SPring的涉及模式
- 单例模式:Spring 中的 Bean 默认情况下都是单例的。
- 工厂模式:工厂模式主要是通过 BeanFactory 和 ApplicationContext 来生产 Bean 对象。
- 代理模式:最常见的 AOP 的实现方式就是通过代理来实现,Spring主要是使用 JDK 动态代理和 CGLIB 代理。
- 模板方法模式:主要是一些对数据库操作的类用到,比如 JdbcTemplate、JpaTemplate,因为查询数据库的建立连接、执行查询、关闭连接几个过程,非常适用于模板方法。
IOC 和 AOP 的理解
IOC 叫做控制反转,指的是通过Spring来管理对象的创建、配置和生命周期,这样相当于把控制权交给了Spring,不需要人工来管理对象之间复杂的依赖关系,这样做的好处就是解耦。在Spring里面,主要提供了 BeanFactory 和 ApplicationContext 两种 IOC 容器,通过他们来实现对 Bean 的管理。
AOP 叫做面向切面编程,他是一个编程范式,目的就是提高代码的模块性。Spring AOP 基于动态代理的方式实现,如果是实现了接口的话就会使用 JDK 动态代理,反之则使用 CGLIB 代理,Spring中 AOP 的应用主要体现在 事务、日志、异常处理等方面,通过在代码的前后做一些增强处理,可以实现对业务逻辑的隔离,提高代码的模块化能力,同时也是解耦。Spring主要提供了 Aspect 切面、JoinPoint 连接点、PointCut 切入点、Advice 增强等实现方式。
JDK 动态代理和 CGLIB 代理
JDK 动态代理主要是针对类实现了某个接口,AOP 则会使用 JDK 动态代理。他基于反射的机制实现,生成一个实现同样接口的一个代理类,然后通过重写方法的方式,实现对代码的增强。
而如果某个类没有实现接口,AOP 则会使用 CGLIB 代理。他的底层原理是基于 asm 第三方框架,通过修改字节码生成成成一个子类,然后重写父类的方法,实现对代码的增强。
Spring AOP 和 AspectJ AOP
Spring AOP 基于动态代理实现,属于运行时增强。
AspectJ 则属于编译时增强,主要有3种方式:
- 编译时织入:指的是增强的代码和源代码我们都有,直接使用 AspectJ 编译器编译就行了,编译之后生成一个新的类,他也会作为一个正常的 Java 类装载到JVM。
- 编译后织入:指的是代码已经被编译成 class 文件或者已经打成 jar 包,这时候要增强的话,就是编译后织入,比如你依赖了第三方的类库,又想对他增强的话,就可以通过这种方式。
- 加载时织入:指的是在 JVM 加载类的时候进行织入。
总结下来的话,就是 Spring AOP 只能在运行时织入,不需要单独编译,性能相比 AspectJ 编译织入的方式慢,而 AspectJ 只支持编译前后和类加载时织入,性能更好,功能更加强大。
SpringBean的生命周期
SpringBean 生命周期简单概括为4个阶段:
- 实例化 Instantiation ==> 创建一个Bean对象
- 属性赋值 Populate
- 初始化 Initialization
- 如果实现了xxxAware接口,通过不同类型的Aware接口拿到Spring容器的资源
- 如果实现了BeanPostProcessor接口,则会回调该接口的postProcessBeforeInitialzation和postProcessAfterInitialization方法
- 如果配置了init-method方法,则会执行init-method配置的方法
- 销毁 Destruction
- 容器关闭后,如果Bean实现了DisposableBean接口,则会回调该接口的destroy方法
- 如果配置了destroy-method方法,则会执行destroy-method配置的方法

FactoryBean 和 BeanFactory
BeanFactory 是 Bean 的工厂, ApplicationContext 的父类,IOC 容器的核心,负责生产和管理 Bean 对象。
FactoryBean 是 Bean,可以通过实现 FactoryBean 接口定制实例化 Bean 的逻辑,通过代理一个Bean对象,对方法前后做一些操作。
Spring循环依赖
三级缓存
Spring事务传播机制
- PROPAGATION_REQUIRED:如果当前没有事务,就创建一个新事务,如果当前存在事务,就加入该事务,这也是通常我们的默认选择。
- PROPAGATION_REQUIRES_NEW:创建新事务,无论当前存不存在事务,都创建新事务。
- PROPAGATION_NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
- PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。
- PROPAGATION_MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
- PROPAGATION_SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就以非事务执行。
@Transactional错误使用失效场景
- @Transactional 在private上:当标记在protected、private、package-visible方法上时,不会产生错误,但也不会表现出为它指定的事务配置。可以认为它作为一个普通的方法参与到一个public方法的事务中。
- @Transactional 的事务传播方式配置错误。
- @Transactional 注解属性 rollbackFor 设置错误:Spring默认抛出了未检查unchecked异常(继承自 RuntimeException 的异常)或者 Error才回滚事务;其他异常不会触发回滚事务。
- 同一个类中方法调用,导致@Transactional失效:由于使用Spring AOP代理造成的,因为只有当事务方法被当前类以外的代码调用时,才会由Spring生成的代理对象来管理。
- 异常被 catch 捕获导致@Transactional失效。
- 数据库引擎不支持事务
Spring Boot 启动流程
- 准备环境,根据不同的环境创建不同的Environment
- 准备、加载上下文,为不同的环境选择不同的Spring Context,然后加载资源,配置Bean
- 初始化,这个阶段刷新Spring Context,启动应用
- 结束流程
Spring的后置处理器
- BeanPostProcessor:Bean的后置处理器,主要在bean初始化前后工作。(before和after两个回调中间只处理了init-method)
- InstantiationAwareBeanPostProcessor:继承于BeanPostProcessor,主要在实例化bean前后工作(TargetSource的AOP创建代理对象就是通过该接口实现)
- BeanFactoryPostProcessor:Bean工厂的后置处理器,在bean定义(bean definitions)加载完成后,bean尚未初始化前执行。
- BeanDefinitionRegistryPostProcessor:继承于BeanFactoryPostProcessor。其自定义的方法postProcessBeanDefinitionRegistry会在bean定义(bean definitions)将要加载,bean尚未初始化前真执行,即在BeanFactoryPostProcessor的postProcessBeanFactory方法前被调用。
@Resource和@Autowired
@Autowired按byType自动注入,而@Resource默认按 byName自动注入
Eureka基本原理
服务启动后向Eureka注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,以证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
Eureka的自我保护机制
在默认配置中,Eureka Server在默认90s没有得到客户端的心跳,则注销该实例,但是往往因为微服务跨进程调用,网络通信往往会面临着各种问题,比如微服务状态正常,但是因为网络分区故障时,Eureka Server注销服务实例则会让大部分微服务不可用,这很危险,因为服务明明没有问题。
为了解决这个问题,Eureka 有自我保护机制,通过在Eureka Server配置eureka.server.enable-self-preservation=true,可启动保护机制,原理是,当Eureka Server节点在短时间内丢失过多的客户端时(可能发送了网络故障),那么这个节点将进入自我保护模式,不再注销任何微服务,当网络故障回复后,该节点会自动退出自我保护模式。
Eureka与Zookeeper的区别
CAP理论指出,一个分布式系统不可能同时满足C(一致性)、A(可用性)和P(分区容错性)。由于分区容错性P在是分布式系统中必须要保证的,因此我们只能在A和C之间进行权衡。
Zookeeper保证CP
Zookeeper 为主从结构,有leader节点和follow节点。当leader节点down掉之后,剩余节点会重新进行选举。选举过程中会导致服务不可用,丢掉了可用行。
Eureka保证CP
Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册或时如果发现连接失败,则会自动切换至其它节点,只要有一台Eureka还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
Hystrix的工作原理
