前提
这篇文章不是标题党,下文会通过一个仿真例子分析如何优化百万级别数据Excel导出。
笔者负责维护的一个数据查询和数据导出服务是一个相对远古的单点应用,在上一次云迁移之后扩展为双节点部署,但是发现了服务经常因为大数据量的数据导出频繁Full GC,导致应用假死无法响应外部的请求。因为某些原因,该服务只能够分配2GB的最大堆内存,下面的优化都是以这个堆内存极限为前提。通过查看服务配置、日志和APM定位到两个问题:
- 启动脚本中添加了
CMS参数,采用了CMS收集器,该收集算法对内存的敏感度比较高,大批量数据导出容易瞬间打满老年代导致Full GC频繁发生。 - 数据导出的时候采用了一次性把目标数据全部查询出来再写到流中的方式,大量被查询的对象驻留在堆内存中,直接打满整个堆。
对于问题1咨询过身边的大牛朋友,直接把所有CMS相关的所有参数去掉,由于生产环境使用了JDK1.8,相当于直接使用默认的GC收集器参数-XX:+UseParallelGC,也就是Parallel Scavenge + Parallel Old的组合然后重启服务。观察APM工具发现Full GC的频率是有所下降,但是一旦某个时刻导出的数据量十分巨大(例如查询的结果超过一百万个对象,超越可用的最大堆内存),还是会陷入无尽的Full GC,也就是修改了JVM参数只起到了治标不治本的作用。所以下文会针对这个问题(也就是问题2),通过一个仿真案例来分析一下如何进行优化。
一些基本原理
如果使用Java(或者说依赖于JVM的语言)开发数据导出的模块,下面的伪代码是通用的:
数据导出方法(参数,输出流[OutputStream]){
1. 通过参数查询需要导出的结果集
2. 把结果集序列化为字节序列
3. 通过输出流写入结果集字节序列
4. 关闭输出流
}
一个例子如下:
@Data
public static class Parameter{
private OffsetDateTime paymentDateTimeStart;
private OffsetDateTime paymentDateTimeEnd;
}
public void export(Parameter parameter, OutputStream os) throws IOException {
List<OrderDTO> result =
orderDao.query(parameter.getPaymentDateTimeStart(), parameter.getPaymentDateTimeEnd()).stream()
.map(order -> {
OrderDTO dto = new OrderDTO();
......
return dto;
}).collect(Collectors.toList());
byte[] bytes = toBytes(result);
os.write(bytes);
os.close();
}
针对不同的OutputStream实现,最终可以把数据导出到不同类型的目标中,例如对于FileOutputStream而言相当于把数据导出到文件中,而对于SocketOutputStream而言相当于把数据导出到网络流中(客户端可以读取该流实现文件下载)。目前B端应用比较常见的文件导出都是使用后一种实现,基本的交互流程如下:
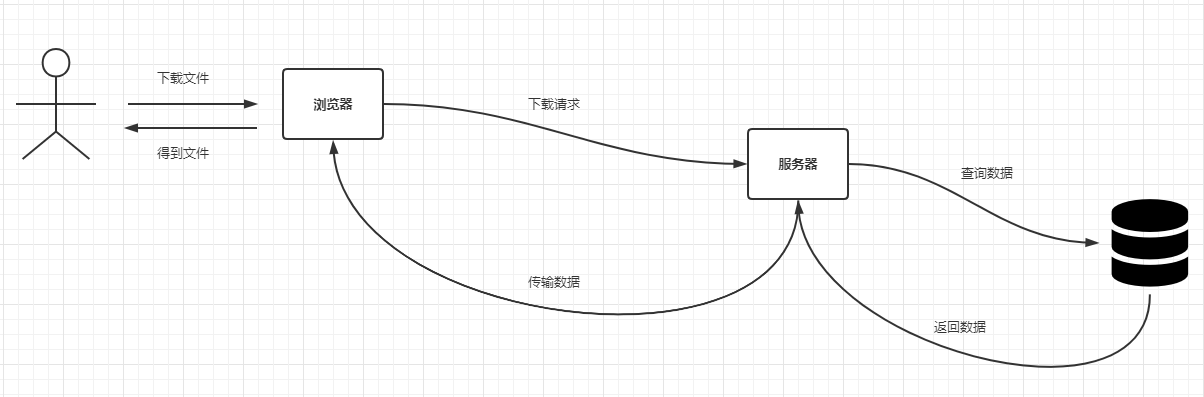
为了节省服务器的内存,这里的返回数据和数据传输部分可以设计为分段处理,也就是查询的时候考虑把查询全量的结果这个思路改变为每次只查询部分数据,直到得到全量的数据,每批次查询的结果数据都写进去OutputStream中。
这里以MySQL为例,可以使用类似于分页查询的思路,但是鉴于LIMIT offset,size的效率太低,结合之前的一些实践,采用了一种改良的"滚动翻页"的实现方式(这个方式是前公司的某个架构小组给出来的思路,后面广泛应用于各种批量查询、数据同步、数据导出以及数据迁移等等场景,这个思路肯定不是首创的,但是实用性十分高),注意这个方案要求表中包含一个有自增趋势的主键,单条查询SQL如下:
SELECT * FROM tableX WHERE id > #{lastBatchMaxId} [其他条件] ORDER BY id [ASC|DESC](这里一般选用ASC排序) LIMIT ${size}
把上面的SQL放进去前一个例子中,并且假设订单表使用了自增长整型主键id,那么上面的代码改造如下:
public void export(Parameter parameter, OutputStream os) throws IOException {
long lastBatchMaxId = 0L;
for (;;){
List<Order> orders = orderDao.query([SELECT * FROM t_order WHERE id > #{lastBatchMaxId}
AND payment_time >= #{parameter.paymentDateTimeStart} AND payment_time <= #{parameter.paymentDateTimeEnd} ORDER BY id ASC LIMIT ${LIMIT}]);
if (orders.isEmpty()){
break;
}
List<OrderDTO> result =
orderDao.query([SELECT * FROM t_order]).stream()
.map(order -> {
OrderDTO dto = new OrderDTO();
......
return dto;
}).collect(Collectors.toList());
byte[] bytes = toBytes(result);
os.write(bytes);
os.flush();
lastBatchMaxId = orders.stream().map(Order::getId).max(Long::compareTo).orElse(Long.MAX_VALUE);
}
os.close();
}
上面这个示例就是百万级别数据Excel导出优化的核心思路。查询和写入输出流的逻辑编写在一个死循环中,因为查询结果是使用了自增主键排序的,而属性lastBatchMaxId则存放了本次查询结果集中的最大id,同时它也是下一批查询的起始id,这样相当于基于id和查询条件向前滚动,直到查询条件不命中任何记录返回了空列表就会退出死循环。而limit字段则用于控制每批查询的记录数,可以按照应用实际分配的内存和每批次查询的数据量考量设计一个合理的值,这样就能让单个请求下常驻内存的对象数量控制在limit个从而使应用的内存使用更加可控,避免因为并发导出导致堆内存瞬间被打满。
这里的滚动翻页方案远比LIMIT offset,size效率高,因为此方案每次查询都是最终的结果集,而一般的分页方案使用的LIMIT offset,size需要先查询,后截断。
仿真案例
某个应用提供了查询订单和导出记录的功能,表设计如下:
DROP TABLE IF EXISTS `t_order`;
CREATE TABLE `t_order`
(
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
`creator` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '创建人',
`editor` VARCHAR(16) NOT NULL DEFAULT 'admin' COMMENT '修改人',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`edit_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
`version` BIGINT NOT NULL DEFAULT 1 COMMENT '版本号',
`deleted` TINYINT NOT NULL DEFAULT 0 COMMENT '软删除标识',
`order_id` VARCHAR(32) NOT NULL COMMENT '订单ID',
`amount` DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '订单金额',
`payment_time` DATETIME NOT NULL DEFAULT '1970-01-01 00:00:00' COMMENT '支付时间',
`order_status` TINYINT NOT NULL DEFAULT 0 COMMENT '订单状态,0:处理中,1:支付成功,2:支付失败',
UNIQUE uniq_order_id (`order_id`),
INDEX idx_payment_time (`payment_time`)
) COMMENT '订单表';
现在要基于支付时间段导出一批订单数据,先基于此需求编写一个简单的SpringBoot应用,这里的Excel处理工具选用Alibaba出品的EsayExcel,主要依赖如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>2.2.6</version>
</dependency>
模拟写入200W条数据,生成数据的测试类如下:
public class OrderServiceTest {
private static final Random OR = new Random();
private static final Random AR = new Random();
private static final Random DR = new Random();
@Test
public void testGenerateTestOrderSql() throws Exception {
HikariConfig config = new HikariConfig();
config.setUsername("root");
config.setPassword("root");
config.setJdbcUrl("jdbc:mysql://localhost:3306/local?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false");
config.setDriverClassName(Driver.class.getName());
HikariDataSource hikariDataSource = new HikariDataSource(config);
JdbcTemplate jdbcTemplate = new JdbcTemplate(hikariDataSource);
for (int d = 0; d < 100; d++) {
String item = "('%s','%d','2020-07-%d 00:00:00','%d')";
StringBuilder sql = new StringBuilder("INSERT INTO t_order(order_id,amount,payment_time,order_status) VALUES ");
for (int i = 0; i < 20_000; i++) {
sql.append(String.format(item, UUID.randomUUID().toString().replace("-", ""),
AR.nextInt(100000) + 1, DR.nextInt(31) + 1, OR.nextInt(3))).append(",");
}
jdbcTemplate.update(sql.substring(0, sql.lastIndexOf(",")));
}
hikariDataSource.close();
}
}
基于JdbcTemplate编写DAO类OrderDao:
@RequiredArgsConstructor
@Repository
public class OrderDao {
private final JdbcTemplate jdbcTemplate;
public List<Order> queryByScrollingPagination(long lastBatchMaxId,
int limit,
LocalDateTime paymentDateTimeStart,
LocalDateTime paymentDateTimeEnd) {
return jdbcTemplate.query("SELECT * FROM t_order WHERE id > ? AND payment_time >= ? AND payment_time <= ? " +
"ORDER BY id ASC LIMIT ?",
p -> {
p.setLong(1, lastBatchMaxId);
p.setTimestamp(2, Timestamp.valueOf(paymentDateTimeStart));
p.setTimestamp(3, Timestamp.valueOf(paymentDateTimeEnd));
p.setInt(4, limit);
},
rs -> {
List<Order> orders = new ArrayList<>();
while (rs.next()) {
Order order = new Order();
order.setId(rs.getLong("id"));
order.setCreator(rs.getString("creator"));
order.setEditor(rs.getString("editor"));
order.setCreateTime(OffsetDateTime.ofInstant(rs.getTimestamp("create_time").toInstant(), ZoneId.systemDefault()));
order.setEditTime(OffsetDateTime.ofInstant(rs.getTimestamp("edit_time").toInstant(), ZoneId.systemDefault()));
order.setVersion(rs.getLong("version"));
order.setDeleted(rs.getInt("deleted"));
order.setOrderId(rs.getString("order_id"));
order.setAmount(rs.getBigDecimal("amount"));
order.setPaymentTime(OffsetDateTime.ofInstant(rs.getTimestamp("payment_time").toInstant(), ZoneId.systemDefault()));
order.setOrderStatus(rs.getInt("order_status"));
orders.add(order);
}
return orders;
});
}
}
编写服务类OrderService:
@Data
public class OrderDTO {
@ExcelIgnore
private Long id;
@ExcelProperty(value = "订单号", order = 1)
private String orderId;
@ExcelProperty(value = "金额", order = 2)
private BigDecimal amount;
@ExcelProperty(value = "支付时间", order = 3)
private String paymentTime;
@ExcelProperty(value = "订单状态", order = 4)
private String orderStatus;
}
@Service
@RequiredArgsConstructor
public class OrderService {
private final OrderDao orderDao;
private static final DateTimeFormatter F = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
public List<OrderDTO> queryByScrollingPagination(String paymentDateTimeStart,
String paymentDateTimeEnd,
long lastBatchMaxId,
int limit) {
