最近学习了下webmagic,学webmagic是因为想折腾下爬虫,但是自己学java的,又不想太费功夫,所以webmagic是比较好的选择了。
写了几个demo,源码流程大致看了一遍。想着把博客园的文章列表爬下来吧。
首页显示的就是第一页文章的列表,
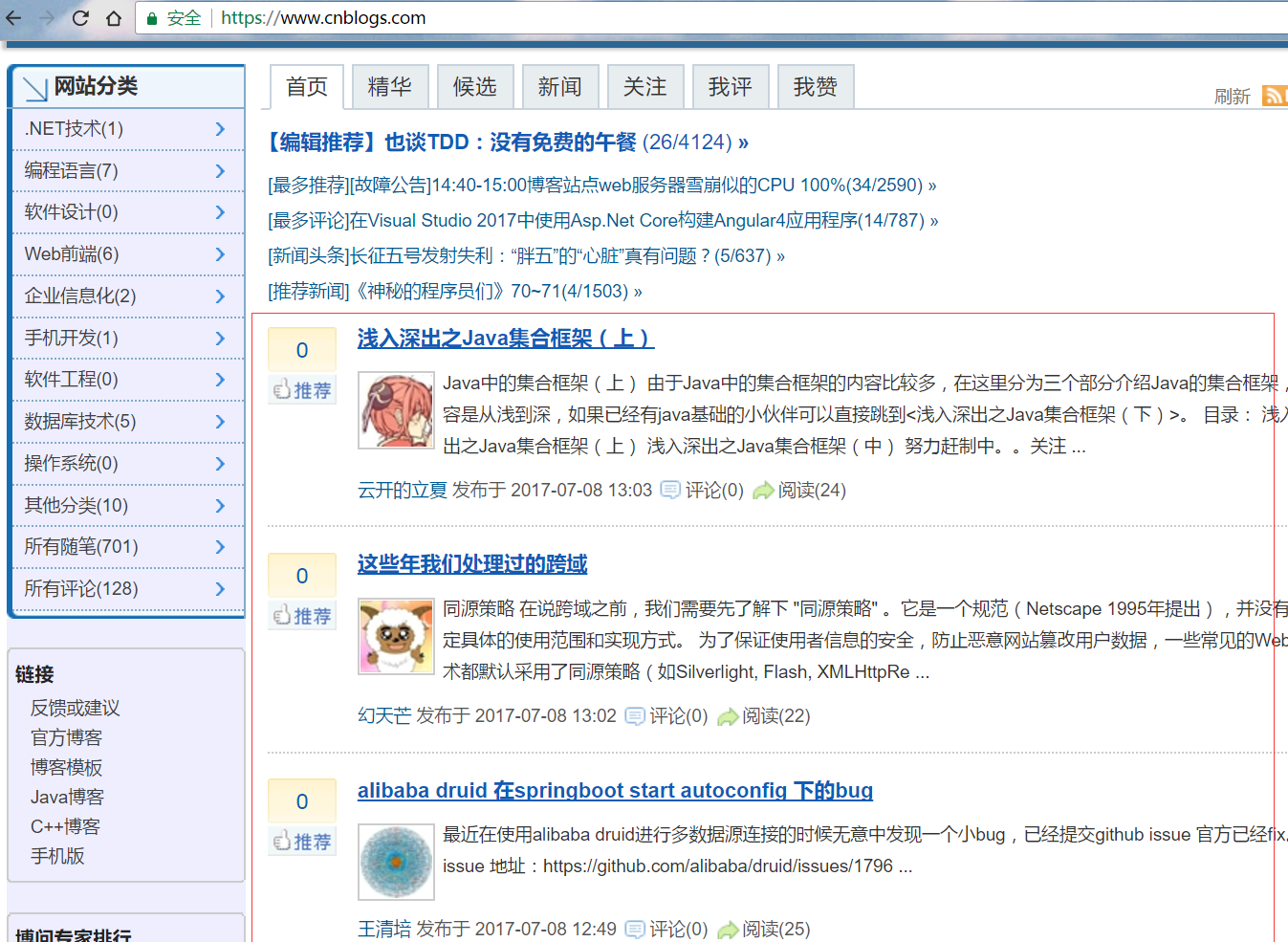
但是翻页按钮不是链接,而是动态的地址:

实际请求的地址及参数:
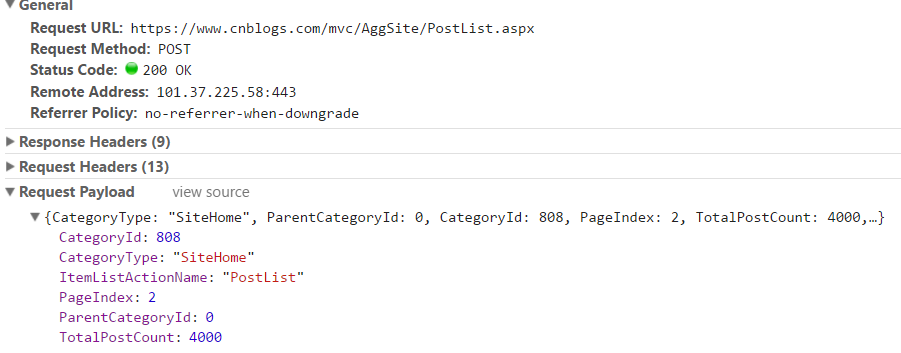
针对这个动态页面的情况,有两种解决方案:
1. webmagic模拟post请求,获取返回页面。
1 public class CnblogsSpider implements PageProcessor { 2 3 private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000) 4 .addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"); 5 6 public static final String URL_LIST = "https://www.cnblogs.com/mvc/AggSite/PostList.aspx"; 7 8 public static int pageNum = 1; 9 10 public void process(Page page) { 11 12 if (page.getUrl().regex("^https://www\.cnblogs\.com$").match()) { 13 try { 14 page.addTargetRequests(page.getHtml().xpath("//*[@id="post_list"]/div/div[@class='post_item_body']/h3/a/@href").all()); 15 pageNum++; 16 //模拟post请求 17 Request req = new Request(); 18 req.setMethod(HttpConstant.Method.POST); 19 req.setUrl("https://www.cnblogs.com/mvc/AggSite/PostList.aspx"); 20 req.setRequestBody(HttpRequestBody.json("{CategoryType: 'SiteHome', ParentCategoryId: 0, CategoryId: 808, PageIndex: " + pageNum 21 + ", TotalPostCount: 4000,ItemListActionName:'PostList'}", "utf-8")); 22 page.addTargetRequest(req); 23 } catch (Exception e) { 24 e.printStackTrace(); 25 } 26 } else if (page.getUrl().regex(URL_LIST).match() && pageNum <= 200) { 27 try { 28 Thread.sleep(5000); 29 List<String> urls = page.getHtml().xpath("//*[@class='post_item']//div[@class='post_item_body']/h3/a/@href").all(); 30 page.addTargetRequests(urls); 31 //模拟post请求 32 Request req = new Request(); 33 req.setMethod(HttpConstant.Method.POST); 34 req.setUrl("https://www.cnblogs.com/mvc/AggSite/PostList.aspx"); 35 req.setRequestBody(HttpRequestBody.json("{CategoryType: 'SiteHome', ParentCategoryId: 0, CategoryId: 808, PageIndex: " + ++pageNum 36 + ", TotalPostCount: 4000,ItemListActionName:'PostList'}", "utf-8")); 37 page.addTargetRequest(req); 38 System.out.println("CurrPage:" + pageNum + "#######################################"); 39 40 } catch (Exception e) { 41 e.printStackTrace(); 42 } 43 } else { 44 // 获取页面需要的内容,这里只取了标题,其他信息同理。 