Python3 urllib.request库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。 在Python中有很多库可以用来抓取网页,我们先学习urllib.request库。
urllib.request库 是 Python3 自带的模块(不需要下载,导入即可使用)
urllib.request库在windows下的路径(C:Python34Liburllib)
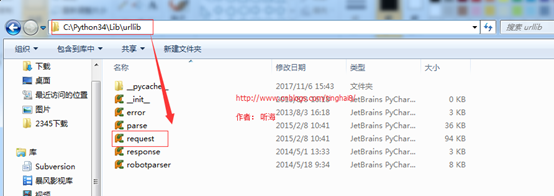
备注:python 自带的模块库文件都是在C:Python34Lib目录下(C:Python34是我Python的安装目录),python第三方模块库都是在C:Python34Libsite-packages 下。

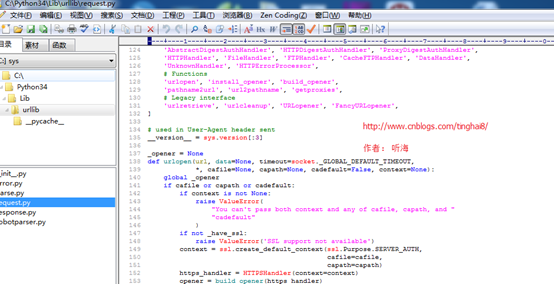
可以通过EditPlus工具或者其他代码查看工具看urllib.request库的相关方法实现的源码。
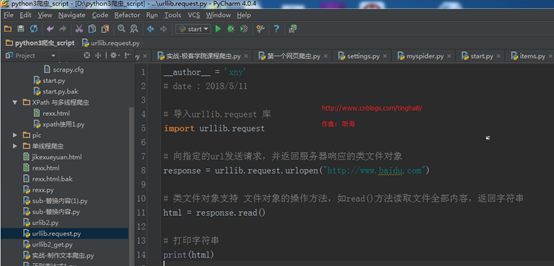
入门的例子一:用urllib.request 里的urlopen()方法发送一个请求
# 导入urllib.request 库
import urllib.request
# 向指定的url发送请求,并返回服务器响应的类文件对象
response = urllib.request.urlopen("http://admin.bxcker.com")
# 服务器返回的类文件对象支持Python文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read()
# 打印响应的内容
print(html)
运行结果:
在PyChram下运行的结果:

在DOS下运行的结果:
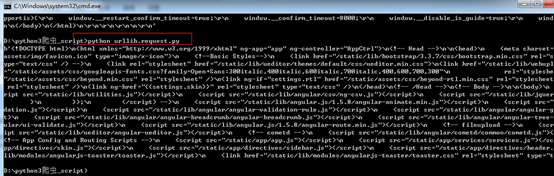
在网页查看源码核实:
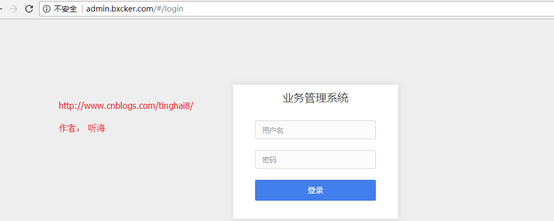
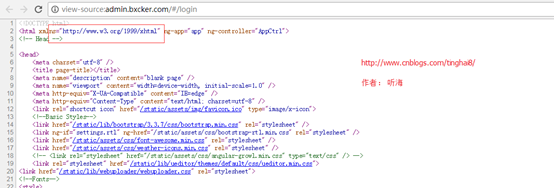
在浏览器上打开http://admin.bxcker.com, 右键选择“查看源代码”,你会发现,跟我们刚才打印出来的是一模一样。也就是说,上面的例子把登陆首页的全部代码爬了下来。
一个基本的url请求对应的python代码是非常的简单,通过例子,说明是可以通过发送请求,获取响应的内容,然后输出显示响应的内容。
备注:urllib.request 里的 urlopen()不支持构造HTTP请求,不能给编写的请求添加head,无法模拟真实的浏览器发送请求。
通过查看urllib.request库的源码文件,查看“User-agent”默认的是client_version
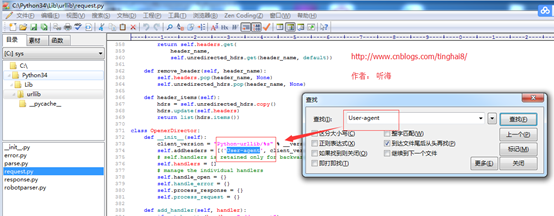
而client_version = "Python-urllib/%s" % __version__
通过查urllib.request库的源码文件,__version__= sys.version[:3]

在Dos下执行sys.version[:3],显示的是3.4。

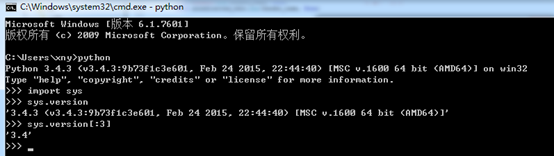
通过验证得出结论:urllib.request库的urlopen()方法默认的“User-agent”是本机Python的版本(User-agent:Python-urllib/3.4),对于服务器而言,一下就能识别出这是爬虫。
在我们第一个入门例子里,urlopen()的参数就是一个url地址;但是如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
例子二:用urllib.request 里的request ()方法发送一个请求
import urllib.request
