容器基础
什么是容器
容器其实就是利用操作系统的一些机制为每个应用单独创建一个沙盒的隔离环境,然后在沙盒里面启动应用进程。其实容器不止docker一种,但是docker一些不一样的设计促成了docker的风靡。
为什么需要容器
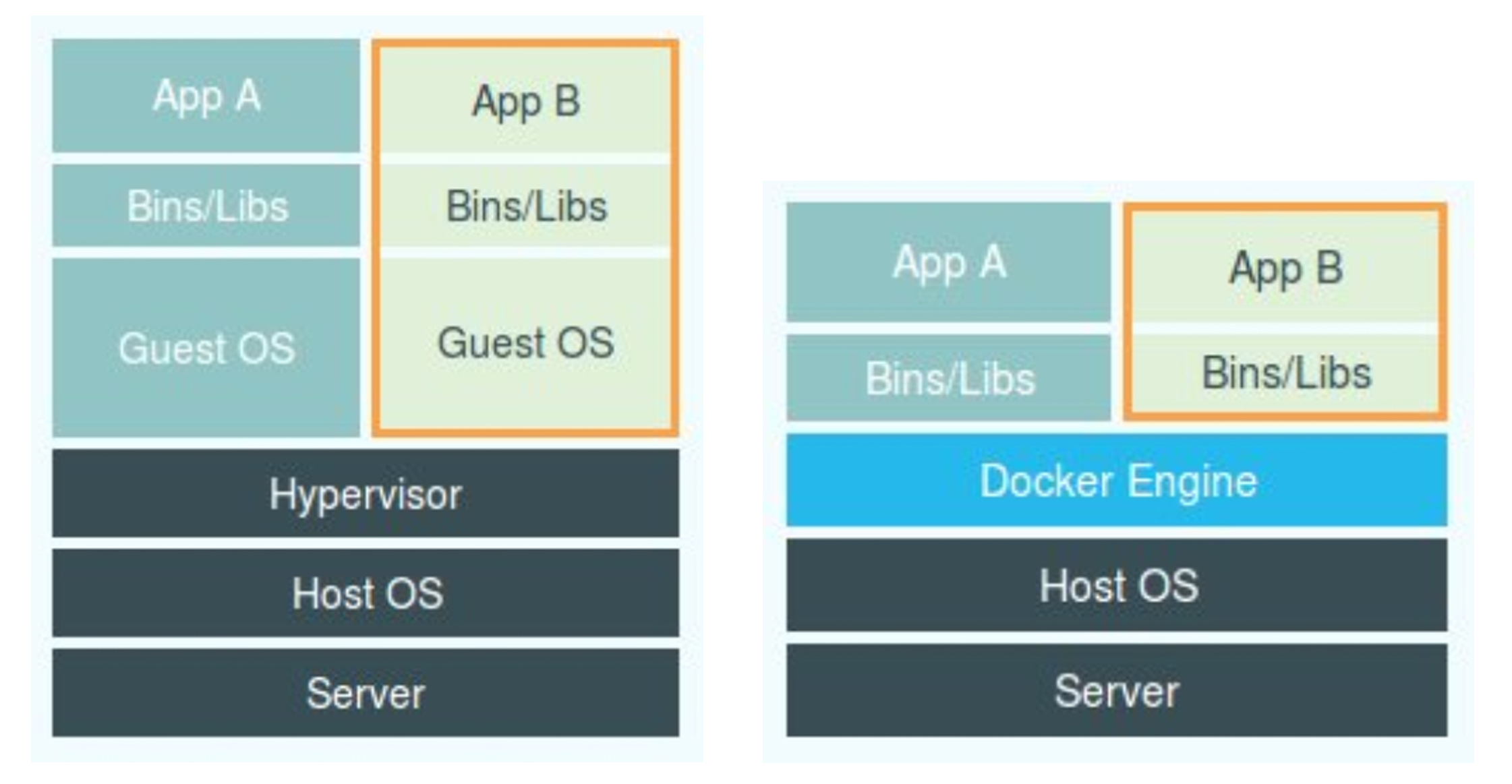
左边虚拟机技术通过硬件虚拟化技术,模拟除了运行一个运行系统所需要的各种硬件,比如CPU、内存、I/O设备等等。然后在这些虚拟的硬件上安装新的操作系统,即Guest OS。用户的应用进程运行在虚拟机上也有一套完整的系统目录和虚拟设备。启动多个虚拟机运行多个应用程序可以达到隔离的效果
容器相对来说更加轻量级,容器在宿主机归根到底也就是一个进程,只是再创建进程的时候加了一些参数,让容器内的进程以为一个人独享一个系统。
容器VS虚拟机
优点:
一个运行这CentOS的虚拟机启动后,本身要占用100-200M的内存空间。另外用户进程运行在虚拟机中,对操作系统调用的时候都需要经过虚拟化软件的拦截和处理,本身又是一层处理,尤其对计算资源、网络和磁盘I/O的损耗很大。
相比之下,容器就是宿主机的一个进程,虚拟化带来的性能损耗不存在。以namespace作为隔离手段也不需要Guest OS,也不需要什么额外的资源。
缺点:
1、namespace相对于虚拟化技术很”敏捷“和”高性能“,但是也有不足之处,最主要的就是隔离的不够彻底。多个容器使用的还是同一个宿主机的操作系统内核。虽然可以通过挂载技术挂载不同版本的操作系统文件,但是并不能改变共享宿主机内核的事实。如果在windows宿主机上运行Linux容器那就行不通了。
2、Linux中很多资源和对象不能被namespace化,最典型的例子就是:时间。在容器中系统调用修改了时间,整个宿主机的时间都会被改变。
docker优势
docker之前,容器最大的问题就是打包问题,在本地运行的好好的应用,一到远程各种环境、依赖问题。docker的出现根本性的解决了这个问题。
一般的PaaS应用包含可执行文件和启动脚本,PaaS服务商提供机器、操作系统和运行环境。但是我们的应用跟当前的系统环境不一定适配,所以会出现各种问题,我们以前也出现过不少这些问题,我本地能运行啊,怎么到了测试网就不行了?然后就被测试同学diss了。
docker之所以能解决这个问题就是直接把完整的操作系统的文件和目录都打包进来了,所以这个压缩包的内容跟本地和测试环境完全无关。这就是docker镜像的厉害之处,保证了本地环境和云端环境的高度一致。
容器的原理
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造一个”边界“,不然容器就跟普通的进程一样。容器就是特殊点的进程。
视图
我们运行一个容器
$ docker run -it busybox /bin/sh
/ #
这段话的意思就是:帮我启动一个容器,在容器里面执行/bin/sh,并且分配一个命令行中断与这个容器进行交互。
我们在容器里执行ps命令
/ # ps
PID USER TIME COMMAND
1 root 0:00 /bin/sh
10 root 0:00 ps
可以看到我们刚刚执行的/bin/sh是容器里的第一号进程,这意味着容器里的进程已经被隔离在一个跟宿主机完全不同的世界。docker容器通过障眼法让容器中的进程以为自己就是头头。实际在宿主机中,该怎样还是怎样。这个机制就是Linux中的namespace机制。
在系统中创建进程的系统调用是clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
系统会为我们创建一个新的进程,并且返回他的进程号。如果我们创建进程的时候指定CLONE_NEWPID参数,比如:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
新创建的进程就会”看到“一个新的进程空间,这样创建多个PID namespace。那每个namespace的应用进程,都会以为自己就是容器中的第1号进程。他们既看不到宿主机里面的真正进程空间,也看不到其他PID namespace里面的具体情况。
