一、存储过程
一:存储过程:存储过程是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中。
可以用存储过程名字和参数来调用存储过程,这样可以避免代码重复出现,用起来也方便。
例: 下面是定义了一个名为Buyfruit的存储过程,参数为购买人的姓名,水果名称,购买数量三个,此存储过程的作用是,输入了这三个参数之后,判断账户余额和库存是否足够,足够的话将账户余额减掉花费,将库存减掉购买的数量显示出来,打印一个订单,和一个明细。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
create PROCEDURE BuyFruit @username varchar(20), @fruitname varchar(20), @buycount int = 0 AS BEGIN declare @kc int,@price float,@fruitid varchar(20) --先把该水果的库存量找出来 select @fruitid=ids, @kc = numbers,@price=price from fruit where name=@fruitname
--根据购买数量和库存的关系,进行购买 if @buycount < @kc begin declare @money decimal(18,2) select @money = account from login where username=@username --根据用户名找到账户余额 if(@money > @price*@buycount) begin update login set account=account-@price*@buycount where username=@username update fruit set numbers = numbers-@buycount where name=@fruitname declare @ordercode varchar(50) set @ordercode ='O'+cast(getdate() as varchar(50)) insert into orders values(@ordercode,@username,GETDATE()) insert into orderdetails values(@ordercode,@fruitid,@buycount) end else begin print '余额不足' end end else begin print '库存不足' end END |
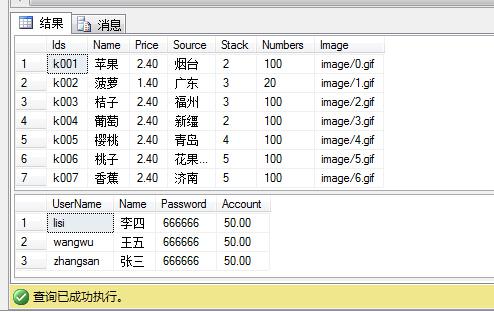
购买之前数据库中的内容:
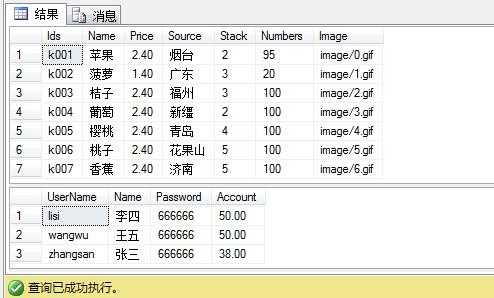
购买成功之后数据库中存储的内容:
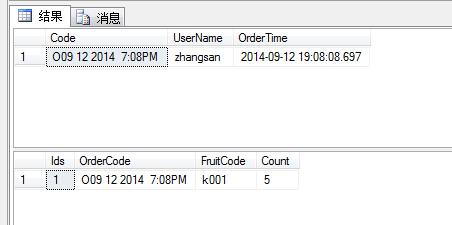
添加到订单的和购买明细:
二:触发器
触发器是一种特殊的存储过程
触发器主要是通过事件进行触发而被自动执行的,而存储过程可以通过存储过程名字而被直接调用
触发器的主要作用就是其能够实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性,另外还有强化约束和级联运行的功能。
关于inserted和deleted临时表
这两个表是由系统管理的,存储在内存中,不是存储在数据库中,因此不允许用户直接对其修改,是只读的,系统在执行插入操作的时候先将数据插入到inserted临时表中,然后再向数据库的表中插入,在插入下一条时这条被删除;执行删除操作的时候,先将数据传到deleted表里,再删除数据,起到一个保存临时数据用来恢复或者记录的作用。
下面这个是做了一个删除时触发的触发器,在删除student表中数据时,将删除的这一行插入到biandong表里面
--用于删除触发的触发器:
create trigger TR_STUDENT_DELETE
on student
for delete --for触发器after触发器,删除后触发
as
declare @no varchar(3),@name varchar(4)
select @no=sno,@name=sname from deleted --用到了临时表
insert into biandong values(@no,@name,'100')
go
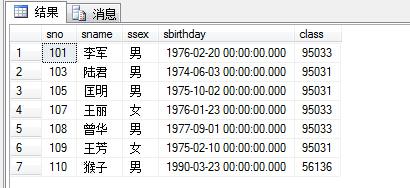
--下面执行删除的时候触发上面的程序,
delete from student where sname='猴子'
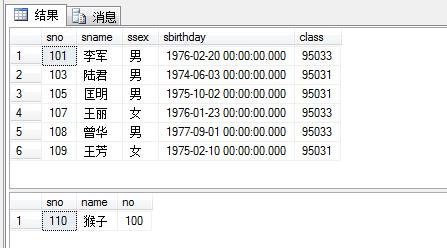
还有一种是instead of触发,触发的时候用触发器里面的程序代替执行操作,即执行触发器里面的东西
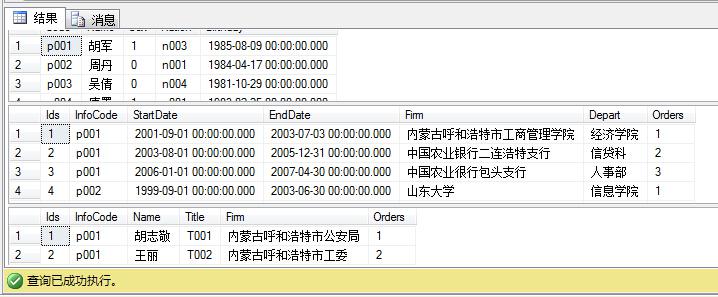
下面例子,原来三个表,由info表里的code约束另外两个表,因此没法单独删除info中的某一行,利用触发器可以删除三个表中code为p001的行
create trigger TR_INFO_DELETE
on info
instead of delete --instead of 触发器,删除的时候替代执行触发器
as
declare @code varchar(20)
select @code=code from deleted
delete from family where infocode=@code
delete from work where infocode=@code
delete from info where code=@code
go
instead of 触发器创建完成下面开始触发:
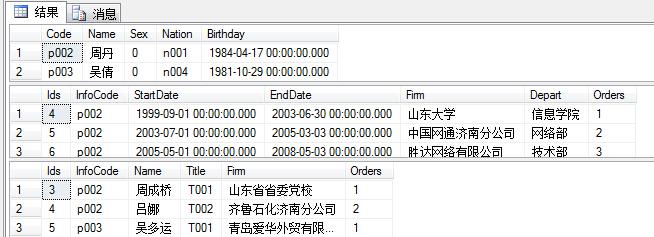
delete from INFO where name ='胡军'
此时删除了三个表中p001的行
D、删除触发器:
drop trigger TR_INFO_DELETE