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://admin.bxcker.com")
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
print(html)
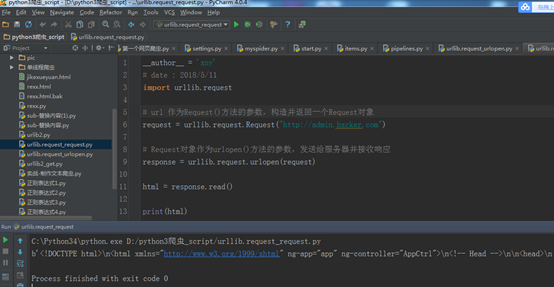
运行结果:跟例子一是一样。
Request实例,除了必须要有 url 参数之外,还可以设置另外两个参数:
data:如果是GET请求,data(默认空),如果是POST请求,需要加上data参数,伴随 url 提交的数据。
headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。
通过抓包可以抓到http://admin.bxcker.com 请求的head信息
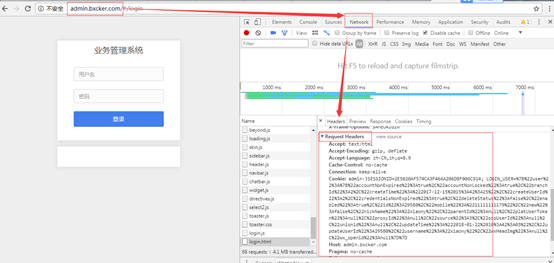
Accept: text/html
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Cookie:admin-JSESSIONID=2E5020AF574CA3F466A206D8F006C914; LOGIN_USER=%7B%22user%22%3A%7B%22accountNonExpired%22%3Atrue%2C%22accountNonLocked%22%3Atrue%2C%22branchId%22%3A2%2C%22createTime%22%3A%222017-12-15%2015%3A42%3A25%22%2C%22createUserId%22%3A2%2C%22credentialsNonExpired%22%3Atrue%2C%22deleteStatus%22%3Afalse%2C%22enabled%22%3Atrue%2C%22id%22%3A29580%2C%22mobile%22%3A%2211111111179%22%2C%22new%22%3Afalse%2C%22nickName%22%3A%22xiaony%22%2C%22parentId%22%3Anull%2C%22platUserToken%22%3Anull%2C%22proxyId%22%3Anull%2C%22source%22%3A3%2C%22ssoUserId%22%3Anull%2C%22unionid%22%3Anull%2C%22updateTime%22%3A%222018-01-22%2010%3A42%3A03%22%2C%22updateUserId%22%3A29580%2C%22username%22%3A%22xiaony%22%2C%22wxHeadImg%22%3Anull%2C%22wx_openid%22%3Anull%7D%7D
Host: admin.bxcker.com
Pragma: no-cache
Referer: http://admin.bxcker.com/
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36
【Host】:主域 (发请求时,可以不写)
【Connection: keep-alive】:保持登录后的长连接
【User-Agent】:最重要的参数
【Accept】:接受数据的格式,例如:text文本、json等
【Accept-Encoding】:数据的压缩方式 (爬虫不是服务器,没有解压方法,不能写)
【Accept-Language】:支持的语言 (可以不写)
【Cookie】:缓存,Cookie在爬虫里主要获取登录后的状态,跟登录相关的可以用Cookie处理,如果只是获取一个静态页面的数据,就不需要用Cookie。