除了PID Namespace外,Linux操作系统还提供了Mount、UTS、IPC、Network和User这些不同的namespace,用来对进程进行障眼法操作。
Mount Namespace:宿主机有很多的挂载,Mount Namespace用于让被隔离的进程只看到当前namespace里的挂载点信息。等等
隔离与限制
namespace技术修改了应用进程看待计算机的视图,让它只能看到指定的一些内容。对于宿主机来说,这些容器进程跟一般进程没有什么太大的区别。容器所能使用的资源(CPU、内存)可以随时被宿主机其他进程占用,也可以把所有的资源吃光。对于一个”沙盒“而言显然不太合理。
这就引入了另一个Linux技术:cgroups,它主要用来为进程设置资源限制。包括CPU、内存、磁盘、网络带宽等等
# mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (ro,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (ro,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (ro,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (ro,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (ro,nosuid,nodev,noexec,relatime,memory)
devices on /sys/fs/cgroup/devices type cgroup (ro,nosuid,nodev,noexec,relatime,devices)
freezer on /sys/fs/cgroup/freezer type cgroup (ro,nosuid,nodev,noexec,relatime,freezer)
net_cls on /sys/fs/cgroup/net_cls type cgroup (ro,nosuid,nodev,noexec,relatime,net_cls)
perf_event on /sys/fs/cgroup/perf_event type cgroup (ro,nosuid,nodev,noexec,relatime,perf_event)
net_prio on /sys/fs/cgroup/net_prio type cgroup (ro,nosuid,nodev,noexec,relatime,net_prio)
hugetlb on /sys/fs/cgroup/hugetlb type cgroup (ro,nosuid,nodev,noexec,relatime,hugetlb)
pids on /sys/fs/cgroup/pids type cgroup (ro,nosuid,nodev,noexec,relatime,pids)
rdma on /sys/fs/cgroup/rdma type cgroup (ro,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/systemd type cgroup (ro,nosuid,nodev,noexec,relatime,name=systemd)
目录/sys/fs/cgroup下有很多cpuset、cpu、memory这些子目录。这些就是能被cgroups限制的资源种类。
# ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.rt_period_us notify_on_release
cgroup.procs cpu.rt_runtime_us tasks
cpu.cfs_period_us cpu.shares
cpu.cfs_quota_us cpu.stat