45 System.out.println("抓取的内容:" + page.getHtml().xpath("//a[@id='cb_post_title_url']/text()").get()); 46 } 47 } 48 49 public Site getSite() { 50 return site; 51 } 52 53 public static void main(String[] args) { 54 Spider.create(new CnblogsSpider()).addUrl("https://www.cnblogs.com").thread(3).run(); 55 } 56 }
2.使用webmagic-selenium
1 public class SeleniumCnblogsSpider implements PageProcessor { 2 3 private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000) 4 .addHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"); 5 6 public static final String URL_LIST = "https://www\.cnblogs\.com/#p\d{1,3}"; 7 8 public static int pageNum = 1; 9 10 public void process(Page page) { 11 12 13 if (page.getUrl().regex("^https://www\.cnblogs\.com$").match()) {//爬取第一页 14 try { 15 page.addTargetRequests(page.getHtml().xpath("//*[@id="post_list"]/div/div[@class='post_item_body']/h3/a/@href").all()); 16 17 pageNum++; 18 page.addTargetRequest("https://www.cnblogs.com/#p2"); 19 } catch (Exception e) { 20 e.printStackTrace(); 21 } 22 } else if (page.getUrl().regex(URL_LIST).match() && pageNum <= 200) {//爬取2-200页,一共有200页 23 try { 24 List<String> urls = page.getHtml().xpath("//*[@class='post_item']//div[@class='post_item_body']/h3/a/@href").all(); 25 page.addTargetRequests(urls); 26 27 page.addTargetRequest("https://www.cnblogs.com/#p" + ++pageNum); 28 System.out.println("CurrPage:" + pageNum + "#######################################"); 29 30 } catch (Exception e) { 31 e.printStackTrace(); 32 } 33 } else { 34 // 获取页面需要的内容 35 System.out.println("抓取的内容:" + page.getHtml().xpath("//a[@id='cb_post_title_url']/text()").get()); 36 } 37 } 38 39 public Site getSite() { 40 return site; 41 } 42 43 public static void main(String[] args) { 44 System.setProperty("selenuim_config", "D:/config.ini");//配置文件,我用的webmagic0.7.2,低版本可能不需要该文件,但也不支持phantomjs. 45 Downloader downloader = new SeleniumDownloader();//调用seleniumdownloader,这个downlaoder可以驱动selenium,phantomjs等方式下载,由config.ini配置 46 downloader.setThread(10); 47 Spider.create(new SeleniumCnblogsSpider()).setDownloader(downloader).addUrl("https://www.cnblogs.com").thread(10).runAsync(); 48 } 49 }
