python抽象基类 collections.abc
1. tuple
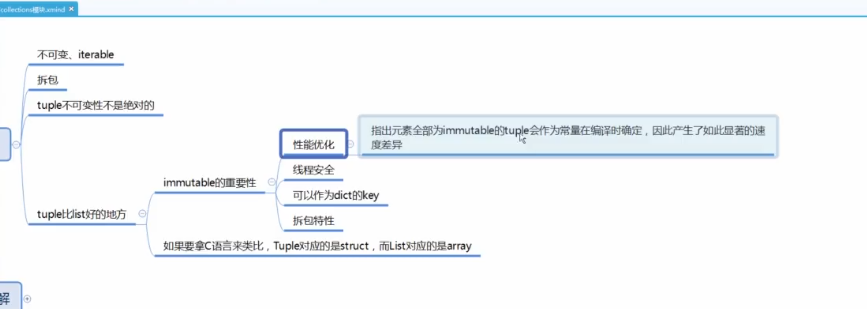
特性: 不可变, 可迭代对象
拆包:
user_tuple = ('name', 29,175)
name,age,height = user_tuple
name,*other = user_tuple
2. namedtuple
|
是tuple的一个子类
nametuple可以帮助我们创建一个类
用 class user这样的方式定义类, 会有很多初始化和参数检查的动作。空间也会复杂一些。
所以一些简单的类的定义,可以用namedtuple来定义类
|
from collections import namedtupled User = namedtuple("User",['name','age','height']) |
| _make方法 |
User = namedtuple("User",['name','age','height'])
user_tuple = ("bobby",29,175)
#user = User(name="dd",age=29,height=172)
user = User._make(user_tuple) print(user.name) >>> bobby
|
| _asdict |
User = namedtuple("User",['name','age','height',"edu"])
user_tuple = ("bobby",29,175)
#user = User(name="dd",age=29,height=172)
#user = User._make(user_tuple) user = User(*user_tuple,edu="master") user_info_dict = user._asdict() print ("user_info_dict:", user_info_dict) print(user.name) >>>>user_info_dict: OrderedDict([('name', 'bobby'), ('age', 29), ('height', 175), ('edu', 'master')])
>>>>bobby |
3. defaultdict
| c语言实现的类, 性能比较高 | |
|
当使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是element字典里,如果不在字典里就会报错
defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,这个默认值是什么呢
default_factory 接收一个工厂函数作为参数, 例如int str list set等.
defaultdict在dict的基础上添加了一个__missing__(key)方法, 在调用一个不存的key的时候, defaultdict会调用__missing__, 返回一个根据default_factory参数的默认值, 所以不会返回Keyerror. |
user_dict = {}
users = ['b1','b2','b3','b7','b4','b3','b1','b2','b2','b7','b4'] for user in users: if user not in user_dict: user_dict[user]=1 else: user_dict[user]+=1 user_dict1 = {}
for user in users: user_dict1.setdefault(user,0) user_dict1[user]+=1 print ("user_dict1:", user_dict1) from collections import defaultdict
default_dict = defaultdict(int)
for user in users:
default_dict[user]+=1 print ("default_dict:", default_dict)
|
4. deque:双端队列
| 使用方法 | import collections d = collections.deque() |
| deque可以从左边添加或者删除元素 |
deque_list = deque(["kk",'tt','ll'])
deque_list.popleft() print ("deque_list:", deque_list)
|
| deque可以构造一个固定大小的队列,当超过队列之后,会把前面的数据自动移除掉 | |
| deque是线程安全的,受GIL保护, list是非线程安全的。 |
5. Counter
| 基本使用 |
from collections import Counter users = ['b1','b2','b3','b7','b4','b3','b1','b2','b2','b7','b4']
print ("coutnter:", dict(Counter(users)))
>>>coutnter: {'b1': 2, 'b2': 3, 'b3': 2, 'b7': 2, 'b4': 2}
|
| update(), 累加 |
from collections import Counter
users = ['b1','b2','b3','b7','b4','b3','b1','b2','b2','b7','b4']
print ("coutnter:",dict(Counter(users)) )
users_count = Counter(users)
users_count.update(["b1","b2"])
print ("users_count:", dict(users_count)
>>>users_count: {'b1': 3, 'b2': 4, 'b3': 2, 'b7': 2, 'b4': 2}
users_count2 = Counter(['b1','b3'])
users_count.update(users_count2)
print ("users_count:", dict(users_count))
>>>users_count: {'b1': 4, 'b2': 4, 'b3': 3, 'b7': 2, 'b4': 2} |
|
most_common(n):统计出现次数最高的前几位数 |
print ("most_common:", users_count.most_common(2)) >>>[('b1', 4), ('b2', 4)] |
6. OrderedDict
| dict的子类 |
from collections import OrderedDict
user_dict = OrderedDict()
user_dict['b'] = 'test2' user_dict['a'] = 'test1' user_dict['c'] = 'test3' print ("user_dict:", dict(user_dict))
>>>{'b': 'test2', 'a': 'test1', 'c': 'test3'}
按照添加的顺序输出, 在python3中OrderedDict和dict都会按添加的顺序输出,但是在python2中,输出的dict是无序的
|
|
popitem pop(key) move_to_end |
7. ChainMap
| 基本使用 |
from collections import ChainMap
user_dict_map = {'a':"b1", 'b':"b2"}
user_dict_map1 = {'c':"m1", 'd':'m2'} #将所有的dict连接起来, 进行循环输出
new_dict = ChainMap(user_dict_map, user_dict_map1)
for key,value in new_dict.items(): print("key:",key) print("value:",value) |
| map | 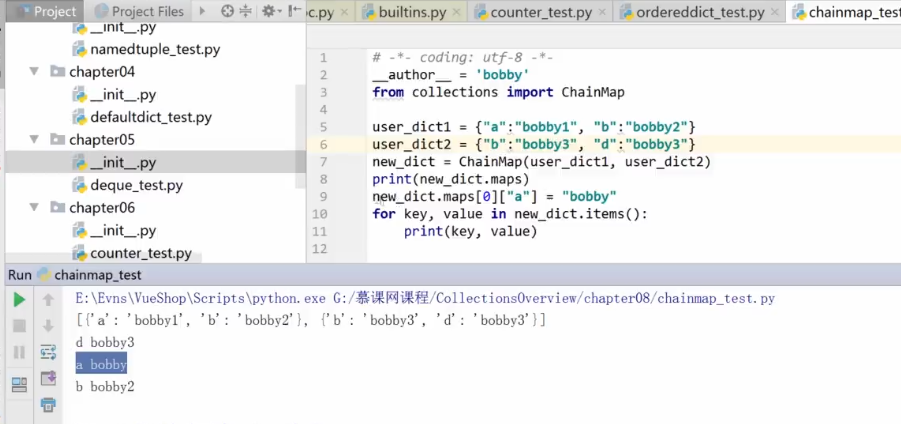 |