cfs_period和cfs_quota这两个参数组合使用,就可以限制进程在长度为cfs_period的一段时间呢,只能被分配到总量为cfs_quota的CPU时间
除了CPU外,Cgroups的每个子目录都有独有的资源限制能力,比如:
-
cpuset,为进程分配单独的cpu核和对应的内存节点
-
memory,为进程设定内存使用的限制
当我们运行容器的时候,可以直接在docker run指定限制参数:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
启动容器后就可以看到这个容器被限制文件的内容:
root@bfef889df175:/sys/fs/cgroup/cpu# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
20000
Cgroups对资源限制也有不完善的地方,被提及最多的就是/proc文件系统问题。/proc存储的是当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件查看当前正在运行的进程的信息,比如cpu使用情况,内存占用率等。这些文件也是top指令查看系统信息的主要来源。但是如果在容器中执行top命令看到的确是宿主机的CPU和内存数据。造成这个问题的原因就是/proc并不知道Cgroups限制的存在。不过也有修复方法:lxcfs
文件系统
沙盒就相当于一个房子,namespace修改了窗外的视野,墙壁限制了沙盒的活动范围,那文件系统就相当于房子的地板。容器内的应用进程,理应看到一套完整的文件系统,这样就可以在自己的容器目录下操作,完全不受宿主机以及其他容器的影响。
首先想到的就是mount namespace,mount namespace修改的是容器对文件系统”挂载点“的认知。比如宿主机一个/temp目录下有很多文件,在容器中对这个目录重新挂载之后就改变了容器的视图,容器中的/temp目录就为空了。并且这个挂载只有在容器中生效。因为容器会自动继承宿主机的文件系统,所以容器内有很多多余的文件,我们可以通过对容器根目录”/“的挂载,让容器看不见其他的宿主机文件系统
但是这只是改变了容器挂载点的视图,容器内使用的根目录看不见任何文件。Linux中另一个命令可以帮我们完成这个愿望:chroot,改变进程的跟目录到指定位置。创建一个目录,目录里面存放了一整套操作系统的文件和目录。通过chroot命令就可以让容器以为当前目录就是容器的根目录。
这个挂载在容器根目录,用来为容器进程提供隔离后执行环境的文件系统,就是所谓的”容器镜像“,还有个更加专业的名字,叫做:rootfs(根文件系统)。当我们进入容器执行/bin/bash跟宿主机的/bin/bash完全不同。
就是有了rootfs的存在,容器才有了一个重要特性:一致性。对于一个应用来说,操作系统本身才是它运行锁需要的最完整的”依赖库“,而docker这种深入到操作系统的打包,解决了本地和远端环境的问题。
层的概念
文件系统的问题解决了,又有了另一个问题。我通过rootfs打包了一个包含java环境和centos的镜像来部署我的应用。我同事也想用我安装过java环境的rootfs,而不是重复这个流程。一个办法就是每次进行”有意义“的操作都保存一个rootfs出来,同事按需去他需要的rootfs。这样并不具推广性,并且新旧rootfs完全没有关系。
docker另一个创新点就是引入了层的概念。就像我们写项目一样,项目有一些基础功能,我们想加功能A,别人想加功能B。不用每个人都复制一遍项目,就像拉分支一样,每个人维护自己增量的就行。基于基础镜像,我们只用维护对基础镜像的增量内容就可以制作出多种多样的镜像。用户制作镜像的每一步操作都会生成一层,也就是一个增量rootfs。这也是基于一种叫联合文件系统(Union File System)的能力。最主要的功能可以把不同位置的目录联合挂载到同一个目录下面。
$ docker run -d ubuntu:latest sleep 3600
拉取一个Ubuntu镜像到本地,这个所谓的镜像,就是Ubuntu系统的rootfs,不过docker镜像使用的rootfs是由层组成的.
docker image inspect ubuntu:latest
总的来说,容器的rootfs由三个部分组成
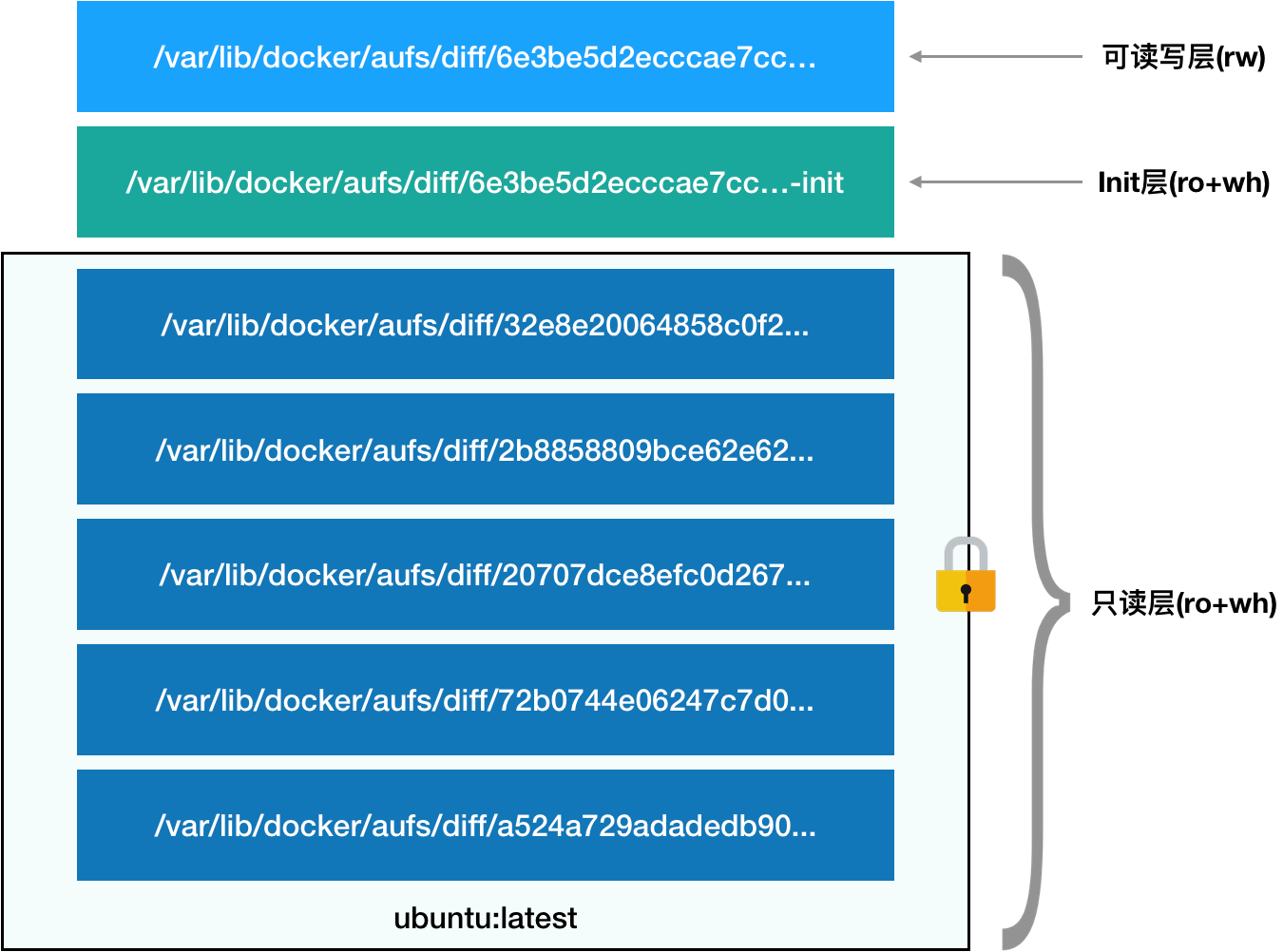
只读层
对应的就是基础容器(ubuntu)的层,挂载方式是只读。
可读写层
位于容器rootfs最上层。没有写入文件钱,这层是空的,一旦再容器里做了写操作,产生的内容就会以增量的方式出现在这一层。比如:创建或者删除了一个文件。我们docker commit和push的时候也会保存被修改过的可读写层,上传到hub上供别人使用。这就是增量rootfs的好处。
Init层
docker项目单独生成的一个内部层,专门来存放/etc/hosts、/etc/resolt.conf等信息。这些文件本来属于只读层的一部分,但是用户往往需要在容器启动的时候指定一些值,比如hostname,所以就需要在可读写层对他们进行修改。