LocalDateTime start = LocalDateTime.parse(paymentDateTimeStart, F);
LocalDateTime end = LocalDateTime.parse(paymentDateTimeEnd, F);
return orderDao.queryByScrollingPagination(lastBatchMaxId, limit, start, end).stream().map(order -> {
OrderDTO dto = new OrderDTO();
dto.setId(order.getId());
dto.setAmount(order.getAmount());
dto.setOrderId(order.getOrderId());
dto.setPaymentTime(order.getPaymentTime().format(F));
dto.setOrderStatus(OrderStatus.fromStatus(order.getOrderStatus()).getDescription());
return dto;
}).collect(Collectors.toList());
}
}
最后编写控制器OrderController:
@RequiredArgsConstructor
@RestController
@RequestMapping(path = "/order")
public class OrderController {
private final OrderService orderService;
@GetMapping(path = "/export")
public void export(@RequestParam(name = "paymentDateTimeStart") String paymentDateTimeStart,
@RequestParam(name = "paymentDateTimeEnd") String paymentDateTimeEnd,
HttpServletResponse response) throws Exception {
String fileName = URLEncoder.encode(String.format("%s-(%s).xlsx", "订单支付数据", UUID.randomUUID().toString()),
StandardCharsets.UTF_8.toString());
response.setContentType("application/force-download");
response.setHeader("Content-Disposition", "attachment;filename=" + fileName);
ExcelWriter writer = new ExcelWriterBuilder()
.autoCloseStream(true)
.excelType(ExcelTypeEnum.XLSX)
.file(response.getOutputStream())
.head(OrderDTO.class)
.build();
// xlsx文件上上限是104W行左右,这里如果超过104W需要分Sheet
WriteSheet writeSheet = new WriteSheet();
writeSheet.setSheetName("target");
long lastBatchMaxId = 0L;
int limit = 500;
for (; ; ) {
List<OrderDTO> list = orderService.queryByScrollingPagination(paymentDateTimeStart, paymentDateTimeEnd, lastBatchMaxId, limit);
if (list.isEmpty()) {
writer.finish();
break;
} else {
lastBatchMaxId = list.stream().map(OrderDTO::getId).max(Long::compareTo).orElse(Long.MAX_VALUE);
writer.write(list, writeSheet);
}
}
}
}
这里为了方便,把一部分业务逻辑代码放在控制器层编写,实际上这是不规范的编码习惯,这一点不要效仿。添加配置和启动类之后,通过请求http://localhost:10086/order/export?paymentDateTimeStart=2020-07-01 00:00:00&paymentDateTimeEnd=2020-07-16 00:00:00测试导出接口,某次导出操作后台输出日志如下:
导出数据耗时:29733 ms,start:2020-07-01 00:00:00,end:2020-07-16 00:00:00
导出成功后得到一个文件(连同表头一共1031540行):
小结
这篇文章详细地分析大数据量导出的性能优化,最要侧重于内存优化。该方案实现了在尽可能少占用内存的前提下,在效率可以接受的范围内进行大批量的数据导出。这是一个可复用的方案,类似的设计思路也可以应用于其他领域或者场景,不局限于数据导出。
文中demo项目的仓库地址是:
(本文完 c-2-d e-a-20200711 20:27 PM)
技术公众号《Throwable文摘》(id:throwable-doge),不定期推送笔者原创技术文章(绝不抄袭或者转载):
![]()