另附我的config.ini和pom文件:
1 # What WebDriver to use for the tests 2 driver=phantomjs 3 #driver=firefox 4 #driver=chrome 5 #driver=http://localhost:8910 6 #driver=http://localhost:4444/wd/hub 7 8 # PhantomJS specific config (change according to your installation) 9 #phantomjs_exec_path=/Users/Bingo/bin/phantomjs-qt5 10 phantomjs_exec_path=d:/phantomjs.exe 11 #phantomjs_driver_path=/Users/Bingo/Documents/workspace/webmagic/webmagic-selenium/src/main.js 12 phantomjs_driver_loglevel=DEBUG
1 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 2 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> 3 <modelVersion>4.0.0</modelVersion> 4 <groupId>com.summit</groupId> 5 <artifactId>WebMagicDemo</artifactId> 6 <version>0.0.1-SNAPSHOT</version> 7 8 <dependencies> 9 <dependency> 10 <groupId>us.codecraft</groupId> 11 <artifactId>webmagic-core</artifactId> 12 <version>0.7.2</version> 13 </dependency> 14 <dependency> 15 <groupId>us.codecraft</groupId> 16 <artifactId>webmagic-extension</artifactId> 17 <version>0.7.2</version> 18 </dependency> 19 <dependency> 20 <groupId>us.codecraft</groupId> 21 <artifactId>webmagic-selenium</artifactId> 22 <version>0.7.2</version> 23 </dependency> 24 <dependency> 25 <groupId>org.seleniumhq.selenium</groupId> 26 <artifactId>selenium-java</artifactId> 27 <version>2.41.0</version> 28 </dependency> 29 </dependencies> 30 </project>
如果依赖版本与此不一致,可能会出问题。
后记:
本文主要记录了我在解决webmagic爬取动态页面的心得。
方法1在可以获取动态访问地址的情况下用,比如通过调试工具,我可以找到第二页实际的访问地址是:https://www.cnblogs.com/mvc/AggSite/PostList.aspx,用这种方法实测效率比较高。但复杂场景下不推荐。
方法2主要是针对复杂场景,在实际地址很难找或者隐藏,网站有反扒措施的情况下通常很好用,因为它是模拟的实际的浏览器,比较耗费资源,效率比方法1低 。
webmagic0.7.2 支持selenium (chrome),phantomjs的模拟浏览器行为的方式获取页面。我在方法2中使用的是phantomjs下载的。selenium 的方式我也试过,但是每次调用下载就会弹出浏览器窗口,很是不爽,也没找到如何解决,所以就不推荐了。
抓取结果截图:
