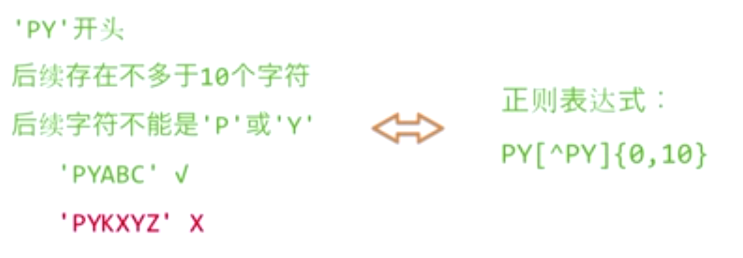
正则表达式:regular expression regex RE
正则表达式是用来简洁表达一组字符串的表达式
通用的字符串表达框架
简洁表达一组字符串的表达式
针对字符串表达“简洁”和“特征”思想的工具
判断某字符串的特征归属
正则表达式在文本处理中十分常用
表达文本类型的特征(病毒、入侵等)
同时查找或替换一组字符串
匹配字符串的全部或部分
正则表达式的使用
编译:将符合正则表达式语法的字符串转换成正则式表达特征

正则表达式的语法
正则表达式语法由字符和操作符构成
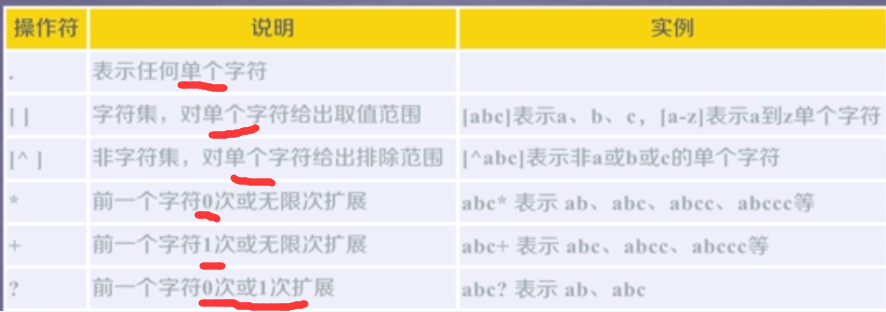
正则表达式的常用操作符
正则表达式的常用操作符

实例


IP地址

Re库的基本使用
Re库介绍:Re库是Python的标准库,主要用于字符串匹配
正则表达式的表示类型


需要多加一个来表示正则表达式的
因此当正则表达式含有转义字符时,需要用raw string
re库的主要函数
大部分都返回match对象

re.search(pattern, string,flags=0)
pattern:正则表达式的字符串或原生字符串表示
string:待匹配字符串
flags:正则表达式使用时的控制标记

re.s可以匹配所有字符
match = re.search(r'[1-9]d{5}','WFR 100860')
if match:
print(match.group(0))
else:
print('error')
100860
re.match(pattern, string,flags=0) 各参数与前述相同
match = re.match(r'[1-9]d{5}','WFR 100860')#此时的match 为空
if match:
print(match.group(0))
else:
print('error')
error
match = re.match(r'[1-9]d{5}','123456 DF')
if match:
print(match.group(0))
else:
print('error')
12re.findall(pattern, string, flags=0) 各参数与前述相同
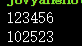
match = re.findall(r'[1-9]d{5}','123456 DF 102523')
print(match)

s = re.findall(r'[d]','123.3 2.3 1000')
print(s)

s = re.findall(r'[d.]','123.3 2.3 1000')
print(s)

s = re.findall(r'[d.]*','123.3 2.3 1000')
print(s)

re.split

match = re.split(r'[1-9]d{5}','SFF123456 DF 102523')
print(match) #删除了匹配部分
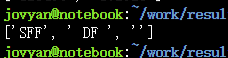
match = re.split(r'[1-9]d{5}','SFF123456 DF 102523',maxsplit=1)
print(match)

re.finditer(pattern, string, flags=0) 各参数与前述相同
for i in re.finditer(r'[1-9]d{5}','SFF123456 DF 102523'):
if i :#一定要先判断,如果为空会报错NoneType
print(i.group(0))
re.sub

print(re.sub(r'[1-9]d{5}',':okok','SFF123456 DF 102523'))
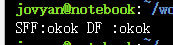
print(re.sub(r'[1-9]d{5}',':okok','SFF123456 DF 102523',count=1))

re库的另一种等价写法

rst = pat.search('BIT 100081') #此时需要把正则表达式参数去掉
regex = re.compile(pattern,flags=0)

也就等价于
大部分都返回match对象

Re库的match对象
match对象的属性

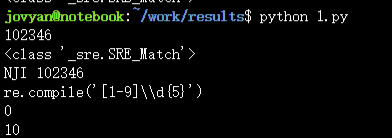
match = re.search(r'[1-9]d{5}','NJI 102346')
if match:
print(match.group(0))
print(type(match))
print(match.string)
print(match.re)
print(match.pos)
print(match.endpos)
match = re.search(r'[1-9]d{5}','NJI 102346')
if match:
print(match.group(0))
print(match.start())
print(match.end())
print(match.span())

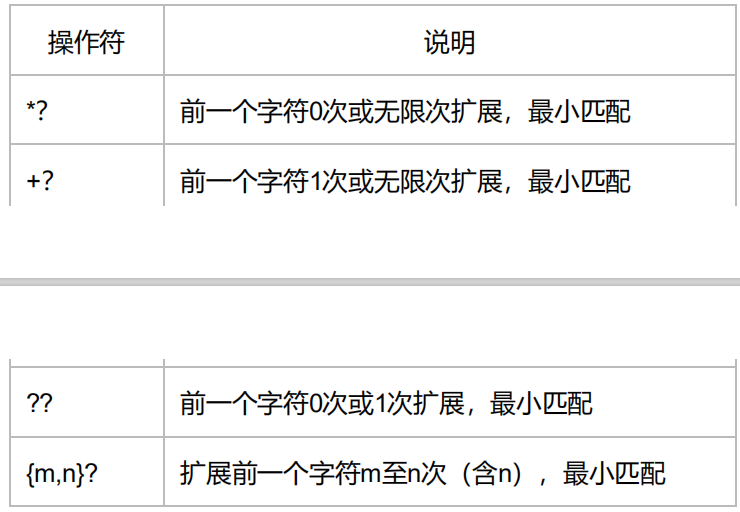
Re库的贪婪匹配和最小匹配
.*

.*?

re库总结
