K-MEANS算法是一种经典的聚类算法,在模式识别得到了广泛的应用。算法中有两个关键问题需要考虑:一是如何评价对象的相似性,通常用距离来度量,距离越近越相似;另外一个是如何评价聚类的效果,通常采用误差平方和函数来作为评价准则。
算法过程:
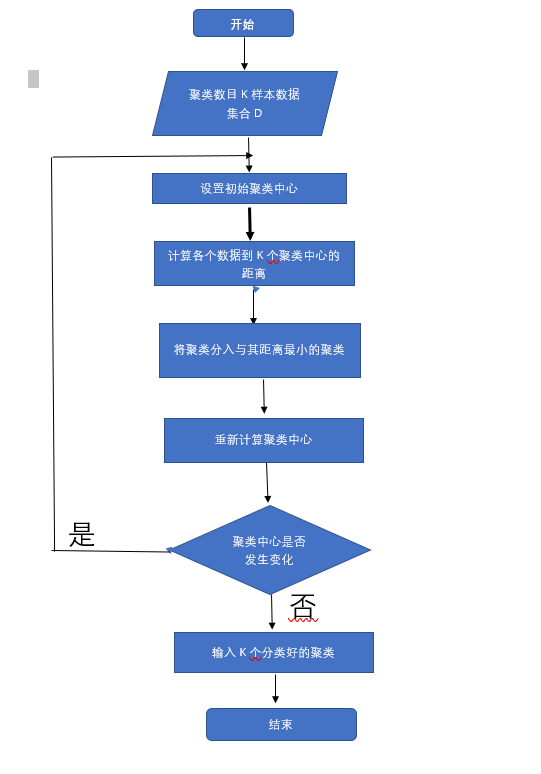
输入:簇的数目K和包含n个对象的数据库。
输出:K个簇,使平方误差和最小
算法步骤:
(1):为每个聚类确定一个初始聚类中心,这样就有K个初始聚类中心
(2:将样本集中的样本按照最小距离原则分配到最邻近聚类
(3);使用每个聚类中的样本均值作为新的聚类中心
(4):重复步骤(2)和(3),直到聚类中心不在变化
(5):结束,得到K个聚类
流程图
代码实现
1 import numpy 2 import random 3 import codecs 4 import copy 5 import re 6 import matplotlib.pyplot as plt 7 #其次计算向量vecl和向量vec2之间的欧式距离 8 def calcuDistance(vec1,vec2): 9 return numpy.sqrt(numpy.sum(numpy.square(vec1-vec2))) 10 #载入数据测试数据集,数据由文本保存,为二维坐标 11 def loadDataSet(): 12 inFile = "F:/testSet.txt" #数据集文件 13 inDate = codecs.open(inFile,'r','utf-8').readlines() 14 dataSet = list() 15 for line in inDate: 16 line = line.strip() 17 strList = re.split('[ ]+',line) #删除多余的空格 18 #print strList[0] ,strList[1] 19 numList = list() 20 for item in strList: 21 num = float(item) 22 numList.append(num) 23 24 dataSet.append(numList) 25 return dataSet 26 27 #初始化K个聚类中心,随机获取 28 def initCentroids(dataSet,k): 29 return random.sample(dataSet,k)#从dataSe中随机获取K个数据项返回 30 #对每个属于dataSet的item,计算item与centrodList中K个聚类中心的欧式距离,找出 31 #距离最小的,并将item加入相应的簇中 32 def minDistance(dataSet,centroidList): 33 clusterDict = dict() #用dict来保存聚类的结果 34 for item in dataSet: 35 vec1 = numpy.array(item) #转换成array形式 36 flag = 0 #簇分类标记,记录与相应的簇距离最近的那个簇 37 minDis = float("inf") #初始化为最大值 38 for i in range(len(centroidList)): 39 vec2 = numpy.array(centroidList[i]) 40 distance = calcuDistance(vec1,vec2) #计算相应的欧拉距离 41 if distance < minDis: 42 minDis = distance 43 flag = i #循环结束时,flag保存的是与当前item距离最近的那个簇标记 44 if flag not in clusterDict.keys():#簇标记不存在,进行初始化 45 clusterDict[flag] = list() 46 clusterDict[flag].append(item) #加入相应的类别中 47 return clusterDict 48 49 #计算每列的均值,即找到聚类中心 50 def getCentroids(clusterDict): 51 #得到K个质心 52 centroidList = list() 53 for key in clusterDict.keys(): 54 centroid = numpy.mean(numpy.array(clusterDict[key]),axis=0) 55 centroidList.append(centroid) 56 return numpy.array(centroidList).tolist() 57 #计算簇集合间的均方误差,将簇类中各个向量与质心的距离进行累加求和 58 def getVar(clusterDict,centroidList): 59 sum = 0.0 60 for key in clusterDict.keys(): 61 vec1 = numpy.array(centroidList[key]) 62 distance = 0.0 63 for item in clusterDict[key]: 64 vec2 = numpy.array(item) 65 distance += calcuDistance(vec1,vec2) 66 sum += distance 67 return sum 68 69 #展示聚类结果 70 def showCluster(centroidList,clusterDict): 71 colorMark = ['or','ob','og','ok','oy','ow'] 72 #不同簇类的标记,'or'-->'o'代表圆形,’r'代表red,‘b’:blue 73 centroidMark = ['dr','db','dg','dk','dy','dw'] #簇类中心标记同上‘d’代表菱形 74 for key in clusterDict.keys():#画簇类中心点 75 plt.plot(centroidList[key][0],centroidList[key][1],centroidMark[key],markersize=12) 76 for item in clusterDict[key]: 77 plt.plot(item[0],item[1],colorMark[key])#画簇类下的点 78 plt.show() 79 80 if __name__=='__main__': 81 # inFile = "F:/testSet.txt" #数据集文件 82 dataSet = loadDataSet() #载入数据集 83 centroidList = initCentroids(dataSet,4) #初始化质心,设置K=4 84 clusterDict = minDistance(dataSet,centroidList) #第一次聚类迭代 85 newVar = getVar(clusterDict,centroidList) #获得均方误差值,通过新旧均方误差来获得迭代终止条件 86 oldVar = -0.0001 #旧均方误差值初始化为-1 87 print("------第一次迭代------") 88 print( ) 89 print("簇类") 90 for key in clusterDict.keys(): 91 print(key,'---->',clusterDict[key]) 92 print("K个均值向量:",centroidList) 93 print("平方均方误差:",newVar) 94 print( ) 95 showCluster(centroidList,clusterDict) #展示聚类结果 96 k = 2 97 while abs(newVar-oldVar) >= 0.0001: #当两次聚类结果小于0.0001时,迭代结束 98 centroidList = getCentroids(clusterDict) #获得新的质心 99 clusterDict = minDistance(dataSet,centroidList) #新的聚类结果 100 oldVar = newVar 101 newVar = getVar(clusterDict,centroidList) 102 print("----第%d次迭代结果--------" %k) 103 print( ) 104 print("簇类") 105 for key in clusterDict.keys(): 106 print(key, '---->', clusterDict[key]) 107 print("K个均值向量:", centroidList) 108 print("平方均方误差:", newVar) 109 print() 110 showCluster(centroidList, clusterDict) # 展示聚类结果 111 k += 1
目前,对于聚类算法的理解还不是很深刻。正在慢慢探索中。