第一次个人作业总结
需求分析
对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
具体要求:
1. 统计文件的字符数(只需要统计Ascii码,汉字不用考虑)
2. 统计文件的单词总数
3. 统计文件的总行数(任何字符构成的行,都需要统计)
4. 统计文件中各单词的出现次数,输出频率最高的10个。
5. 对给定文件夹及其递归子文件夹下的所有文件进行统计
6. 统计两个单词(词组)在一起的频率,输出频率最高的前10个。
ps:
a) 空格,水平制表符,换行符,均算字符
b) 单词的定义:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母:A-Z,a-z
字母数字符号:A-Z,a-z,0-9
分割符:空格,非字母数字符号
时间安排
PSP表:
流程 |
预估时间/h |
实际时间/h |
需求分析 |
0.5 |
0.5 |
具体设计 |
1.5 |
1 |
具体编码 |
6 |
8 |
代码测试 |
2 |
2 |
性能优化 |
2 |
1 |
总结报告 |
2 |
2.5 |
具体时间线:
3.27: 10:00am-10:30am:看博客明确题目要求;
10:30am-11:30am:确定代码模块与功能,查阅资料确定使用的库;
2:00pm-4:00am:完成文件夹遍历,读入所有路径名;
4:00pm-5:00pm:建立好哈希表;
7:00pm-10:00pm:完成字符统计、行数统计、单词统计(修改了哈希表映射结构);
3.28: 2:00pm-3:00pm:完成输出最频繁的10个单词功能;
3:00pm-4:30pm:完成输出最频繁的10个词组功能;
4:30pm-5:00pm:调整变量类型(char* -> string)以适应大测试集;
3.29: 7:00pm-9:00pm:用空文件、官方提供文件等测试集进行测试,调整程序;
9:00pm-10:00pm:性能分析与代码优化。
实现过程
1、首先确定遍历文件方式,为减少模块间的耦合度,先提取出总目录下所有非目录文件的文件名,用 string[] fileName 来存储,方便之后的文件操作。c标准库里提供了一结构体 _finddata_t 来记录文件信息,其中就包含了该文件是否为目录文件,若是,则递归调用遍历函数访问子文件夹;若否,则用 _findnext() 函数找下一文件。将访问过的文件的文件名与其目录结合成路径保存在 fileName 中。
void SearchFiles(char* dir,string fileName[],int& fileNum) { intptr_t handle; _finddata_t findData; char searchdir[200],newdir[200],newfile[200]; strcpy_s(searchdir, dir); strcat_s(searchdir, "\*"); handle = _findfirst(searchdir, &findData); if (handle == -1) { cout << "Failed to find first file! "; return; } do { if (strcmp(findData.name, ".") != 0 && strcmp(findData.name, "..") != 0) { if (findData.attrib == _A_SUBDIR) { strcpy_s(newdir, dir); strcat_s(newdir, "\"); strcat_s(newdir, findData.name); SearchFiles(newdir,fileName,fileNum); } else { strcpy_s(newfile, dir); strcat_s(newfile, "\"); strcat_s(newfile, findData.name); fileName[fileNum]=newfile; fileNum+=1; } } } while (_findnext(handle, &findData) == 0); _findclose(handle); }
2、单词与其出现个数的关系用哈希表来存储,这里采用 C++ STL 函数 unordered_map() <string,int> wordValueMap ,由于按照要求 file 与 FilE231为同一单词,则再建立一张哈希表 unordered_map() <string,int> wordValueMap ,其中 wordValueMap 的 string 存储一个单词最简单的名字,即脱去所有后缀数字且字母全部转化为小写,而 wordNameMap 则将单词的最简名字映射到实际出现的且按照要求应该保留的名字。这种方式将查找名字与选取合适的名字分开,可以更方便地进行哈希表查找。
3、对 fileName 中每个文件进行读操作,使用 fgetc() 进行逐个字符阅读,并存储在 string word 中,若遇到非字母数字字符,则判断 word 是否以四个字母打头,若是则 word 是一个单词,将其写入 wordValueMap (无则添加,已存在则个数加1),并判断是否要在 wordNameMap 中更改它的实际名字。在此过程中同时记录字符数、单词数、行数(出现“ ”则加1,且每个文件最末尾加1)。为了能够统计词组情况,设置了一全局数组 string allWords[] ,将读文件过程中所有的单词(最简单形式)读入 allWords 。
void ReadFile(FILE *fp, unordered_map<string, int>& wordValueMap, unordered_map<string, string>& wordNameMap, int& chrtCount, int& wordCount, int& lineCount) { char ch; string word; unsigned int i,j; unordered_map<string, int>::iterator itValue; unordered_map<string, string>::iterator itName; while ((ch = fgetc(fp)) != EOF) { if (ch >= 32 && ch <= 126) chrtCount++; if ((ch >= 48 && ch <= 57) || (ch >= 65 && ch <= 90) || (ch >= 97 && ch <= 122)) word=word+ch; else { if (word.length() >= 4) { for (i = 0; i < 4; i++) if (!(((word[i] >= 65) && (word[i] <= 90)) || ((word[i] >= 97) && (word[i] <= 122)))) break; if (i >= 4) { for ( j = word.length() - 1; word[j] >= 48 && word[j] <= 57; j--); string newWord(word, 0, j + 1); for (j = 0; j < newWord.length(); j++) if (newWord[j] >= 65 && newWord[j] <= 90) newWord[j] = newWord[j] + 32; allWords[wordCount] = newWord; wordCount++; itValue = wordValueMap.find(newWord); if (itValue == wordValueMap.end()) wordValueMap.insert(pair<string, int>(newWord, 1)); else itValue->second++; itName = wordNameMap.find(newWord); if (itName == wordNameMap.end()) wordNameMap.insert(pair<string, string>(newWord, word)); else if (word.compare(itName->second) < 0) itName->second = word; } } word.erase(); if(ch == ' ') lineCount++; } } lineCount++; }
4、输出文件时可直接输出字符数、行数、单词数,遍历 wordValueMap 找到个数最大的10个单词,用数组 string topTenWordName[] 和 int topTenWordNum[] 来保存名字和个数,在遍历过程中通过与 topTenWordNum 元素不断比较更新该数组,最终得到10个最频繁单词,其真实名称可以通过查询 wordNameMap 获得。将这10个单词与其个数输出。
int GetTopTenWords(unordered_map<string, int> wordValueMap, unordered_map<string, string> wordNameMap, string topTenWordName[], int topTenWordNum[]) { unordered_map<string, int>::iterator itValue = wordValueMap.begin(); unordered_map<string, string>::iterator itName; int i, j,wordNum; for (i = 0; i < 10; i++) { topTenWordNum[i] = 0; topTenWordName[i] = "�"; } while (itValue != wordValueMap.end()) { i = 9; while (itValue->second > topTenWordNum[i] && i >= 0) i--; if (i < 9) { for (j = 9; j > i + 1; j--) { topTenWordNum[j] = topTenWordNum[j - 1]; topTenWordName[j] = topTenWordName[j - 1]; } topTenWordNum[i + 1] = itValue->second; topTenWordName[i + 1] = itValue->first; } itValue++; } wordNum = wordValueMap.size(); if (wordNum >= 10) wordNum = 10; for (i = 0; i < wordNum; i++) { itName = wordNameMap.find(topTenWordName[i]); topTenWordName[i] = itName->second; } return wordNum; }
5、对于词组,我们用到 allWords 数组保存了所有出现过的单词(最简单形式),可遍历该数组并将每相邻的两个单词用“¥”连接组成一新的字符串,即词组,用 unordered_map() <string,int> phraseMap 来保存新的字符串的名字与个数。再用与4中相同的方法可以得到最频繁的10个词组。再将这10个词组的名字由“¥”拆开,分别查询 wordNameMap 得到两个单词的真实名称,用 “ ” 连接后重新赋给词组名,将其名称与个数输出到文件。
int GetTopTenPhrases(unordered_map<string, string> wordNameMap, string topTenPhraseName[], int topTenPhraseNum[],int wordCount) { unordered_map<string, int> phraseMap; unordered_map<string, int>::iterator itPhrase; unordered_map<string, string>::iterator itName; string phrase, word1, word2; int i, j,phraseNum; for (i = 0; i < 10; i++) { topTenPhraseNum[i] = 0; topTenPhraseName[i] = "�"; } for (i = 0; i < wordCount - 1; i++) { phrase = allWords[i] + "$" + allWords[i + 1]; itPhrase = phraseMap.find(phrase); if (itPhrase == phraseMap.end()) phraseMap.insert(pair<string, int>(phrase, 1)); else itPhrase->second++; } itPhrase = phraseMap.begin(); while (itPhrase != phraseMap.end()) { i = 9; while (itPhrase->second >topTenPhraseNum[i] && i >= 0) i--; if (i < 9) { for (j = 9; j > i + 1; j--) { topTenPhraseNum[j] = topTenPhraseNum[j - 1]; topTenPhraseName[j] = topTenPhraseName[j - 1]; } topTenPhraseNum[i + 1] = itPhrase->second; topTenPhraseName[i + 1] = itPhrase->first; } itPhrase++; } phraseNum = phraseMap.size(); if (phraseNum >= 10) phraseNum = 10; for (i = 0; i < phraseNum; i++) { for (j = 0; j < topTenPhraseName[i].length(); j++) if (topTenPhraseName[i][j] == '$') break; word1.assign(topTenPhraseName[i], 0, j); word2.assign(topTenPhraseName[i], j + 1, topTenPhraseName[i].length()); itName = wordNameMap.find(word1); topTenPhraseName[i].assign(itName->second); topTenPhraseName[i].append(" "); itName = wordNameMap.find(word2); topTenPhraseName[i].append(itName->second); } return phraseNum;
6、最终上述得到的结果输出到文件即可。
void WriteFile(ofstream& os, unordered_map<string, int> wordValueMap, unordered_map<string, string> wordNameMap, int chrtCount, int wordCount, int lineCount) { string topTenWordName[10]; int topTenWordNum[10]; string topTenPhraseName[10]; int topTenPhraseNum[10]; int i,wordNum,phraseNum; os << "Char_Number: " << chrtCount << endl; os << "Line_Number: " << lineCount << endl; os << "Words_Number " << wordCount << endl; os << endl; os << "The top ten frequency of words:" << endl; wordNum = GetTopTenWords(wordValueMap,wordNameMap,topTenWordName,topTenWordNum); for (i = 0; i < wordNum; i++) os << "<" << topTenWordName[i] << ">: " << topTenWordNum[i] << endl; os << endl; os << "The top ten frequenzy of phrases:" << endl; phraseNum = GetTopTenPhrases(wordNameMap, topTenPhraseName, topTenPhraseNum, wordCount); for (i = 0; i < phraseNum; i++) os << "<" << topTenPhraseName[i] << ">: " << topTenPhraseNum[i] << endl; }
核心函数都已列出,最后给出主函数。
