一、ZK集群安装。 解压安装包后进入conf目录,conf/zoo_sample.cfg拷贝一份命名为zoo.cfg,同时也放在conf下面。 zookeeper配置文件: # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/app/zookeeper/zookeeperdata dataLogDir=/app/zookeeper/zookeeperlog # the port at which the clients will connect clientPort=2185 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=10.131.156.170:3888:4888 server.2=10.131.156.169:5888:6888 server.3=10.131.156.168:7888:8888
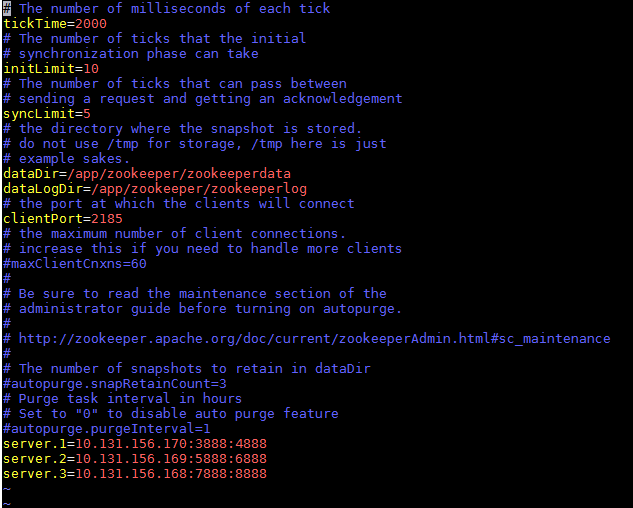
配置参数说明: tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。 dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。 clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。 initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒 syncLimit:这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是2*2000=4 秒 server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号 注意:dataDir,dataLogDir中的wwb是当前登录用户名,data,logs目录开始是不存在,需要使用mkdir命令创建相应的目录。并且在该目录下创建文件myid,serve1,server2,server3该文件内容分别为1,2,3。 针对服务器server2,server3可以将server1复制到相应的目录,不过需要注意dataDir,dataLogDir目录,并且文件myid内容分别为2,3 依次用bin/zkServer.sh start启动三台服务器即可。 启动成功后可以用命令bin/zkCli.sh -server 10.131.156.170 :2185 去链接服务。链接成功后如图:
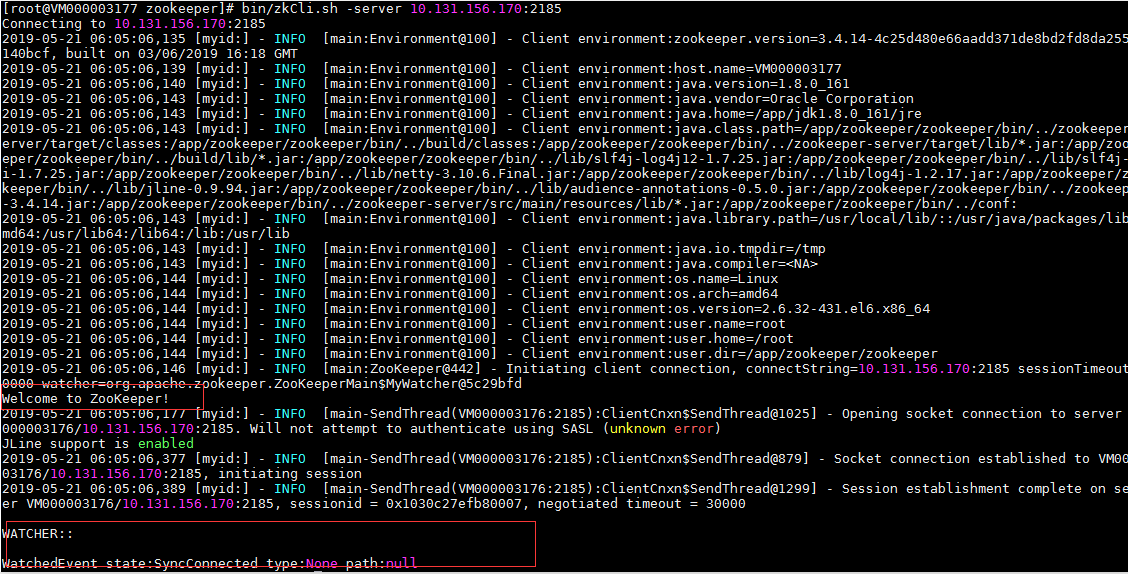
用ls / 起查看zk内部结构:

kafka配置文件: broker.id=2 port=9092 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/app/kafka/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 zookeeper.connect=10.131.156.170:2185,10.131.156.169:2185,10.131.156.168:2185 zookeeper.connection.timeout.ms=6000000 group.initial.rebalance.delay.ms=0 kafka.metrics.polling.interval.secs=5 kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter kafka.csv.metrics.dir=/tmp/kafka_metrics kafka.csv.metrics.reporter.enabled=false ----------------------------------------------------------------------------------------------------------- ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=10.131.156.170:2185,10.131.156.169:2185,10.131.156.168:2185 (2185对应为zk配置文件中的客户端端口,clientport) # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000000 group.initial.rebalance.delay.ms=0 kafka.metrics.polling.interval.secs=5 kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter kafka.csv.metrics.dir=/tmp/kafka_metrics kafka.csv.metrics.reporter.enabled=false kafka启动: bin/kafka-server-start.sh config/server.properties &
创建topic: bin/kafka-topics.sh --create --zookeeper 10.131.156.170:2185 --replication-factor 1 --partitions 1 --topic gyltest

查看已经存在的topic: bin/kafka-topics.sh --list --zookeeper 10.131.156.170:2185 查看指定Topic状态 bin/kafka-topics.sh --describe --zookeeper 10.131.156.170:2185 --topic gyltest 启动Consumer读取消息并输出到标准输出 bin/kafka-console-consumer.sh --zookeeper 10.131.156.170:2185 --topic gyltest --from-beginning 创建发送者 >bin/kafka-console-producer.sh --broker-list 10.131.156.170:2185 --topic gyltest my test message1 my test message2 创建消费者: bin/kafka-console-consumer.sh --zookeeper 10.131.156.170:2185 --from-beginning --topic gyltest ... my test message1 my test message2 bin/kafka-run-class.sh kafka.admin.ConsumerGroupCommand --zookeeper 10.131.156.169:2185 --topic gyltest bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper=10.131.156.169:2185 --group=test-consumer-group bin/kafka-console-consumer.sh -zookeeper 10.131.156.169:2185 --from-beginning --topic gyltest bin/kafka-console-producer.sh --broker-list 10.131.156.169:2185 --topic gyltest kafka-run-class.sh kafka.tools.ConsumerOffsetChecker #kafka查看topic各个分区的消息的信息 kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group ** --topic *** --zookeeper *:2181,*:2181,*:2181/kafka --zookeeper 那里是指kafka在zk中的path,即使zk有多个机器,如果在其中一台上执行此命令,显示连接不上,只写那台机器的地址端口+kafka的path即可 指定自己的分组 自己消费的topic会显示kafka总共有多少数据,以及已经被消费了多少条 结果: GROUP TOPIC PID OFFSET LOGSIZE LAG 消费者组 话题id 分区id 当前已消费的条数 总条数 未消费的条数 bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group test-consumer-group --topic gyltest --zookeeper 10.131.156.170:2185,10.131.156.169:2185,10.131.156.168:2185/kafka