感知器是由美国计算机科学家罗森布拉特(F.Roseblatt)于1957年提出的。感知器可谓是最早的人工神经网络。单层感知器是一个具有一层神经元、采用阈值激活函数的前向网络。通过对网络权值的训练,可以使感知器对一组输人矢量的响应达到元素为0或1的目标输出,从而实现对输人矢量分类的目的。
下图是一个感知器:
可以看到,一个感知器有如下组成部分:
01 输入权值:
其中,每一个输入分量Xj(j=1,2…,r)通过一个权值分量wj,进行加权求和,并作为阈值函数的输人。偏差 b 的加入(对应上图中的 w0 ,这样是便于书写和理解)使得网络多了一个可调参数,为使网络输出达到期望的目标矢量提供了方便。感知器特别适合解决简单的模式分类问题。
02 激活函数:
激活函数则有较多的选择,较为常见的有sigmoid函数和阶跃函数,这里以阶跃函数为例!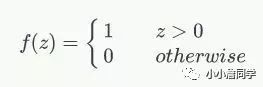
03 输出:
感知器的输出则由如下公式计算得出: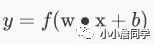
感知器有个屌用呢?F.Roseblatt 已经证明,如果两类模式是线性可分的(指存在一个超平面将它们分开),则算法一定收敛。
举个例子:很多的呀,比如最简单的的布尔运算。可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。它还可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。给你讲讲感知器的训练过程吧!
利用下面的感知器规则迭代的修改参数直到训练完成。
其中,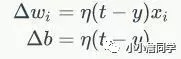
Wi是与输入Xi应的权重项,b 偏置项。事实上,可以把 b 看作是值永远为 1 的输入Xb对应的权重。t 是训练样本的实际值,一般称之为 label。而 y 感知器的输出值,它是根据公式计算得出。η 一个称为学习速率的常数,其作用是控制每一步调整权的幅度。
每次从训练数据中取出一个样本的输入向量 x ,使用感知器计算其输出 y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
下边是根据感知器算法编写出的python代码实现:(实践时是利用一个鸢尾花数据集archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data)
class Perceptron():
"""
eta: learning rate(0.0-1.0)
n_iter:passes over the traing dataset
w_:weights after fitting
errors_:number of misclassifications in every epoch
"""
def __init__(self,eta=1,n_iter=10):
self.eta = eta
self.n_iter = n_iter
def fit(self,X,y):
"""fit training data."""
self.w_ = np.zeros(1 + X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi,target in zip(X,y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self,X):
"""caculate net input"""
return np.dot(X,self.w_[1:]) + self.w_[0]
#a.dot(b) np.dot(a,b) sum(i*j for i,j in zip(a,b))
def predict(self,X):
"""return class label after unit step"""
return np.where(self.net_input(X) >= 0.0, 1, -1)
搭配上必要的绘图模块,可以实现对鸢尾花种类的识别,这里只是对感知器进行介绍,就不过多叙述其他模块了
摘自:https://mp.weixin.qq.com/s/o1OJRPRWCbTwk7dhZgjeHg