背景:
早上刚到公司,运维就语音过来说服务器cup满了,查下问题,紧跟着数据中台小伙伴就说触发了数百个慢SQL。首先根据sql定位到问题点,发现是数据类型跟数据库字段类型对不上,导致索引无效全表扫描,导致sql查询超时,php-fpm请求处理被一直阻塞着。
先上修复代码,同时让运维重启php-fpm清理掉卡死的worker,问题修复。
cup满的请求之前也遇到过,这里来总结一下。
一般情况下,CPU占用100%是从某个时间点开始的,并且报警一般是由云服务上通知,或者发现服务页面有问题,
而部署PHP的应用分为两种:php-fpm处理网络请求、直接使用PHP处理脚本任务。
这里分析php-fpm的问题。
问题定位:
连上服务器,使用top或者htop命令,推荐htop,可以一眼看出cup各个核的使用情况,并且可点击CPU%实现安装CPU使用排序,那个占用最多一目了然。

问题分析:
php-fpm是用来处理网络请求的,
其在整个请求中的位置如图:
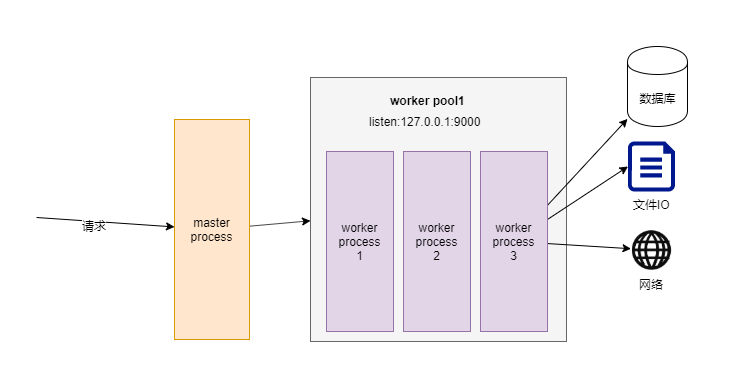
nginx或者apache下游服务器请求丢进来,master分配给pool这些都可以是异步的,但是一个请求分配给worker后,在worker看来就是同步的了,一次只处理一个请求,
所有的请求处理基本都是worker完成的:像读写数据库,读写文件,发起第三方网络请求等等,
所以,当有比如数据库读写超时,文件读写失败像磁盘满了,网络请求卡了,最后一种可能就是程序计算量太大有问题等等,都会让worker等待在那里,
这时候请求源源不断的进来,pool一直新建worker,根据木桶理论,cup这个短板最有可能第一个扛不住,触发报警,反应在接口层面就是接口失效。
方向就是这么个方向:
可以直接观察worker正在处理的工作:
strace是一个可用于诊断、调试和教学的Linux用户空间跟踪器。我们用它来监控用户空间进程和内核的交互,比如系统调用、信号传递、进程状态变更等
strace常用选项:
从一个示例命令来看:
strace -tt -T -v -f -e trace=file -o /data/log/strace.log -s 1024 -p 23489
-tt 在每行输出的前面,显示毫秒级别的时间
-T 显示每次系统调用所花费的时间
-v 对于某些相关调用,把完整的环境变量,文件stat结构等打出来。
-f 跟踪目标进程,以及目标进程创建的所有子进程
-e 控制要跟踪的事件和跟踪行为,比如指定要跟踪的系统调用名称
-o 把strace的输出单独写到指定的文件
-s 当系统调用的某个参数是字符串时,最多输出指定长度的内容,默认是32个字节
-p 指定要跟踪的进程pid, 要同时跟踪多个pid, 重复多次-p选项即可。
这样就可以查看worker当前系统调用等信息。
也可以通过 ls -l /proc/PID/* 查看该进程相关信息
原因可能有以下几种,如果能直接定位想到可以直接验证修复:
1.网络请求量暴增:
需要更多php-fpm的worker,进而导致CPU使用量暴增,这种问题就要从请求量入手:
是否是正常的业务增长,是的话恭喜,通知运维加机器(通知老板加钱嗯嗯),
如果是攻击的话加机器一般是解决不了的,可以通过增加接口方面的验证,严重的话请联系网安
2.依赖项有问题:
比如数据库超时(各种原因:查询慢、数据库被别人搞挂了等等),文件系统问题(磁盘满了,磁盘读写权限没了等等),第三方服务(网络问题,服务问题像超时没处理好)
一般看日志就可以定位问题,但是磁盘满了的话是不会追加日志的,这时候就先看下磁盘,