web项目通过都是通过浏览器去访问,要想真实模拟一个用户用浏览器去访问web项目,在发送请求的时候,会有不同的User-Agent头。 urllib2默认的User-Agent头为:Python-urllib/x.y,所以就需要我们在发request请求的时候添加一个head信息
例子三:用urllib.request 里的request ()方法里加上head信息
import urllib.request
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://admin.bxcker.com")
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
print(html)
运行结果:
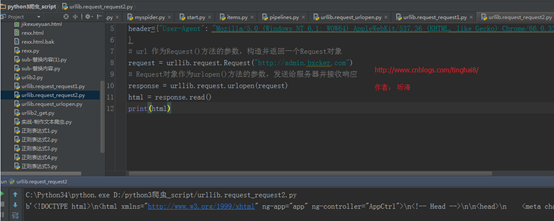
为了验证我们爬虫发的请求,可以用抓包工具去抓我们爬虫发出去的请求,可以看到我们的头文件。
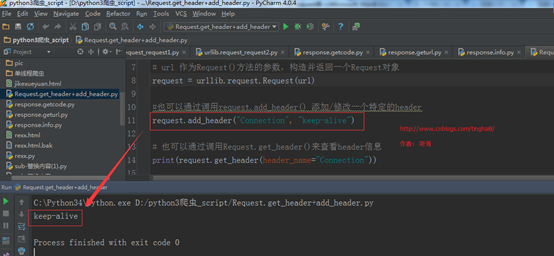
例子四:Request.get_header()与Request.add_header()
import urllib.request
url ="http://admin.bxcker.com"
header={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"
}
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url)
#也可以通过调用request.add_header() 添加/修改一个特定的header
request.add_header("Connection", "keep-alive")
# 也可以通过调用Request.get_header()来查看header信息
print(request.get_header(header_name="Connection"))
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
#print(html)
运行结果:
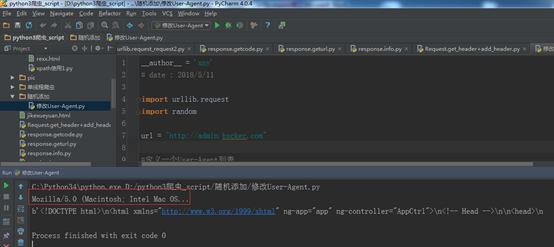
例子五:随机添加/修改User-Agent
import urllib.request
import random
url = "http://admin.bxcker.com"
#定义一个User-Agent列表
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36,",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0)... ",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X.... ",
"Mozilla/5.0 (Macintosh; Intel Mac OS... "
]
#随机抽取一个User-Agent值
user_agent = random.choice(user_agent_list)
# url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request(url)
#通过调用Request.add_header() 添加一个特定的header
request.add_header("User-Agent", user_agent)
# 第一个字母大写,后面的全部小写
print(request.get_header("User-agent"))
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
html = response.read()
print(html)
运行结果:
-------------------------------
个人今日头条账号: 听海8 (上面上传了很多相关学习的视频以及我书里的文章,大家想看视频,可以关注我的今日头条)
