1、看执行计划
EXPLAIN, 此命令用于查看SQL的执行计划

总的来说sql的执行计划是一个树形层次结构, 一般来说阅读上遵从层级越深越优先, 同一层级由上到下的原则。
来跟着铁蛋老师读: 层级越深越优先, 同一层级上到下。
顺序知道了,得知道里面的意思了吧, 是的没错, 但是这个里面比较具体的一些细节这里就不再展开了,只介绍比较常关注的几个关键字:
重点来了,重点来了,睡觉的玩手机的停一停。王老师要开车了, 啊呸, 开课了。
第一行的括号中从左到右依次代表的是:
(估计)启动成本,在开始输出之前花费的时间,例如排序时间。
(估计)总成本, 这里有一个前提是计划节点会完整运行,即所有可用行都会被检索。实际上一些节点的父节点不会检索所有可用行(如LIMIT)。
(估计)输出的总行数,同样的是基于节点会完整运行的假设。
(估计)输出行的平均宽度(以字节为单位)
注意:
cost中描述的是启动成本和总成本,但是到目前为止我们还不知道这个数字代表的具体含义,因为我们不知道它的单位是什么。(所以说这里cost中的成本是具有相对意义,不具有绝对意义)
rows代表的是输出的总行数,他不是计划节点处理或扫描的行数,而是节点发出的行数。由于使用where子句过滤,这个值通常小于扫描的数目。理想情况下,顶级的rows近似于实际的查询返回,更新或删除的行数
2、索引优化
索引尽量建在数据比较分散的列上, 不要在变化很小的字段上加索引,比如性别之类的。
原因就是:
索引本质上是一种空间换时间的操作,通过B Tree这种数据结构减少io的操作次数以此来提升速度。如果在变化很小的字段上建立索引,那么可能单个叶子节点上的数据量也是庞大的,反而增加了io的次数(如果查询字段有包含非索引列,索引命中之后还需要回表)
3、缓存配置
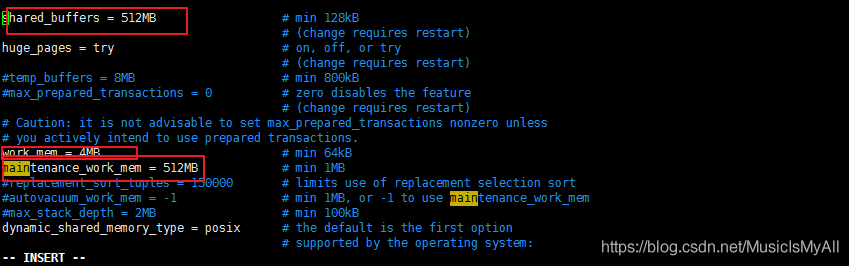
仔细看了上图中的执行计划发现有三个个地方有嫌疑,一个是Hash节点, 一个是Sort, 还有一个是Buffers。
在Hash节点中Batches批处理的数量超过了1, 这说明用到了外存, 原来是内存不够了呀!
Sort节点中,排序方法是归并, 而且是磁盘排序, 原来也是内存不够了。
Buffers 节点中,同一个sql执行两次每次都有新的io,说明缓存空间也不够,最终这三个现象都指向了内存。
铁蛋打开pg的配置文件一看, 我靠,穷鬼呀,才分配了512MB的共享缓存总空间, 进程单独分配了4M空间用于hash,排序等操作,用于维护的分配了512MB。
————————————————
版权声明:本文为CSDN博主「吃饭睡觉不准打豆豆」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/MusicIsMyAll/article/details/103465529
其他文章:https://blog.csdn.net/jui121314/article/details/84584848