问题的提出
在项目中,有些表的记录增长非常快,记录数过大时会使得查询变得困难,导致整个数据库处理性能下降。此时,我们会考虑按一定的规则进行分表存储。
常用的分表方式是按时间周期,如每月一张,每天一张等。当每月或每天首条记录到达时,根据表结构创建该周期为后缀的表进行存储。
相关考虑
这其中主要考虑两个问题:
(1)如何复制表
采用分表机制,通常会建立一个模板表。所谓模板表,是只定义结构不存储数据的,也可称之为类表,而分表,通常会以增加后缀的方式命名,如 log_201901,分表实际存储数据,可称之为实例表。
表存在关联、键、索引、约束等,这让表的复制听起来比较繁琐,即便通过元数据得到这些信息,还需要自己考虑如索引的命名冲突等问题。而 PostgreSQL 为我们提供了极其便捷的方式。
CREATE TABLE [IF NOT EXISTS] 实例表 (LIKE 模板表 [INCLUDING ALL]);
其中 [ ] 内表示可选项,INCLUDING 除了 ALL 还要其它细分的选项,具体可参考帮助文档。
(2)数据存储的逻辑过程
首先得知道表存不存在,不存在则要创建,然后执行数据操作语句。
由于表名是动态的,在应用系统中可以先取得表名形成 SQL 语句再执行,在数据库存储过程中则可以使用 EXECUTE 执行动态SQL语句。
分表实例
下边,本文以日志记录表为例来完整地实践分表处理过程。
功能描述:日志数量大,当前日志查询频繁,历史日志需要全部保存。要求每天一个分表,日志主键要求全局保持唯一性(即多个分表间不重复),日志到达自动根据当前的时间进行分表存储。
首先创建日志模板表,命名为 log_template,并为其建立相关索引,主键序列。
-- 创建模板表,log_id 主键,log_at 日志时间, log_content 日志内容
CREATE TABLE log_template (log_id bigint PRIMARY KEY,
log_at timestamp, log_content varchar(1000));
-- 对日志时间索引
CREATE INDEX idx_log_at on log_template (log_at);
-- 用于主键的序列(各分表使用同一序列)
CREATE SEQUENCE seq_log_id;
我们通过一个过程来完成日志的自动分表存储。
CREATE OR REPLACE FUNCTION func_log(v_conent varchar) RETURNS bool LANGUAGE 'plpgsql'
AS $$
DECLARE
lv_log_at timestamp := current_timestamp;
lv_suffix_tname varchar; -- 带后缀的分表名
lv_dsql text; -- 动态SQL
BEGIN
-- 根据时间得到应使用的分表名称
lv_suffix_tname := 'log_' || to_char(lv_log_at, 'YYYYMMDD');
-- 判断是否存在,不存在时复制模板创建分表
lv_dsql := 'CREATE TABLE IF NOT EXISTS ' || lv_suffix_tname || ' (LIKE log_template INCLUDING ALL)';
EXECUTE lv_dsql;
-- 将数据保存至分表
lv_dsql := 'INSERT INTO ' || lv_suffix_tname || '(log_id, log_at, log_content) VALUES($1, $2, $3)';
EXECUTE lv_dsql USING nextval('seq_log_id'), lv_log_at, v_conent;
RETURN true;
END $$;
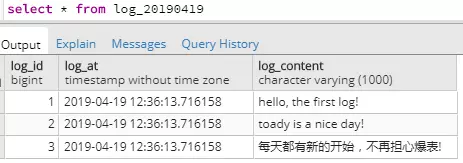
执行以下语句来看看预期的结果。
SELECT func_log('hello, the first log!');
SELECT func_log('toady is a nice day!');
SELECT func_log('每天都有新的开始,不再担心爆表!');
结束语
分表能够避免单表记录过于庞大,提高查询性能。但同时,分表也会给部分查询或数据处理带有复杂性,因此是否分表应该根据业务需要来,同时应尽早规划,后期更改相对繁琐。
在 MySQL 中也有类似的 CREATE TABLE LIKE 语法,我想都是应运而生,简单就是美。