题目1:假设顾客购物表 customer_shopping 结构如下:
customer commodity amount
A 甲 2
B 乙 4
C 丙 1
A 丁 2
B 丙 5
......
请写出Sql查询所有购入商品为两种或两种以上的购物人记录;
create table customer_shopping(
customer varchar2(10),
commodity varchar2(10),
amount number(20)
)
insert into customer_shopping(customer ,commodity ,amount ) values ('A','甲',2);
insert into customer_shopping(customer ,commodity ,amount ) values ('B','乙',4);
insert into customer_shopping(customer ,commodity ,amount ) values ('C','丙',1);
insert into customer_shopping(customer ,commodity ,amount ) values ('A','丁',2);
insert into customer_shopping(customer ,commodity ,amount ) values ('B','丙',5);
select count(commodity),customer from customer_shopping group by customer having count(commodity)>=2;
--having后不能跟select后的别名,因为先加载having

题目2:假设学生成绩表student_score结构如下:
name course score
张青 语文 72
王华 数学 72
张华 英语 81
张燕 物理 70
张青 化学 76
......
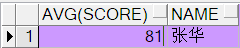
请写出SQL查询出所有“张”姓学生中成绩大于75分的学生信息;
create table student_score( name varchar2(10), course varchar2(10), score number(20) ) insert into student_score(name,course,score) values ('张青','语文',72); insert into student_score(name,course,score) values ('王华','数学',72); insert into student_score(name,course,score) values ('张华','英语',81); insert into student_score(name,course,score) values ('张青','物理',62); insert into student_score(name,course,score) values ('张燕','物理',70); insert into student_score(name,course,score) values ('张青','化学',76); --select * from student_score where name like '张%' select avg(score),s.name from ( select * from student_score where name like '张%') s group by s.name having avg(score)>=75 --以什么条件group by 就只能查出什么,多写就不是group by语句
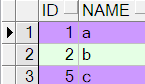
题目3:假设表team结构如下:
ID(number) Name(varchar2)
1 a
2 b
3 b
4 a
5 c
6 c
请写出sql语句执行一个删除操作,当Name列上有相同时,只保留ID这列上值小的记录;
例如:删除后的结果如下:
ID(number) Name(varchar2)
1 a
2 b
3 c
create table team( ID number(10), Name varchar2(10) ) insert into team(ID ,Name ) values (1,'a'); insert into team(ID ,Name ) values (2,'b'); insert into team(ID ,Name ) values (3,'b'); insert into team(ID ,Name ) values (4,'a'); insert into team(ID ,Name ) values (5,'c'); insert into team(ID ,Name ) values (6,'c'); delete from team where ID not in (select minID from (select min(ID) minID from team group by name)); --分组之后的id就是你要的ID,所以删除其他ID即可 select * from team;
删除前:
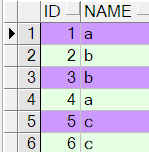
删除后: