1首先介绍查询结果 返回的过程:
进行查询的时候mongodb 并不是一次哪个返回结果集合的所有文档,而是以多条文档的形式分批返回查询的结果,返回文档到内存中。
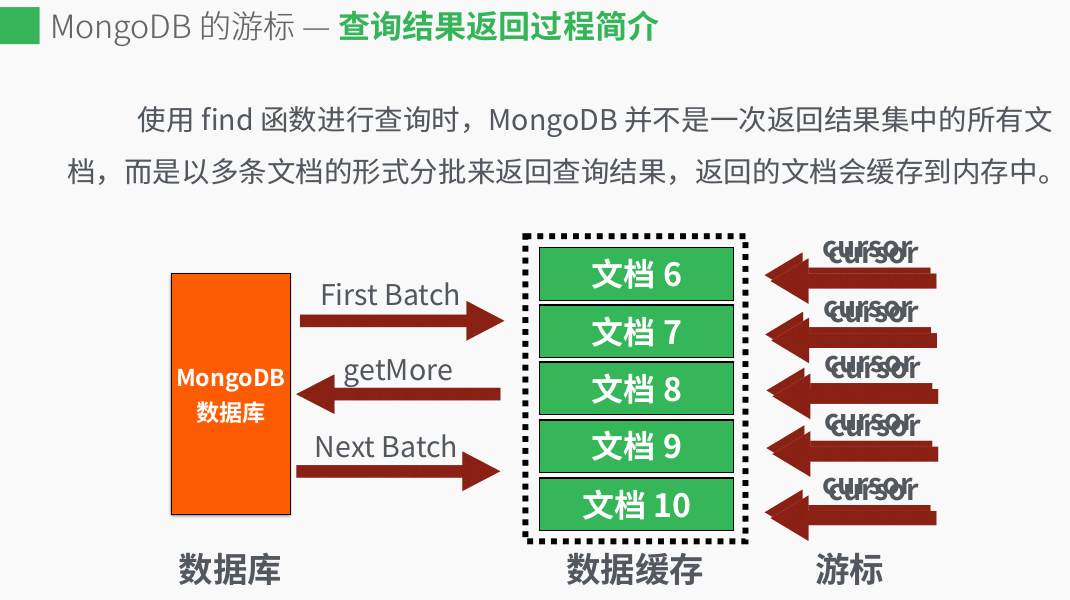
好处:
- 减少了客户端与服务器端的查询负担。
- 查询的结果集合很大的时候批量返回数据,提高了效率。
注意事项
- 如果执行查询的时候不使用 var keyword 则查询的结果会自动迭代 20次。
- cursor 游标第一次返回101条文档或者4兆 数据(谁先满足)。
- 不活跃的游标会在10分钟内自动关闭,或者客户端主动关闭游标,如果让游标一致有效果 可以使用 cursor.noCursorTimeout() 实例 var myCursor = db.inventory.find().noCursorTimeout(); 然后必须主动关闭游标 cursor.close() 或者迭代完毕,否则一致消耗系统资源。
- 驱动或者命令行调用find操作的时候并不会立即查询数据,而是等到真正开始获取数据的时候(hasnext)才发送查询的请求。
- db.**.find().sort({age:1}).limit(2).skip(10) 执行时候跟顺序无关。
- 游标对象每个方法返回都是游标,方便进行链式调用。
接下来比较重要的一点:游标快照
mongodb 在整个生命周期中没有隔离性,当查询结果集很大且在查询的结果集上进行更新操作的时候,可能会返回多次同一个文档。游标可能会返回那些因为体积变大而被移动到集合的末尾的文档,因为MMAPv1 存储引擎(3.2版本的存储引擎已经变为:WiredTiger), 解决方法是对查询进行快照,db.**.find().snapshot(); 使用快照之后查询会在_id索引上执行遍历的操作,保证每一个文档只被返回一次,保证结果的一致性。但是会使查询变慢。
下面介绍一下 mongodb 的存储引擎:
mmapv1存储引擎的分配策略:如果一个文档更新操作查过了文档在磁盘的预先分配的空间,mongodb 会在磁盘上分配一块更大的空间,缺点是:如果集合中有很多索引的话 会花费较多的时间,3.0版本修改了默认的分配策略改为:2的N次方分配策略。有利于减少系统的碎片数量
减少移动的频次,提高了写效率。