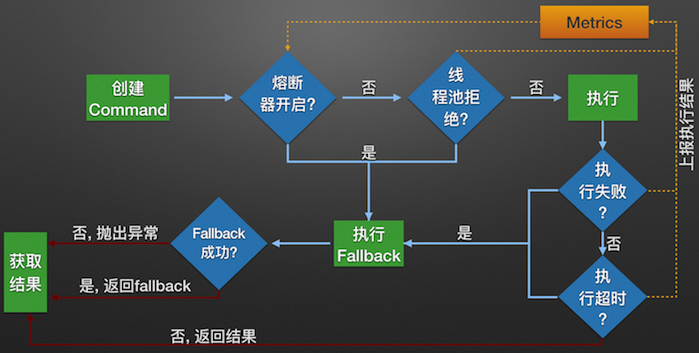
Hystrix如何实现容错
- 包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立的线程中执行,使用了设计模式中的“命令模式”;
- 跳闸机制:当某服务的错误率超过一定阈值时,Hystrix可以自动或者手动跳闸,停止请求该服务一段时间;
- 资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程已满,则发向该依赖的请求就会被立即拒绝,而不是排队等候,从而加速失败判定;
- 监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等;
- 回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑,回退逻辑由开发人员自行提供,如返回一个缺省值;
- 自我修复:断路器打开一段时间后,会自动进入“半开”状态,此时断路器可允许一个请求访问依赖的服务,若请求成功,则断路器关闭,否则断路器转为“打开”状态;
pring如何解决循环依赖问题
- 第一级缓存:单例缓存池 singletonObjects。
- 第二级缓存:早期提前暴露的对象缓存 earlySingletonObjects。也就是还没赋值的
- 第三级缓存:singletonFactories 单例对象工厂缓存
Spring使用了三级缓存解决了循环依赖的问题。在populateBean()给属性赋值阶段里面Spring会解析你的属性,并且赋值,当发现,A对象里面依赖了B,此时又会走getBean方法,但这个时候,你去缓存中是可以拿的到的。因为我们在对createBeanInstance对象创建完成以后已经放入了缓存当中,所以创建B的时候发现依赖A,直接就从缓存中去拿,此时B创建完,A也创建完,一共执行了4次。至此Bean的创建完成,最后将创建好的Bean放入单例缓存池中。
细节:[AB 互相引用 第一次加载A放入缓存 然后赋值发现B并加载赋值发现A这时候因为多级缓存的加载关系,会去缓存里拿到A不会循环加载]
- 使用context.getBean(A.class),旨在获取容器内的单例A(若A不存在,就会走A这个Bean的创建流程),显然初次获取A是不存在的,因此走A的创建之路~
- 实例化A(注意此处仅仅是实例化),并将它放进缓存(此时A已经实例化完成,已经可以被引用了)
- 初始化A:@Autowired依赖注入B(此时需要去容器内获取B)
- 为了完成依赖注入B,会通过getBean(B)去容器内找B。但此时B在容器内不存在,就走向B的创建之路~
- 实例化B,并将其放入缓存。(此时B也能够被引用了)
- 初始化B,@Autowired依赖注入A(此时需要去容器内获取A)
- 此处重要:初始化B时会调用getBean(A)去容器内找到A,上面我们已经说过了此时候因为A已经实例化完成了并且放进了缓存里,所以这个时候去看缓存里是已经存在A的引用了的,所以getBean(A)能够正常返回
- B初始化成功(此时已经注入A成功了,已成功持有A的引用了),return(注意此处return相当于是返回最上面的getBean(B)这句代码,回到了初始化A的流程中~)。
- 因为B实例已经成功返回了,因此最终A也初始化成功
- 到此,B持有的已经是初始化完成的A,A持有的也是初始化完成的B,完美~
AOP 动态代理
- JDK动态代理:[对实现了接口的类生成代理,而不能针对类] 利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
- CGlib动态代理:[类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法(继承)]利用ASM(开源的Java字节码编辑库,操作字节码)开源包,将代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
Spring在选择用JDK还是CGLiB
-
当Bean实现接口时,Spring就会用JDK的动态代理
-
当Bean没有实现接口时,Spring使用CGlib是实现
-
可以强制使用CGlib(在spring配置中加入<aop:aspectj-autoproxy proxy-target-class="true"/>)
区别:
JDK代理只能对实现接口的类生成代理;CGlib是针对类实现代理,对指定的类生成一个子类,并覆盖其中的方法,这种通过继承类的实现方式,不能代理final修饰的类。
使用CGLib实现动态代理,CGLib底层采用ASM字节码生成框架,使用字节码技术生成代理类,比使用Java反射效率要高。唯一需要注意的是,CGLib不能对声明为final的方法进行代理,因为CGLib原理是动态生成被代理类的子类。
SpringBoot的启动流程
Springboot的几种加载方式的异同
多线程类型面试题 同时并发启动10个线程