如何使用参数给 Scrapy 爬虫增加属性
在Scrapy 项目中,我们有时候需要在启动爬虫的时候,传入一些参数,从而让一份代码执行不同的逻辑。这个时候,有一个非常方便的方法,就是使用-a参数。它的语法为:
scrapy crawl 爬虫名 -a 参数1 -a 参数2 -a 参数3
那么,传入的这些参数,在爬虫里面怎么使用呢?其实很简单,你不需要做任何额外的配置,直接在爬虫里面通过self.参数名就可以调用了。例如下面这个爬虫:
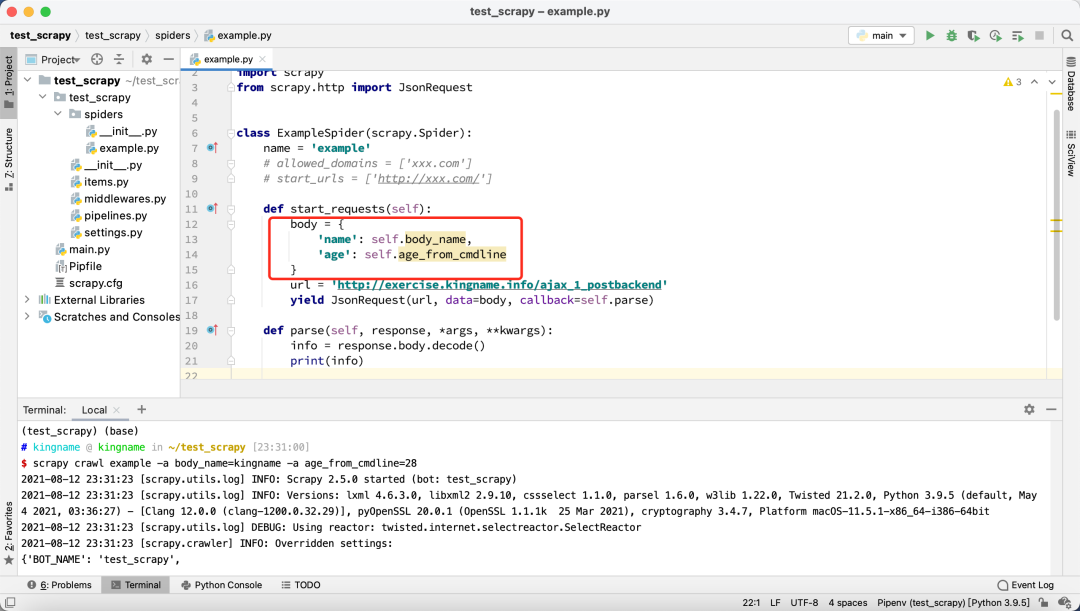
大家可以看到,PyCharm 给两个属性self.body_name和self.age_from_cmdline标上了黄色的背景,这是因为PyCharm 找不到这两个属性是在哪里定义的。
但没有关系,我们启动 Scrapy 爬虫的时候,使用-a参数传递进去就好了:
scrapy crawl example -a body_name=kingname -a age_from_cmdline=28
运行效果如下图所示:
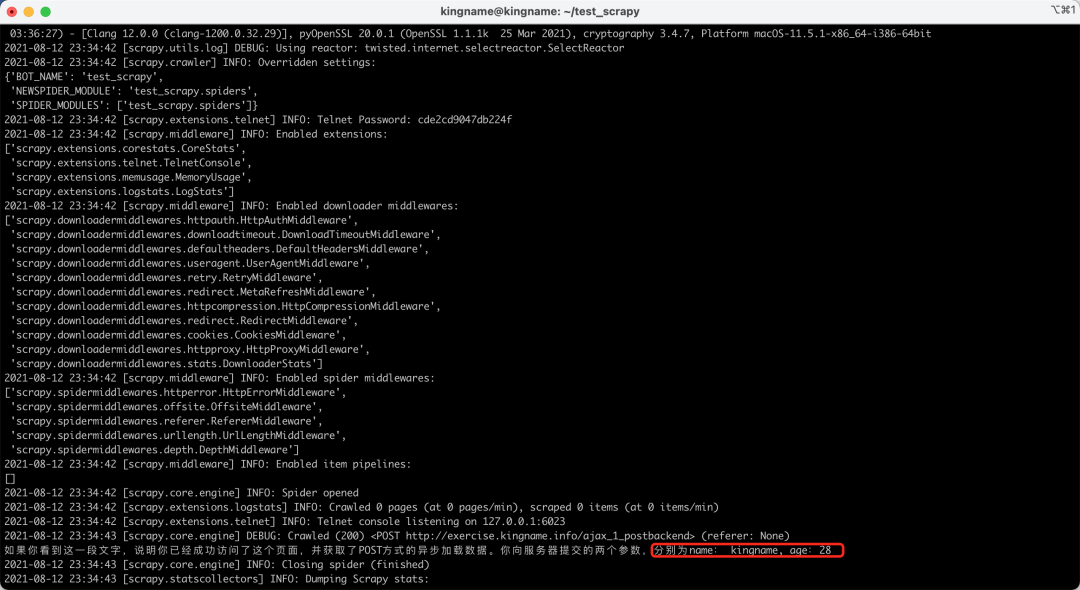
可以看到,这个接口成功接收到了这两个参数,并且把它显示了出来。
通过参数修改Scrapy的配置信息
我们在开发Scrapy爬虫的时候,会把一些常用配置信息写到settings.py中。
例如爬虫需要把数据存入MongoDB里面,那么我可能会把MongoDB的链接URI写到settings.py中:
MONGODB_URI = 'mongodb://localhost' MONGODB_DB = 'test' MONGODB_COL = 'info'
但在正式的项目中,我们开发爬虫的时候,一般会有一个测试数据库,而爬虫部署以后会有一个正式数据库,他们的URI是不一样的。
这个时候,可能有一些同学会把两个配置信息都写到settings.py中:
MONGODB_URI = 'mongodb://localhost' #MONGODB_URI = 'mongodb://user:password@123.15.43.32:7766' MONGODB_DB = 'test' MONGODB_COL = 'info'
在本地开发的时候,把正式环境的地址注释掉,部署的时候,解除正式环境URI的注释,然后把测试地址注释掉。
这种方式虽然简单直接,但容易忘记。特别是一不小心在本地把测试数据写入了正式环境的数据库,那就麻烦了。
但实际上,Scrapy可以在 scrapy crawl xxx的时候,传入配置信息。并且这个配置信息拥有最高优先级,即时settings.py中也有相同名字的配置,命令行传入的也会覆盖它。
在命令行传入配置信息的格式为:
scrapy crawl xxx -s MONGODB_URI='mongodb://user:password@123.15.43.32:7766'
当我们这样启动爬虫的时候,爬虫通过 self.settings['MONGODB_URI']获取到的URI就是正式环境的URI了。
转自:微信公众号:未闻code