 URL 去重,基于新闻正文文字去重,基于正文语义去重。他们对资源的消耗逐渐增加,因此,如果能通过 URL 确认是重复的新闻,就没有必要经过文本去重;能够经过文本确认是重复的新闻,就没有必要使用语义去重。这种无效的参数,会导致进入第二级的新闻数量增加,从而消耗更多的服务器资源。
为了防止这种无效的参数干扰基于 URL 去重的逻辑,因此我们需要提前移除无效的 URL 参数。
假设现在有一个网址:
https://www.kingname.info/article?docid=123&from=nav&output=json&ts=1849304323
我们通过人工标注,已经知道,对于https://www.kingname.info这个网站,docid和output参数是有效参数,必须保留;from和ts参数是无效参数,可以移除。那么,我们如何正确移除这些不需要的参数字段呢?
肯定有同学会说使用正则表达式来移除。那么你可以试一试,正则表达式应该怎么写。提示一下,有一些参数值里面也会有=符号、有一些必要字段的值,可能恰好包含无效字段的名字。
今天,我们不使用正则表达式,而使用 Python 自带的 urllib 模块中的几个函数来实现安全完美的移除无效字段的方法。
这个方法,需要使用到urlparse parse_qs urlencode和urlunparse。我们来看一段代码:
from urllib.parse import urlparse, parse_qs, urlencode, urlunparse url = 'https://www.kingname.info/article?docid=123&from=nav&output=json&ts=1849304323' useless_field = ['from', 'ts'] parser = urlparse(url) query = parser.query query_dict = parse_qs(query) for field in useless_field: if field in query_dict: query_dict.pop(field) new_query = urlencode(query_dict, doseq=True) new_parser = parser._replace(query=new_query) new_url = urlunparse(new_parser) print(new_url)
运行效果如下图所示:
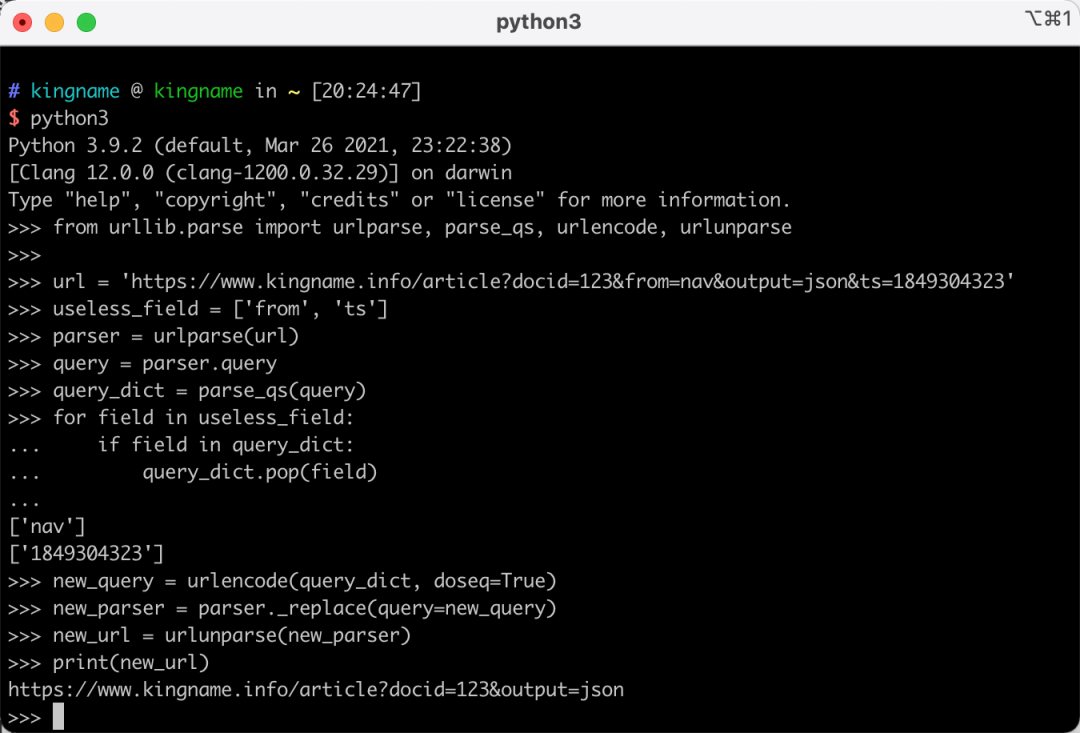
其中urlparse和urlunparse是一对相反的函数,其中前者把网址转成ParseResult对象,后者把ParseResult对象转回网址字符串。
ParseResult对象的.query属性,是一个字符串,格式如下:

parse_qs与urlencode也是一对相反的方法。其中前者把 .query输出的字符串转成字典,而后者把字段转成.query形式的字符串:
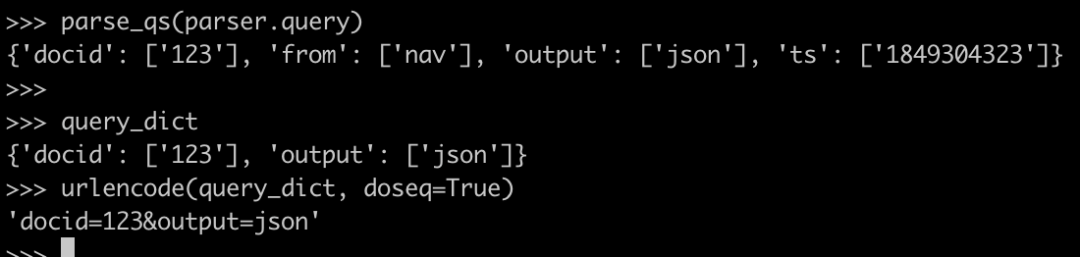
当我们使用parse_qs把 query转成字典以后,就可以使用字典的.pop方法,把无效的字段都移除,然后重新生成新的.query字符串。
由于ParseResult对象的.query属性是只读属性,不能覆盖,因此我们需要调用一个内部方法parser._replace把新的.query字段替换上去,生成新的 ParseResult对象。最后再把它转回网址。
使用这个方法,我们就可以安全地从 URL 中移除无效字段,而不用去写复杂的正则表达式了。
转自:微信公众号:未闻code