#include <iostream> #include <fstream> #include <string> #include <cstring> #include <cmath> #include <io.h> #include <unordered_map> using namespace std; void SearchFiles(char* dir,string filename[],int& fileNum); void ReadFile(FILE *fp, unordered_map<string,int>& wordValueMap,unordered_map<string, string>& wordNameMap,int& chrtCount,int& wordCount,int& lineCount); void WriteFile(ofstream& os, unordered_map<string, int> wordValueMap, unordered_map<string, string> wordNameMap, int chrtCount, int wordCount, int lineCount); int GetTopTenWords(unordered_map<string, int> wordValueMap, unordered_map<string, string> wordNameMap, string topTenWordName[],int topTenWordNum[]); int GetTopTenPhrases(unordered_map<string, string> wordNameMap, string topTenPhraseName[], int topTenPhraseNum[],int wordCount); string allWords[20000000]; int main(int arc,char* args[]) { char dir[200]; string fileName[2000]; int i, fileNum = 0,chrtCount = 0,wordCount=0, lineCount = 0; FILE *fp; unordered_map<string,int> wordValueMap; unordered_map<string,string> wordNameMap; strcpy_s(dir, args[1]); SearchFiles(dir,fileName,fileNum); cout << "File Number: " << fileNum << endl; for (i = 0; i < fileNum; i++) { if (fopen_s(&fp,fileName[i].c_str(), "r")!=0) { cerr << "Cannot open file " << fileName[i] << endl; exit(1); } ReadFile(fp, wordValueMap,wordNameMap, chrtCount,wordCount,lineCount); fclose(fp); } cout << "Finish Reading. WordCount: " << wordCount << endl; ofstream os("result.txt", ios::out); if (!os) { cerr << "Cannot write file result.txt!" << endl; exit(1); } WriteFile(os, wordValueMap, wordNameMap, chrtCount,wordCount, lineCount); os.close(); cout << "Finish Writing" << endl; return 0; }
最终结果

在release模式下执行时间为46秒,平均每秒处理377.5万个字符,三个统计总数与参考答案的差距在300以内,最频繁单词、词组的名称与个数均与参考答案一致。
测试分析
每个模块完成时,都要进行单元测试,此时使用的测试集较简单,一个主文件夹下有一个次文件夹和两个txt文件,次文件夹下有一个txt文件和一个次次文件夹,该文件夹下有一个txt文件,每个txt文件内又若干单词。在目录遍历模块与单词统计模块完成后,逐渐将单词种类复杂化,添加 hellow 与 HelLow123这样的相同单词与 *&% 这样的特殊符号以及换行符、制表符等特殊字符。
以上测试相当于黑盒测试,完全针对代码功能,在每个模块都通过测试后,用一些极端的情况来进行白盒测试。由于一开始我的代码使用的是 char* fileName[] 来保存路径,需要分配空间,考虑一些极端的情况,比如文件夹嵌套10层,然后果真出现了写入错误,于是我改为了 string fileName[] 。
同时,除了 文件数目极大的情况,空目录与空文件的情况也要考虑。虽然不知道哪里可能存在问题,我用一空文档进行测试,果然出现了 dereferencable 的问题。debug后发现,读入文件并统计的过程并没有任何问题,但写文件时出现了访问错误,且错误出现在 GetTopTenWord() 函数中:
for (i = 0; i < 10; i++) { itName = wordNameMap.find(topTenWordName[i]); topTenWordName[i] = itName->second; }
分析一下可以发现,当文件中的单词个数不足10个的时候,返回的后几个 itName 为空,赋值给 topTenWordName[i] 的操作必然报错。于是便要针对单词不足10的问题进行修正,将上述代码改为:
wordNum = wordValueMap.size(); if (wordNum >= 10) wordNum = 10;
for (i = 0; i < wordNum; i++) { itName = wordNameMap.find(topTenWordName[i]); topTenWordName[i] = itName->second; }
同样的问题在 GetTopTenPhrase() 中也存在,可作出同样的修正。可见上述极端情形下的越界、空索引的问题,是测试时的主要任务。
在用官方大测试集测试的过程中还发现了一些逻辑问题,比如单词与字符的定义问题,当最终结果与参考答案不符时,分析发现字符统计过多,原因是纳入了asic码不在32到126之间的字符,而单词计数过少,原因是把非字母数字的字符也纳入了单词的组成范围,这些逻辑错误较简单,一般可以在具体编码调试的时候就能发现。
性能分析
利用VS性能探查器进行性能分析,得到如下图的结果摘要:

可见主要的执行时间都在 ReadFile() 和 WriteFile() 两个核心函数上,相对来说遍历文件夹需要的CPU使用率极低。
由于 ReadFile() 是在对所有文件进行统计操作,其占用70%的使用率是可以理解的。具体看 ReadFile() 内部的代码,如下图:

主要的CPU使用都发生在 fgetc() 函数和 word = word + ch 这两个核心操作上,其余琐碎的代码没有过多使用CPU,可见此代码算是比较干净。
再来看 WriteFile() 内部的情况:
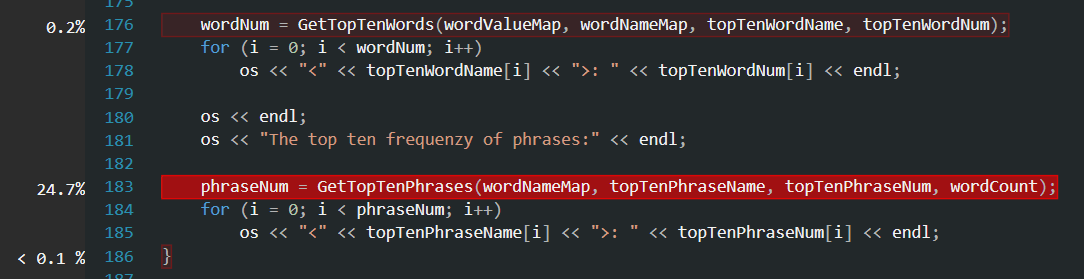
GetTopTenPhrase() 的CPU使用率远高于 GetTopTenWord() ,因为前者要对记录的所有字符串再做一次遍历与变换,如果其主要CPU使用都集中在遍历与变换上而不是与后者相同的排序算法上,那么这个结果就是合理的。看看GetTopTenPhrase() 内部的情况:
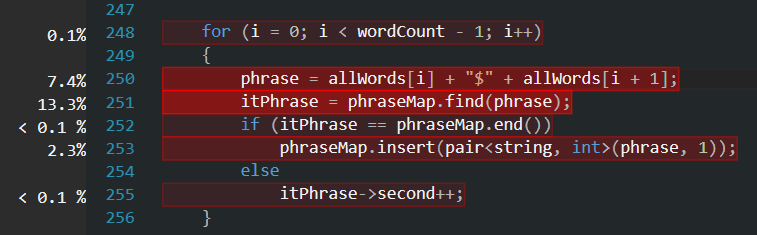
确实, GetTopTenPhrase() 的主要CPU使用都就集中在对字符串的遍历与处理上,可见代码并没有什么过多的冗余。
通过上面的分析,可以说代码总体来说比较干净,并没有什么明显需要修改的地方。如果要进一步提高效率,那么就是将上面 string 类型的内置自己实现,或者说直接只用指针来操作,但是安全性上会有所降低。
经验总结
这次代码由于时间紧迫是在两天内写完的,但是这个过程还是很有收获的。
以前的计算物理、计算方法、数据结构等相关编程课程,很少使用相关的标准库以及内置的数据结构,这次使用了 _finddata_t 以及 unordered_map( ) 两个库,一开始接触多少有些陌生,但看看相关博客和用法上手还是比较快的,重要的是不能畏惧新的东西。技术总是随着时代在更新的,要提高学习新知识的能力,这样才能紧跟时代的步伐。如何在短时间内掌握新的技术是软件工程课教给我们最重要的东西之一。
同时,这次作业也让我们学会了如何选择合适的技术来完成自己的项目,当项目遇到瓶颈时要及时转换实现方式。我一开始选用的哈希表是 hash_map ,这是个非标准化库,不支持 string 类型的默认哈希函数,于是我就用的 hash_map<char*,int > ,结果爆出各种错误,每次读入的键值对都会覆盖原来的表中的内容,后来debug才发现,我把单词 hash_map< char* , int > 插入 hash_map ,如果我继续对 word 操作就相当于对表中元素操作。
于是我每次申请一块新的空间 char* newWord 来保存当前 word 的值再插入表中,这次倒是能正确记录数据,但哈希表的比较函数不能起正确作用(比较函数需人为重载,根据要求判断哪些单词其实是一样的单词),hellow123与Hellow会被认为是不同的单词。并且,一旦跑提供的大测试集 newsample 会出内存错误。这让我懒得再继续调试,果断放弃 hash_map ,使用 unordered_map < string , int > 进行映射。同时,在这个过程中我突然想到,与其重载比较函数,不如再建立一张哈希表,用来记录一个单词最简名字(脱去数字且字母全部小写)与真实名字的映射,这样可以将比较函数分离出来维护,同时也为记录词组提供了便利。所以最终我从一开始的 hash_map<char*,int> 变为最终的 unordered_map()<string,int> wordValueMap 与 unordered_map<string,string> wordNameMap 。
同样的问题在遍历文件夹中也存在,我一开始用一个 char* fileName[] 数组来记录每个文件的具体路径,在我自己的测试用例中是没有问题的,然而一旦跑 newsample 这样的大测试集,就会报内存错误。这次作业中我见识了许多种报错,比如停止运行、写入错误、找不到strcat.asm等,这些错误几乎都与内存出错有关,八成是使用了空指针或者数组越界等,这是就要检查数组索引与指针分配的空间。对于char* 这样的指针是很容易出现溢出问题的,所以在遍历大文件夹的时候还是使用 string 比较好,用效率换安全。我在文件夹遍历函数中将 char* fileName[] 改成了 string fileName[] , 这样就不用考虑分配内存的问题。需要使用 char* 型参数的函数直接使用 fileName[i].c_str() 即可。
像这次作业这样频繁操作字符串的代码最容易出问题的就是内存管理,如果解决了这些问题具体算法倒不是问题。总结一下,如果追求效率一定要维护好指针的指向,先分配空间再使用,且要清楚地知道它指向的对象,特别要小心别的指针修改了自己指向的空间;如果不想用人脑去管理内存,那就用高度封装的数据类型和STL库吧。